kejian/ACL-ARC
收藏Hugging Face2023-11-02 更新2024-03-04 收录
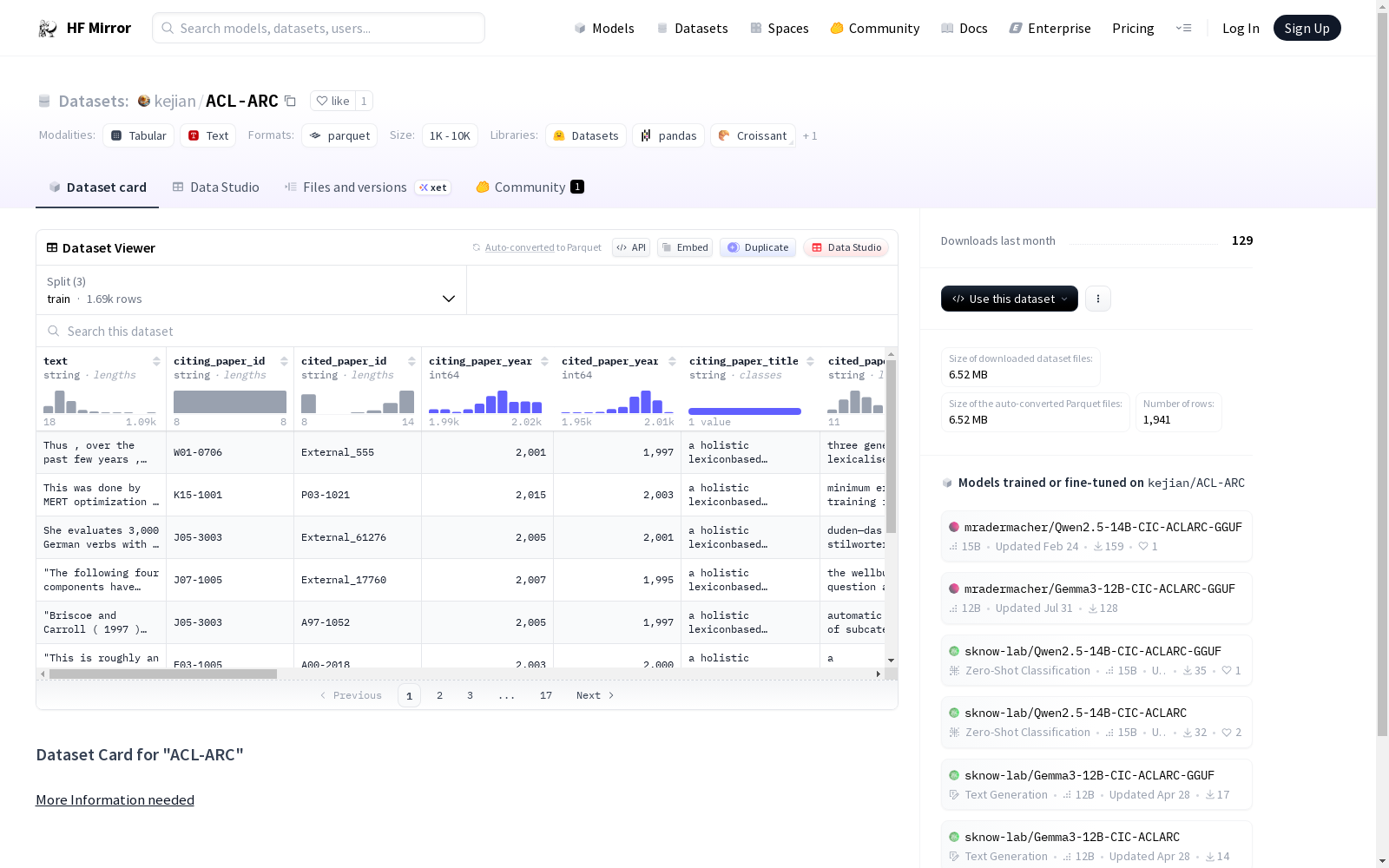
下载链接:
https://hf-mirror.com/datasets/kejian/ACL-ARC
下载链接
链接失效反馈官方服务:
资源简介:
---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: text
dtype: string
- name: citing_paper_id
dtype: string
- name: cited_paper_id
dtype: string
- name: citing_paper_year
dtype: int64
- name: cited_paper_year
dtype: int64
- name: citing_paper_title
dtype: string
- name: cited_paper_title
dtype: string
- name: cited_author_ids
sequence: string
- name: citing_author_ids
dtype: 'null'
- name: extended_context
dtype: string
- name: section_number
dtype: int64
- name: section_title
dtype: 'null'
- name: intent
dtype: string
- name: cite_marker_offset
sequence: int64
- name: sents_before
list:
list:
- name: index
dtype: int64
- name: word
dtype: string
- name: lemma
dtype: string
- name: after
dtype: string
- name: pos
dtype: string
- name: characterOffsetEnd
dtype: int64
- name: segment_span
sequence: int64
- name: characterOffsetBegin
dtype: int64
- name: originalText
dtype: string
- name: ArgType
dtype: string
- name: before
dtype: string
- name: is_root
dtype: bool
- name: tense
dtype: string
- name: has_aux
dtype: bool
- name: is_pass
dtype: bool
- name: sents_after
list:
list:
- name: index
dtype: int64
- name: word
dtype: string
- name: lemma
dtype: string
- name: after
dtype: string
- name: pos
dtype: string
- name: characterOffsetEnd
dtype: int64
- name: segment_span
sequence: int64
- name: characterOffsetBegin
dtype: int64
- name: originalText
dtype: string
- name: ArgType
dtype: string
- name: before
dtype: string
- name: is_root
dtype: bool
- name: tense
dtype: string
- name: is_pass
dtype: bool
- name: has_aux
dtype: bool
- name: cleaned_cite_text
dtype: string
- name: citation_id
dtype: string
- name: citation_excerpt_index
dtype: int64
- name: section_name
dtype: string
splits:
- name: train
num_bytes: 32094179
num_examples: 1688
- name: test
num_bytes: 2705971
num_examples: 139
- name: validation
num_bytes: 2095387
num_examples: 114
download_size: 6517047
dataset_size: 36895537
---
# Dataset Card for "ACL-ARC"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
配置项:
- 配置名称:default
数据文件:
- 数据集划分(split):train,路径:data/train-*
- 数据集划分(split):test,路径:data/test-*
- 数据集划分(split):validation,路径:data/validation-*
数据集信息(dataset_info):
特征列表:
- 文本(text):数据类型为字符串(string)
- 引用论文ID(citing_paper_id):数据类型为字符串(string)
- 被引论文ID(cited_paper_id):数据类型为字符串(string)
- 引用论文发表年份(citing_paper_year):数据类型为64位整数(int64)
- 被引论文发表年份(cited_paper_year):数据类型为64位整数(int64)
- 引用论文标题(citing_paper_title):数据类型为字符串(string)
- 被引论文标题(cited_paper_title):数据类型为字符串(string)
- 被引作者ID序列(cited_author_ids):数据类型为字符串序列(sequence<string>)
- 引用作者ID(citing_author_ids):数据类型为空(null)
- 扩展上下文(extended_context):数据类型为字符串(string)
- 章节编号(section_number):数据类型为64位整数(int64)
- 章节标题(section_title):数据类型为空(null)
- 意图(intent):数据类型为字符串(string)
- 引用标记偏移量(cite_marker_offset):数据类型为整数序列(sequence<int64>)
- 前文语句集(sents_before):列表类型,其元素为嵌套列表,包含以下字段:
- 索引(index):64位整数(int64)
- 单词(word):字符串(string)
- 词形还原形式(lemma):字符串(string)
- 后置上下文(after):字符串(string)
- 词性标注(pos):字符串(string)
- 字符偏移结束位置(characterOffsetEnd):64位整数(int64)
- 片段跨度(segment_span):整数序列(sequence<int64>)
- 字符偏移起始位置(characterOffsetBegin):64位整数(int64)
- 原始文本(originalText):字符串(string)
- 参数类型(ArgType):字符串(string)
- 前置上下文(before):字符串(string)
- 是否为根节点(is_root):布尔型(bool)
- 时态(tense):字符串(string)
- 是否有助动词(has_aux):布尔型(bool)
- 是否为被动语态(is_pass):布尔型(bool)
- 后文语句集(sents_after):列表类型,其元素为嵌套列表,包含以下字段:
- 索引(index):64位整数(int64)
- 单词(word):字符串(string)
- 词形还原形式(lemma):字符串(string)
- 后置上下文(after):字符串(string)
- 词性标注(pos):字符串(string)
- 字符偏移结束位置(characterOffsetEnd):64位整数(int64)
- 片段跨度(segment_span):整数序列(sequence<int64>)
- 字符偏移起始位置(characterOffsetBegin):64位整数(int64)
- 原始文本(originalText):字符串(string)
- 参数类型(ArgType):字符串(string)
- 前置上下文(before):字符串(string)
- 是否为根节点(is_root):布尔型(bool)
- 时态(tense):字符串(string)
- 是否为被动语态(is_pass):布尔型(bool)
- 是否有助动词(has_aux):布尔型(bool)
- 清理后的引用文本(cleaned_cite_text):数据类型为字符串(string)
- 引用ID(citation_id):数据类型为字符串(string)
- 引用摘录索引(citation_excerpt_index):数据类型为64位整数(int64)
- 章节名称(section_name):数据类型为字符串(string)
数据集划分列表(splits):
- 名称:train(训练集),字节大小:32094179,样本数量:1688
- 名称:test(测试集),字节大小:2705971,样本数量:139
- 名称:validation(验证集),字节大小:2095387,样本数量:114
下载大小:6517047 字节
数据集总大小:36895537 字节
---
# "ACL-ARC"数据集卡片
[需补充更多信息](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
提供机构:
kejian
原始信息汇总
数据集概述
数据集配置
- 默认配置:
- 训练集:路径为
data/train-* - 测试集:路径为
data/test-* - 验证集:路径为
data/validation-*
- 训练集:路径为
数据集信息
- 特征列表:
- text:文本,数据类型为
string - citing_paper_id:引用论文ID,数据类型为
string - cited_paper_id:被引用论文ID,数据类型为
string - citing_paper_year:引用论文年份,数据类型为
int64 - cited_paper_year:被引用论文年份,数据类型为
int64 - citing_paper_title:引用论文标题,数据类型为
string - cited_paper_title:被引用论文标题,数据类型为
string - cited_author_ids:被引用作者ID序列,数据类型为
string - citing_author_ids:引用作者ID,数据类型为
null - extended_context:扩展上下文,数据类型为
string - section_number:章节编号,数据类型为
int64 - section_title:章节标题,数据类型为
null - intent:意图,数据类型为
string - cite_marker_offset:引用标记偏移量,数据类型为
int64序列 - sents_before:引用前句子列表,包含以下子特征:
- index:索引,数据类型为
int64 - word:单词,数据类型为
string - lemma:词元,数据类型为
string - after:单词后的内容,数据类型为
string - pos:词性,数据类型为
string - characterOffsetEnd:字符偏移结束,数据类型为
int64 - segment_span:段落跨度,数据类型为
int64序列 - characterOffsetBegin:字符偏移开始,数据类型为
int64 - originalText:原始文本,数据类型为
string - ArgType:参数类型,数据类型为
string - before:单词前的内容,数据类型为
string - is_root:是否为根节点,数据类型为
bool - tense:时态,数据类型为
string - has_aux:是否有辅助词,数据类型为
bool - is_pass:是否为被动语态,数据类型为
bool
- index:索引,数据类型为
- sents_after:引用后句子列表,包含以下子特征:
- index:索引,数据类型为
int64 - word:单词,数据类型为
string - lemma:词元,数据类型为
string - after:单词后的内容,数据类型为
string - pos:词性,数据类型为
string - characterOffsetEnd:字符偏移结束,数据类型为
int64 - segment_span:段落跨度,数据类型为
int64序列 - characterOffsetBegin:字符偏移开始,数据类型为
int64 - originalText:原始文本,数据类型为
string - ArgType:参数类型,数据类型为
string - before:单词前的内容,数据类型为
string - is_root:是否为根节点,数据类型为
bool - tense:时态,数据类型为
string - is_pass:是否为被动语态,数据类型为
bool - has_aux:是否有辅助词,数据类型为
bool
- index:索引,数据类型为
- cleaned_cite_text:清洗后的引用文本,数据类型为
string - citation_id:引用ID,数据类型为
string - citation_excerpt_index:引用摘录索引,数据类型为
int64 - section_name:章节名称,数据类型为
string
- text:文本,数据类型为
数据集分割
- 训练集:
- 字节数:32094179
- 样本数:1688
- 测试集:
- 字节数:2705971
- 样本数:139
- 验证集:
- 字节数:2095387
- 样本数:114
数据集大小
- 下载大小:6517047 字节
- 数据集大小:36895537 字节
搜集汇总
数据集介绍
构建方式
在计算语言学的学术文献分析领域,ACL-ARC数据集通过系统化地提取ACL Anthology中的引文信息构建而成。该数据集从学术论文中精准抽取引文上下文,涵盖引用文本、相关论文标识、发表年份及作者信息等结构化字段。构建过程整合了引文标记的偏移位置、前后句子的语法解析数据,以及章节编号与意图分类,确保了数据在学术引用分析中的深度与广度。
特点
ACL-ARC数据集以其丰富的语言学标注和结构化引文信息而著称。数据集不仅包含基础的引文文本与论文元数据,还提供了句子级别的语法特征,如词性标注、时态分析和句法角色。这些特征辅以引文意图标签和章节上下文,为研究学术写作中的引用行为与语言模式提供了多维度的分析视角。
使用方法
该数据集适用于自然语言处理任务,特别是引文意图分类、学术文本挖掘和上下文感知的引用分析。研究人员可加载训练、验证和测试分割,利用文本字段与语言学特征构建模型。通过引文标识与论文元数据的关联,能够深入探索学术网络中的引用动态与知识传播模式。
背景与挑战
背景概述
在计算语言学和学术文献分析领域,引文意图识别是理解科学交流动态的核心任务。ACL-ARC数据集由相关研究团队构建,旨在深入探究学术论文中引用行为背后的具体意图。该数据集聚焦于计算语言学领域的文献,通过精细标注引文上下文,揭示了作者引用他人工作的多种动机,如对比方法、支持主张或指出不足。其创建推动了引文分析从简单计数向语义理解的转变,为自动化学术评价和知识图谱构建提供了关键数据基础,显著提升了领域内对科学论证结构的认知深度。
当前挑战
引文意图识别面临的核心挑战在于准确捕捉和分类作者引用文献的复杂动机,这些动机往往隐含在微妙的语言表达中。具体而言,模型需区分诸如“背景铺垫”、“方法比较”、“结果支持”等精细类别,这对自然语言理解的语义粒度提出了极高要求。在数据集构建过程中,挑战主要源于标注一致性:不同标注者对同一引文意图的解读可能存在主观差异,且引文上下文通常包含专业术语和复杂句式,增加了人工标注的难度和成本。此外,确保数据覆盖不同子领域和出版年份的多样性,以避免模型偏差,亦是构建中的关键难题。
常用场景
经典使用场景
在计算语言学和信息检索领域,ACL-ARC数据集为学术文献的引用意图分类提供了关键资源。该数据集通过标注引用上下文及其意图类别,如背景比较或方法使用,支持研究者训练模型以自动识别引用的深层目的。这一过程不仅深化了对学术交流模式的理解,还为构建智能文献分析系统奠定了数据基础。
解决学术问题
该数据集有效应对了学术文本挖掘中的核心挑战,即如何从海量文献中自动解析引用行为的功能与动机。通过提供结构化的引用上下文和意图标签,它助力解决引用网络分析、学术影响力评估以及知识演化追踪等问题。其意义在于推动了细粒度学术文本理解技术的发展,为科学计量学和数字图书馆学提供了实证支持。
衍生相关工作
围绕ACL-ARC数据集,衍生了一系列经典研究工作,包括基于深度学习的引用意图分类模型和跨领域引用行为对比分析。这些工作不仅扩展了数据集的适用边界,还催生了新的评估基准与算法框架。后续研究进一步探索了多语言引用理解与生成任务,持续丰富着学术文本处理的生态体系。
以上内容由遇见数据集搜集并总结生成


