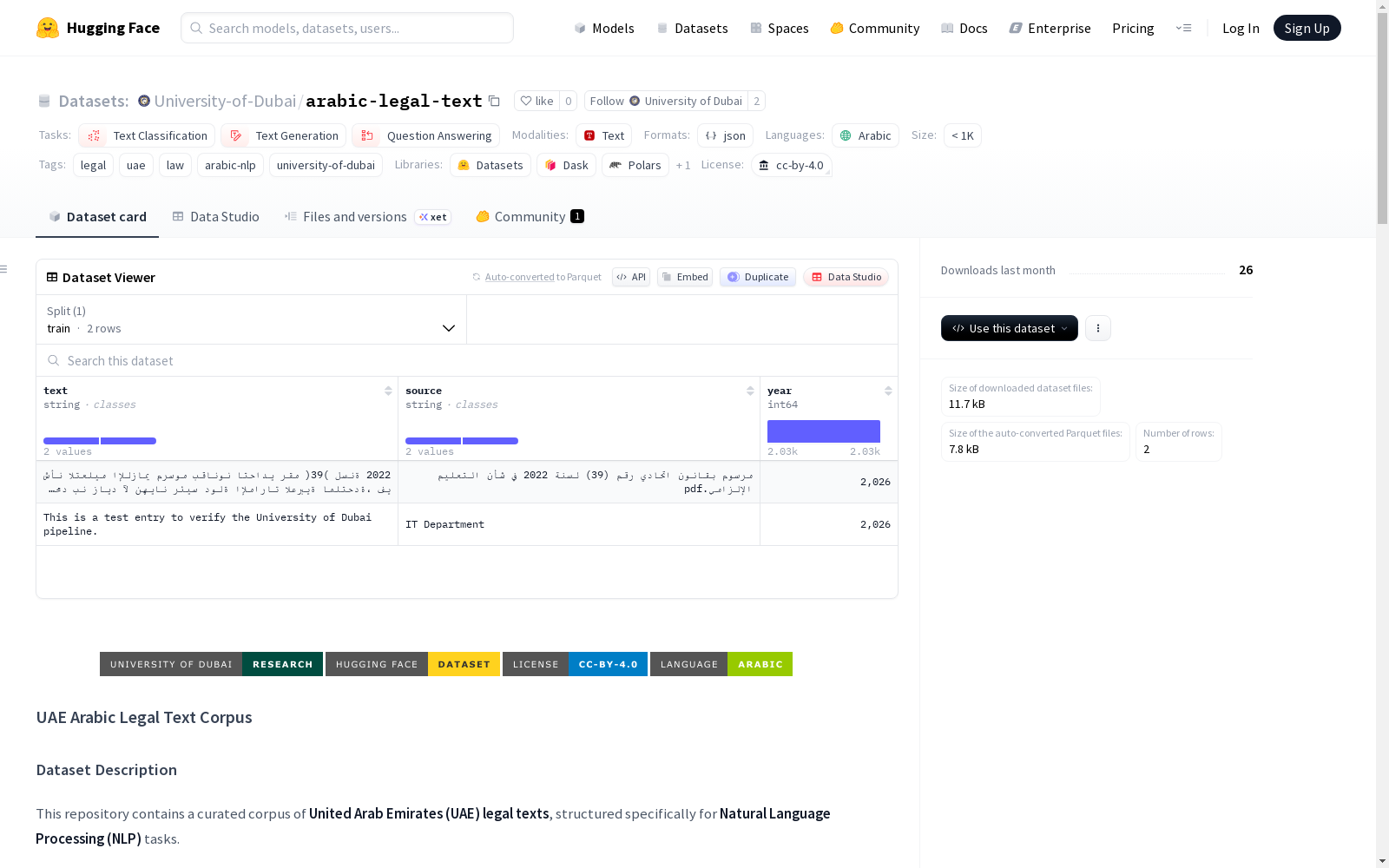
arabic-legal-text
收藏UAE阿拉伯语法律文本语料库数据集概述
数据集基本信息
- 数据集名称:UAE Arabic Legal Text Corpus
- 维护者:Mohamed Asath (BuildingTHEITGUY) 与 University of Dubai Research
- 语言:阿拉伯语(现代标准阿拉伯语/法律阿拉伯语)
- 许可证:Creative Commons Attribution 4.0 (CC BY 4.0)
- 发布年份:2026年
- 数据规模:小于1K样本
- 存储库地址:https://github.com/University-of-Dubai-Research/arabic-legal-text
- Hugging Face数据集地址:https://huggingface.co/datasets/University-of-Dubai/arabic-legal-text
数据集描述
该数据集包含一个经过整理的阿拉伯联合酋长国(UAE)法律文本语料库,专门为自然语言处理(NLP)任务而构建。由迪拜大学研究部维护,旨在支持以下领域的研究:
- 阿拉伯语法律智能
- 自动摘要
- 检索增强生成(RAG)
- 法律信息系统
支持的任务类别
- 文本分类
- 文本生成
- 问答
- 法律文本分类(将文本分类为民事、刑事、商业、劳工、网络安全等类别)
- 法律信息检索(为阿联酋法律构建搜索和语义检索系统)
- 语言建模(在特定领域的阿拉伯语法律术语上微调大语言模型)
数据集结构
- 数据格式:JSON Lines (JSONL)
- 数据分割:训练集(train)
- 数据文件路径模式:
data/*.jsonl
数据字段
每个JSON行代表一个独立的法律条款或规定,包含以下字段:
text:法律条款或规定的完整内容source:法律或法令的名称year:颁布年份category:法律领域(例如:网络安全、刑法、劳动法)
数据实例示例
json { "text": "تسري أحكام هذا القانون على جرائم تقنية المعلومات...", "source": "UAE Federal Decree-Law No. 34 on Rumors and Cybercrimes", "category": "Cybersecurity", "year": 2026 }
使用方法
可以直接使用Hugging Face的datasets库在Python中加载此数据集: python from datasets import load_dataset dataset = load_dataset("University-of-Dubai/arabic-legal-text")
引用方式
如果在研究或学术工作中使用此数据集,请按以下格式引用: bibtex @dataset{university_of_dubai_arabic_legal_2026, author = {Asath, Mohamed and University of Dubai}, title = {UAE Arabic Legal Text Corpus}, year = {2026}, publisher = {Hugging Face}, url = {https://huggingface.co/datasets/University-of-Dubai/arabic-legal-text} }
贡献与管理
- 该数据集通过GitHub进行管理,以确保版本控制和学术完整性。
- 教职员工/研究人员:请将数据更新推送到GitHub存储库。
- 自动化:GitHub上的更改会自动验证并同步到Hugging Face。
贡献者
- Mohamed Asath(主要维护者)