SOC-2508
收藏Hugging Face2025-08-08 更新2025-08-09 收录
下载链接:
https://huggingface.co/datasets/marcodsn/SOC-2508
下载链接
链接失效反馈官方服务:
资源简介:
Synthetic Online Conversations数据集包含超过1180个由程序生成的多轮在线对话。这些对话模拟了两个虚构角色之间的自然互动,旨在用于训练和评估语言模型在长篇、上下文感知对话生成、角色一致性以及理解复杂的在线交流方面的能力。
创建时间:
2025-08-05
原始信息汇总
Synthetic Online Conversations (SOC-2508) 数据集概述
数据集基本信息
- 许可证: CC BY 4.0
- 语言: 英语 (en)
- 标签: synthetic, conversational, dialogue, role-playing, chat, multi-turn
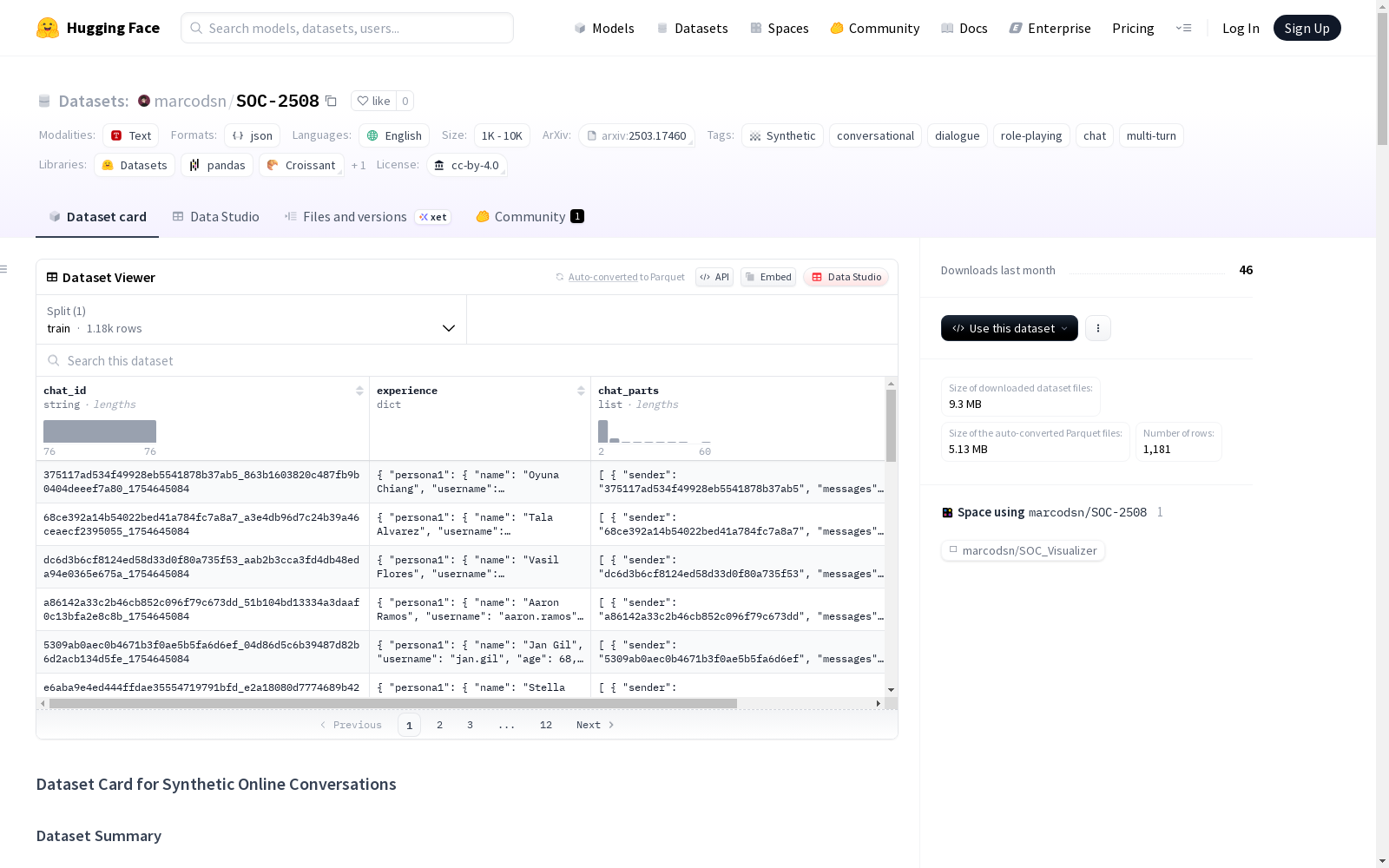
- 数据集规模: 包含1,180条合成的多轮在线对话
数据集内容
- 数据来源: 基于Synthetic Persona Bank (SPB-2508)中的虚构角色生成
- 生成模型: Qwen3-235B-A22B-Instruct-2507
- 特点:
- 包含自然、上下文感知的对话
- 模拟人类不完美特征和现实冲突
- 使用特殊标签模拟多媒体元素(如
<image>,<delay>)
数据结构
- 格式: JSONL文件
- 数据字段:
chat_id: 对话唯一标识符experience: 包含对话上下文信息persona1&persona2: 参与者角色信息relationship: 角色关系描述situation: 对话启动背景topic: 对话起始主题
chat_parts: 对话内容(多轮消息)model: 生成对话的模型
数据集创建
- 生成流程:
- 从SPB-2508中选择角色配对
- 生成对话场景和起始话题
- 分轮次生成对话内容
- 后处理(去重、过滤短对话等)
应用场景
- 训练和评估语言模型在以下任务中的表现:
- 长形式对话生成
- 上下文感知对话
- 角色一致性保持
- 复杂在线交互理解
可视化工具
已知限制
- 合成数据可能不完全反映真实人类对话的不可预测性
- 继承SPB-2508数据集的潜在偏见
- 特殊标签使用不均匀
- 对话结束标记可能过于公式化
- 模型指令遵循不完美
引用信息
bibtex @misc{marcodsn_2025_SOC2508, title = {Synthetic Online Conversations}, author = {Marco De Santis}, year = {2025}, month = {August}, url = {https://huggingface.co/datasets/marcodsn/SOC-2508}, }
搜集汇总
数据集介绍
构建方式
在对话系统研究领域,构建高质量的多轮对话数据集至关重要。SOC-2508数据集通过创新的三阶段生成流程实现:首先从SPB-2508角色库中筛选配对角色,建立合理的关系背景;随后利用Qwen3大语言模型生成情境和开场话题;最后通过迭代式对话展开,融入拼写错误、话题转移等真实对话特征,并加入多媒体标签模拟在线聊天场景。整个流程采用程序化后处理确保数据质量。
特点
该数据集最显著的特点在于其高度拟真的对话特性。每段对话都植根于详尽的角色设定,包含完整的背景故事和对话风格描述。数据中刻意保留了人类对话的不完美特征,如打字错误、回复延迟等,同时通过特殊标签模拟图片分享、音视频等多媒体交互。对话话题自然流转,冲突处理符合角色设定,为研究真实场景下的在线交流提供了丰富素材。
使用方法
研究人员可通过HuggingFace平台直接加载该数据集,其JSONL格式便于流式处理。数据集未预设划分,使用者可根据需要自行拆分训练集、验证集和测试集。配套提供的可视化工具能直观展示对话结构,特别适合用于对话系统开发、角色一致性研究等任务。使用时需注意数据合成特性带来的局限性,建议结合其他真实对话数据共同使用。
背景与挑战
背景概述
SOC-2508数据集是2025年由Marco De Santis团队开发的一项专注于合成多轮在线对话的研究成果。该数据集基于Synthetic Persona Bank (SPB-2508)构建,通过多阶段程序化流程生成1,180组虚构人物间的对话,旨在模拟真实在线交流中的语境感知、风格一致性及人类不完美特征。作为对话系统研究领域的重要资源,其创新性地采用Qwen3-235B大模型驱动生成过程,并引入特殊标签模拟多媒体交互元素,为提升对话系统的自然性和复杂性提供了新的研究范本。
当前挑战
该数据集面临双重挑战:在领域问题层面,需解决合成对话与真实人类交流间的语义鸿沟,包括话题自然漂移、非理性冲突处理等复杂社交特征的建模难题;在构建技术层面,存在大模型指令跟随偏差导致的对话终止过早、特殊标签分布不均衡等问题。此外,源数据集SPB-2508潜在的偏见可能通过对话生成过程被放大,而多媒体标签的离散性使用也影响了数据一致性。
常用场景
经典使用场景
在自然语言处理领域,SOC-2508数据集为多轮对话系统的开发和评估提供了丰富的实验材料。其合成的多人在线对话模拟了真实社交平台中的交互场景,包含完整的人物设定、关系背景及话题演进,特别适合用于测试对话系统在长上下文保持、人物一致性建模以及复杂社交情境理解等方面的性能。研究者可基于该数据集构建端到端的对话生成模型,或开发更精准的对话状态跟踪算法。
衍生相关工作
该数据集已催生多项创新研究,如斯坦福大学提出的PersonaGPT通过迁移学习框架微调生成模型,在SOC-2508上实现了92%的人物属性保持率。Meta发布的Conflict-Resolution Bot则利用数据集中230组含冲突的对话,训练出能识别并化解交流矛盾的专用模块。此外,数据集内嵌的多模态标签激发了CMU团队开发支持图文混排的下一代对话系统框架。
数据集最近研究
最新研究方向
在自然语言处理领域,SOC-2508数据集因其高质量的合成对话数据而备受关注。该数据集通过多阶段程序化流程生成,模拟了真实在线对话的复杂性和多样性,包括人物一致性、话题自然演进以及人类对话中的不完美特性。近期研究主要聚焦于如何利用此类合成数据提升对话系统的真实感和适应性,特别是在多轮对话建模、情感分析和个性化对话生成方面。此外,该数据集还被广泛应用于研究对话系统中的偏见问题,以及如何通过合成数据增强小样本学习的效果。随着大语言模型技术的快速发展,SOC-2508为探索对话生成的前沿技术提供了重要基础,尤其在模拟复杂社交互动和多媒体元素整合方面展现出独特价值。
以上内容由遇见数据集搜集并总结生成


