align-anything-400K
收藏Hugging Face2024-10-12 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/PKU-Alignment/align-anything-400K
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含多个配置,专注于不同类型的数据交互,如文本到视频、文本到图像、文本到音频等。每个配置详细列出了特定的特征,如提示、响应、模型以及各种评估指标(例如,提示遵循率、清晰度率、安全性率)。数据集包括文本到音频和文本到图像的配置,这些配置更为详细,并提及了分割和大小。
This dataset comprises multiple configurations focused on diverse types of data interactions, such as text-to-video, text-to-image, text-to-audio, and more. Each configuration details specific characteristics including prompts, responses, models, and a range of evaluation metrics (e.g., prompt adherence rate, clarity rate, safety rate). The dataset includes text-to-audio and text-to-image configurations, which are more detailed and provide information about data splits and dataset sizes.
提供机构:
PKU-Alignment
创建时间:
2024-09-28
原始信息汇总
数据集概述
数据集名称
- PKU-Alignment/align-anything-400K
数据集配置
配置名称:example_tv2t
- 特征:
- prompt: string
- video_path: string
- response_1: string
- response_2: string
- model_1: string
- model_2: string
- p_response: int64
- prompt_following_rate_1: int64
- prompt_following_rate_2: int64
- p_rationale_1: string
- p_rationale_2: string
- o_response: int64
- objective_rules_rate_1: int64
- objective_rules_rate_2: int64
- o_rationale_1: string
- o_rationale_2: string
- c_response: int64
- clarity_rate_1: int64
- clarity_rate_2: int64
- c_rationale_1: string
- c_rationale_2: string
- i_response: int64
- information_richness_rate_1: int64
- information_richness_rate_2: int64
- i_rationale_1: string
- i_rationale_2: string
- s_response: int64
- safety_rate_1: int64
- safety_rate_2: int64
- s_rationale_1: string
- s_rationale_2: string
- text_critique_1: string
- text_critique_2: string
- overall_response: int64
- overall_textfeedback: string
- 分割:
- example
配置名称:example_ti2t
- 特征:
- question: string
- image: image
- response_1: string
- response_2: string
- res_1_from: string
- res_2_from: string
- p_response: int64
- prompt_following_rate_1: int64
- prompt_following_rate_2: int64
- p_rationale_1: string
- p_rationale_2: string
- o_response: int64
- objective_rules_rate_1: int64
- objective_rules_rate_2: int64
- o_rationale_1: string
- o_rationale_2: string
- c_response: int64
- clarity_rate_1: int64
- clarity_rate_2: int64
- c_rationale_1: string
- c_rationale_2: string
- i_response: int64
- information_richness_rate_1: int64
- information_richness_rate_2: int64
- i_rationale_1: string
- i_rationale_2: string
- s_response: int64
- safety_rate_1: int64
- safety_rate_2: int64
- s_rationale_1: string
- s_rationale_2: string
- text_critique_1: string
- text_critique_2: string
- overall_response: int64
- overall_textfeedback: string
- 分割:
- example
配置名称:example_ti2ti
- 特征:
- question: string
- input_image:
- text_response_1: string
- image_response_1:
- res_1_from: string
- text_response_2: string
- image_response_2:
- res_2_from: string
- p_response: string
- prompt_following_rate_1: string
- prompt_following_rate_2: string
- p_rationale_1: string
- p_rationale_2: string
- o_response: string
- objective_rules_rate_1: string
- objective_rules_rate_2: string
- o_rationale_1: string
- o_rationale_2: string
- ca_response: string
- ca_rate_1: string
- ca_rate_2: string
- ca_rationale_1: string
- ca_rationale_2: string
- i_response: string
- information_richness_rate_1: string
- information_richness_rate_2: string
- i_rationale_1: string
- i_rationale_2: string
- s_response: string
- safety_rate_1: string
- safety_rate_2: string
- s_rationale_1: string
- s_rationale_2: string
- c_response: string
- consistency_rate_1: string
- consistency_rate_2: string
- c_rationale_1: string
- c_rationale_2: string
- image_critique_1: string
- text_critique_1: string
- image_critique_2: string
- text_critique_2: string
- overall_response: string
- overall_textfeedback: string
- 分割:
- example
配置名称:example_t2t
- 特征:
- question: string
- response_1: string
- response_2: string
- p_response: int64
- prompt_following_rate_1: int64
- prompt_following_rate_2: int64
- p_rationale_1: string
- p_rationale_2: string
- o_response: int64
- objective_rules_rate_1: int64
- objective_rules_rate_2: int64
- o_rationale_1: string
- o_rationale_2: string
- c_response: int64
- clarity_rate_1: int64
- clarity_rate_2: int64
- c_rationale_1: string
- c_rationale_2: string
- i_response: int64
- information_richness_rate_1: int64
- information_richness_rate_2: int64
- i_rationale_1: string
- i_rationale_2: string
- s_response: int64
- safety_rate_1: int64
- safety_rate_2: int64
- s_rationale_1: string
- s_rationale_2: string
- text_critique_1: string
- text_critique_2: string
- overall_response: int64
- overall_textfeedback: string
- 分割:
- example
配置名称:example_ta2t
- 特征:
- prompt: string
- case: string
- audio_path: audio
- caption: string
- response_1: string
- res_1_from: string
- response_2: string
- res_2_from: string
- prompt_sha256: string
- p_response: int64
- prompt_following_rate_1: int64
- prompt_following_rate_2: int64
- p_rationale_1: string
- p_rationale_2: string
- o_response: int64
- objective_rules_rate_1: int64
- objective_rules_rate_2: int64
- o_rationale_1: string
- o_rationale_2: string
- c_response: int64
- clarity_rate_1: int64
- clarity_rate_2: int64
- c_rationale_1: string
- c_rationale_2: string
- i_response: int64
- information_richness_rate_1: int64
- information_richness_rate_2: int64
- i_rationale_1: string
- i_rationale_2: string
- s_response: int64
- safety_rate_1: int64
- safety_rate_2: int64
- s_rationale_1: string
- s_rationale_2: string
- text_critique_1: string
- text_critique_2: string
- overall_response: int64
- overall_textfeedback: string
- 分割:
- example
配置名称:example_t2v
- 特征:
- prompt: string
- video_1: string
- video_2: string
- video_1_model: string
- video_2_model: string
- p_video: int64
- prompt_following_rate_1: int64
- prompt_following_rate_2: int64
- p_rationale_1: string
- p_rationale_2: string
- o_audio: int64
- video_objective_reality_rate_1: int64
- video_objective_reality_rate_2: int64
- o_rationale_1: string
- o_rationale_2: string
- a_video: int64
- aesthetic_rate_1: int64
- aesthetic_rate_2: int64
- a_rationale_1: string
- a_rationale_2: string
- i_video: int64
- information_richness_rate_1: int64
- information_richness_rate_2: int64
- i_rationale_1: string
- i_rationale_2: string
- t_video: int64
- temporal_consistency_rate_1: int64
- temporal_consistency_rate_2: int64
- t_rationale_1: string
- t_rationale_2: string
- c_video: int64
- content_coherence_rate_1: int64
- content_coherence_rate_2: int64
- c_rationale_1: string
- c_rationale_2: string
- m_video: int64
- motion_naturalness_rate_1: int64
- motion_naturalness_rate_2: int64
- m_rationale_1: string
- m_rationale_2: string
- s_video: int64
- safety_rate_1: int64
- safety_rate_2: int64
- s_rationale_1: string
- s_rationale_2: string
- text_1_feedback: string
- text_2_feedback: string
- overall_image: int64
- overall_textfeedback: string
- refine_prompt: string
- reasoning: string
- 分割:
- example
配置名称:example_t2i
- 特征:
- prompt: string
- image_1: image
- image_1_model: string
- image_2: image
- image_2_model: string
- p_image: int64
- prompt_following_rate_1: int64
- prompt_following_rate_2: int64
- p_rationale_1: string
- p_rationale_2: string
- o_image: int64
- objective_rules_rate_1: int64
- objective_rules_rate_2: int64
- o_rationale_1: string
- o_rationale_2: string
- a_image: int64
- aesthetics_rate_1: int64
- aesthetics_rate_2: int64
- a_rationale_1: string
- a_rationale_2: string
- i_image: int64
- information_richness_rate_1: int64
- information_richness_rate_2: int64
- i_rationale_1: string
- i_rationale_2: string
- s_image: int64
- safety_rate_1: int64
- safety_rate_2: int64
- s_rationale_1: string
- s_rationale_2: string
- text_1_feedback: string
- text_2_feedback: string
- overall_image: int64
- overall_textfeedback: string
- 分割:
- example
配置名称:example_t2a
- 特征:
- prompt: string
- response_1: audio
- response_2: audio
- res_1_from: string
- res_2_from: string
- p_audio: int64
- prompt_following_rate_1: int64
- prompt_following_rate_2: int64
- p_rationale_1: string
- p_rationale_2: string
- o_audio: int64
- audio_quality_rate_1: int64
- audio_quality_rate_2: int64
- o_rationale_1: string
- o_rationale_2: string
- a_audio: int64
- consistency_rate_1: int64
- consistency_rate_2: int64
- a_rationale_1: string
- a_rationale_2: string
- i_audio: int64
- information_richness_rate_1: int64
- information_richness_rate_2: int64
- i_rationale_1: string
- i_rationale_2: string
- s_audio: int64
- safety_rate_1: int64
- safety_rate_2: int64
- s_rationale_1: string
- s_rationale_2: string
- text_1_feedback: string
- text_2_feedback: string
- overall_audio: int64
- overall_textfeedback: string
- refine_prompt: string
- reasoning: string
- 分割:
- example
配置名称:text-to-audio
- 特征:
- prompt: string
- response_1: audio
- response_2: audio
- res_1_from: string
- res_2_from: string
- p_audio: int64
- prompt_following_rate_1: int64
- prompt_following_rate_2: int64
- p_rationale_1: string
- p_rationale_2: string
- o_audio: int64
- audio_quality_rate_1: int64
- audio_quality_rate_2: int64
- o_rationale_1: string
- o_rationale_2: string
- a_audio: int64
- consistency_rate_1: int64
- consistency_rate_2: int64
- a_rationale_1: string
- a_rationale_2: string
- i_audio: int64
- information_richness_rate_1: int64
- information_richness_rate_2: int64
- i_rationale_1: string
- i_rationale_2: string
- s_audio: int64
- safety_rate_1: int64
- safety_rate_2: int64
- s_rationale_1: string
- s_rationale_2: string
- text_1_feedback: string
- text_2_feedback: string
- overall_audio: int64
- overall_textfeedback: string
- refine_prompt: string
- reasoning: string
- 分割:
- train
- num_examples: 11934
- num_bytes: 10543178249
- train
配置名称:text-to-image
- 特征:
- prompt: string
- image_1: image
- image_1_model: string
- image_2: image
- image_2_model: string
- p_image: int64
- prompt_following_rate_1: int64
搜集汇总
数据集介绍
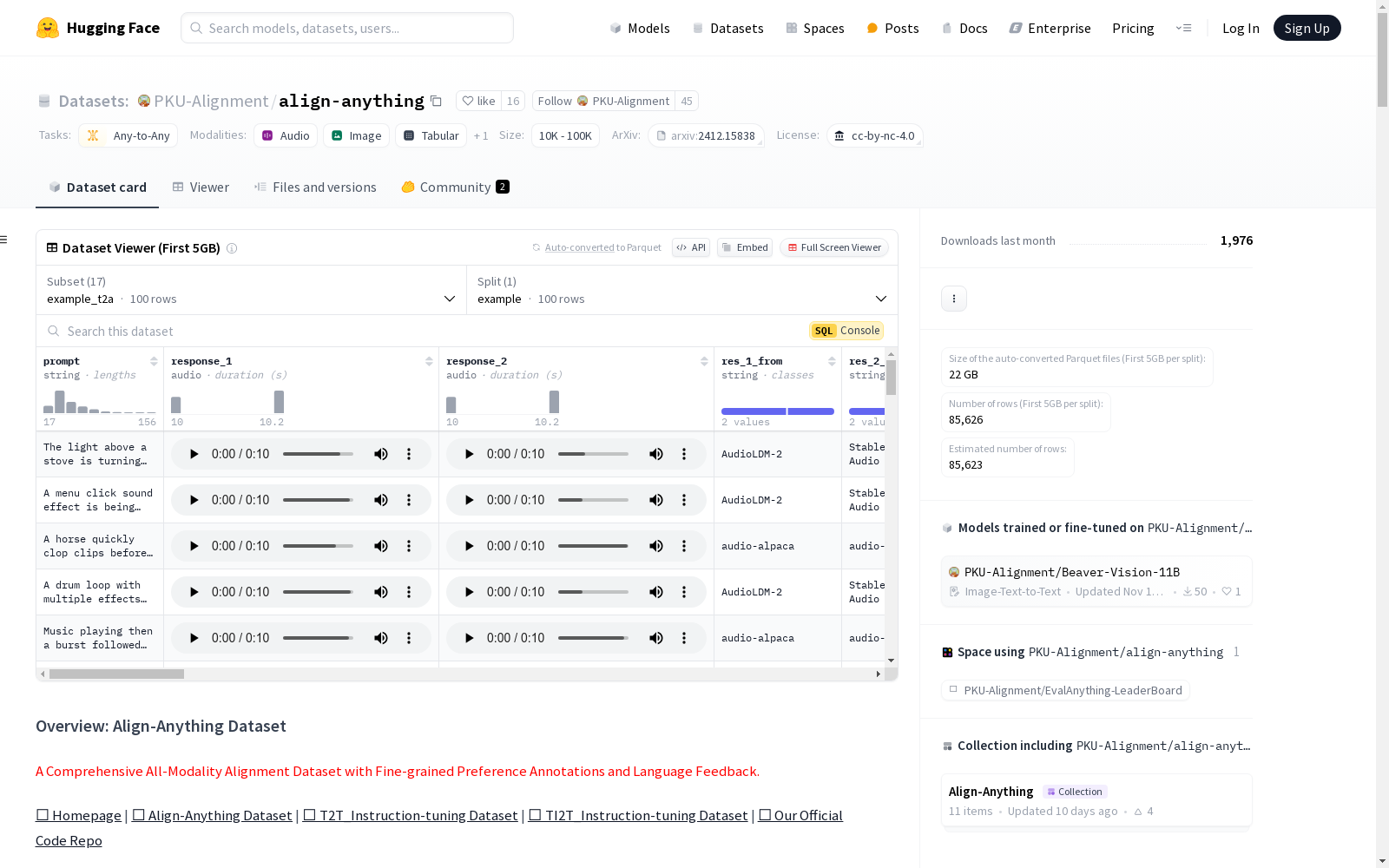
构建方式
align-anything-400K数据集的构建基于多模态任务的需求,涵盖了文本、音频、图像和视频等多种数据类型。数据集的构建过程通过精心设计的提示(prompt)生成多样化的响应,并利用多个模型生成对比结果。每个数据条目均包含原始提示、模型生成的响应以及对这些响应的详细评估指标,确保了数据的多样性和质量。数据集还通过人工或自动化方式对生成的响应进行评分和反馈,进一步提升了数据的可靠性和实用性。
特点
align-anything-400K数据集以其多模态特性为核心,涵盖了文本到音频、文本到图像、文本到视频等多种任务类型。数据集的特点在于其丰富的评估维度,包括提示跟随率、客观规则率、清晰度、信息丰富度和安全性等。每个数据条目均包含多个模型的生成结果及其详细评分,为研究者提供了全面的对比分析基础。此外,数据集还提供了对生成结果的文本反馈和推理过程,进一步增强了数据的可解释性和研究价值。
使用方法
align-anything-400K数据集适用于多模态任务的研究与开发,包括但不限于文本生成、音频生成、图像生成和视频生成。研究者可以通过加载数据集,访问不同任务类型的数据条目,并利用提供的评估指标进行模型性能的对比分析。数据集还支持对生成结果的反馈和推理过程进行深入分析,为模型优化提供参考。此外,数据集的分割方式(如训练集和验证集)为模型的训练和评估提供了便利,确保了研究的系统性和可重复性。
背景与挑战
背景概述
align-anything-400K数据集是一个多模态对齐数据集,旨在解决跨模态任务中的对齐问题。该数据集由多个配置组成,涵盖了文本到音频、文本到图像、文本到视频等多种模态转换任务。其核心研究问题在于如何在不同模态之间实现高效、准确的对齐,从而提升多模态模型的性能。该数据集的创建时间尚未明确,但其设计理念与近年来多模态学习领域的快速发展密切相关,尤其是在生成式模型和多模态对齐技术的研究中,具有重要的参考价值。
当前挑战
align-anything-400K数据集面临的挑战主要体现在两个方面。首先,跨模态对齐任务本身具有较高的复杂性,不同模态之间的语义差异和表达方式多样,如何实现精准对齐是一个技术难点。其次,在数据构建过程中,确保数据的多样性和质量也是一大挑战,尤其是在音频、图像和视频等非文本模态中,数据的采集、标注和评估需要耗费大量资源,且难以保证一致性。此外,多模态数据的融合与对齐对模型的泛化能力提出了更高要求,如何在保证对齐精度的同时提升模型的鲁棒性,是未来研究的重要方向。
常用场景
经典使用场景
在跨模态生成任务中,align-anything-400K数据集被广泛应用于文本到音频、文本到图像、文本到视频等多种生成场景。通过提供丰富的多模态数据,该数据集能够帮助研究人员训练和评估生成模型在遵循提示、生成质量、信息丰富度等方面的表现。特别是在多模态对齐任务中,该数据集为模型提供了多样化的输入和输出组合,使得模型能够更好地理解不同模态之间的关联。
实际应用
在实际应用中,align-anything-400K数据集被用于开发智能内容生成系统,如自动生成音频、图像和视频的创作工具。这些系统可以广泛应用于广告、娱乐、教育等领域,帮助用户快速生成高质量的多媒体内容。此外,该数据集还可用于开发多模态对话系统,提升系统在理解和生成多模态信息方面的能力。
衍生相关工作
基于align-anything-400K数据集,研究人员开发了多种跨模态生成模型,如文本到图像的生成模型、文本到音频的转换模型等。这些模型在生成质量和多模态对齐方面取得了显著进展。此外,该数据集还催生了一系列关于多模态生成评估方法的研究,为跨模态生成领域的标准化评估提供了重要参考。
以上内容由遇见数据集搜集并总结生成


