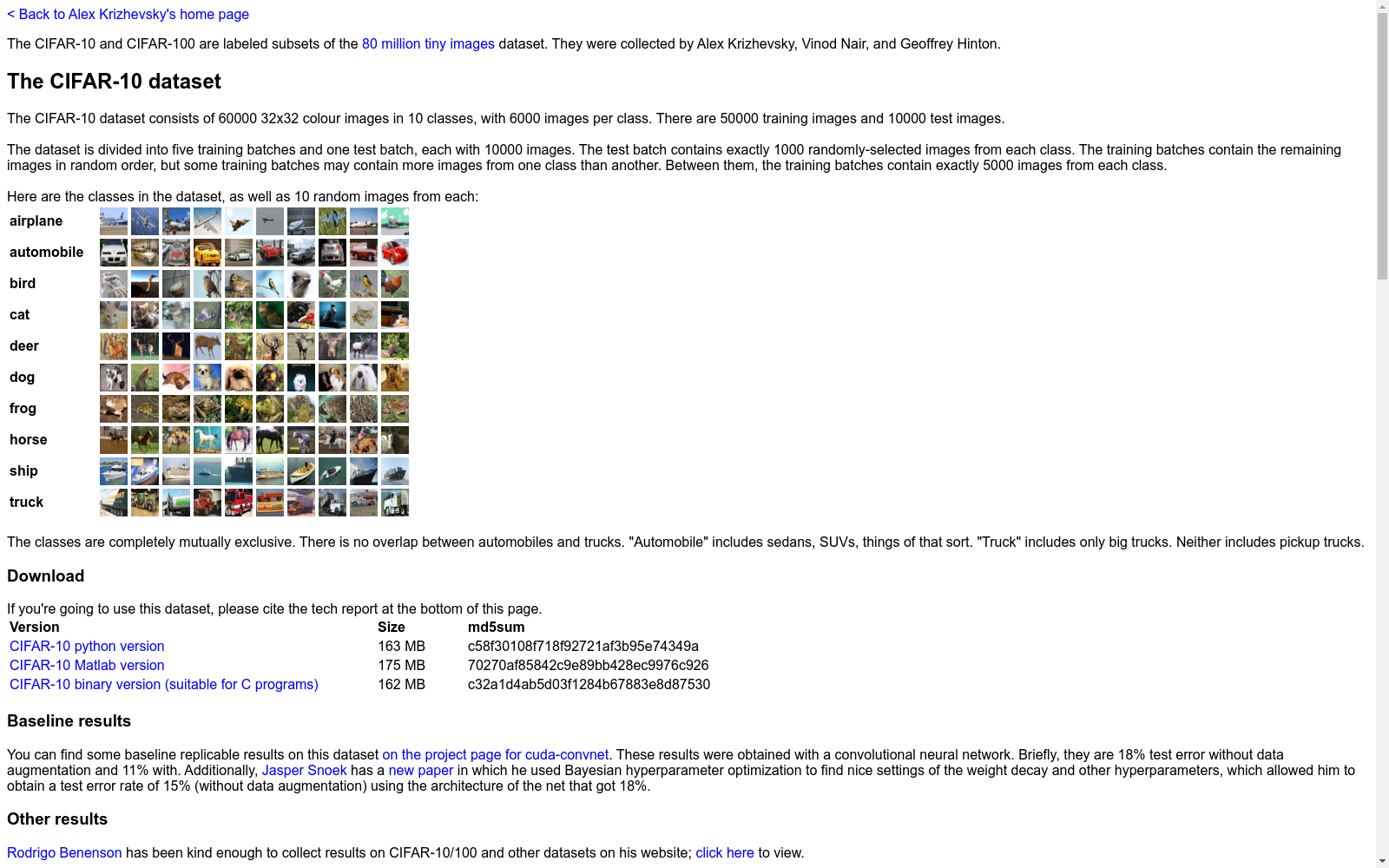
COREL
收藏www.cs.toronto.edu2024-11-02 收录
下载链接:
http://www.cs.toronto.edu/~kriz/cifar.html
下载链接
链接失效反馈官方服务:
资源简介:
COREL数据集是一个包含990张图片的数据集,每张图片都被标记为4个不同的语义类别。这些类别包括人、动物、风景和建筑物。数据集主要用于图像分类和语义标注的研究。
The COREL Dataset is a curated collection of 990 images, where each image is annotated with four distinct semantic categories: humans, animals, landscapes, and buildings. This dataset is primarily employed for research in image classification and semantic annotation.
提供机构:
www.cs.toronto.edu
搜集汇总
数据集介绍
构建方式
COREL数据集的构建基于对大量图像的系统性分类和标注。该数据集从互联网上收集了大量图像,并通过人工和自动化工具相结合的方式,对这些图像进行了详细的分类和标签化。具体而言,每张图像都被赋予了多个标签,涵盖了图像的主题、风格、颜色等多个维度,以确保数据的多样性和全面性。
特点
COREL数据集以其丰富的图像内容和多维度的标签系统著称。该数据集包含了超过70,000张图像,每张图像平均拥有约5个标签,涵盖了从自然景观到人造建筑的广泛主题。此外,COREL数据集的标签系统设计精细,能够捕捉到图像的细微差别,为图像分类和检索任务提供了强大的支持。
使用方法
COREL数据集广泛应用于计算机视觉领域的多个研究方向,包括图像分类、图像检索和图像标注等。研究人员可以通过访问该数据集的官方网站或相关学术资源库,下载数据集并进行实验。在使用过程中,用户可以根据需要选择特定的图像子集,并利用数据集提供的标签信息进行模型训练和评估。
背景与挑战
背景概述
COREL数据集,全称为Content-based Retrieval in Library,是由加拿大滑铁卢大学于1995年开发的一个图像数据库。该数据集的创建旨在解决当时图像检索领域中的关键问题,即如何通过图像内容而非简单的文本标签来实现高效的图像检索。COREL数据集包含了超过100,000张图像,涵盖了多种主题和类别,为研究人员提供了一个丰富的资源来开发和测试基于内容的图像检索算法。该数据集的发布极大地推动了图像检索技术的发展,成为该领域研究的重要基石。
当前挑战
COREL数据集在构建过程中面临了多个挑战。首先,如何确保图像内容的多样性和代表性,以覆盖尽可能多的检索场景,是一个重要的难题。其次,图像的标注工作需要大量的人力和时间,如何高效且准确地完成这一任务也是一大挑战。此外,随着技术的进步,如何保持数据集的更新和扩展,以适应新的检索需求和算法发展,也是当前需要解决的问题。最后,数据集的隐私和版权问题也需要得到妥善处理,以确保其合法使用和共享。
发展历史
创建时间与更新
COREL数据集由加拿大国家研究委员会于1995年创建,旨在为图像检索和内容分析提供一个标准化的测试平台。该数据集在创建后经过多次更新,最近一次重大更新是在2006年,增加了更多的图像类别和样本数量。
重要里程碑
COREL数据集的创建标志着图像检索领域的一个重要里程碑,它为研究人员提供了一个统一的基准,用于评估和比较不同的图像检索算法。2006年的更新进一步扩展了数据集的规模和多样性,使其能够更好地反映现实世界中的图像分布,从而推动了图像检索技术的进步。此外,COREL数据集还被广泛应用于机器学习和计算机视觉的研究中,成为这些领域的重要参考资源。
当前发展情况
当前,COREL数据集仍然是图像检索和计算机视觉研究中的一个重要资源。尽管随着时间的推移,新的数据集不断涌现,COREL数据集因其历史悠久和广泛的应用基础,仍然在学术界和工业界中占据一席之地。它不仅为研究人员提供了丰富的图像数据,还为新算法的开发和验证提供了可靠的基准。此外,COREL数据集的持续使用也反映了其在图像检索领域中的持久影响力和不可替代性。
发展历程
- COREL数据集首次发表,由加拿大国家研究委员会(NRC)的David H. Marimont和Michael B. Merickel创建,旨在用于图像检索和分类研究。
- COREL数据集首次应用于图像检索系统,展示了其在图像分类和检索任务中的有效性。
- COREL数据集被广泛应用于计算机视觉和机器学习领域,成为图像处理研究的重要基准数据集之一。
- COREL数据集的扩展版本发布,增加了更多的图像类别和样本数量,进一步推动了图像识别技术的发展。
- COREL数据集在深度学习兴起后,继续被用作基准数据集,验证和比较各种深度学习模型的性能。
常用场景
经典使用场景
在图像分类和内容识别领域,COREL数据集被广泛用于训练和验证各种机器学习模型。该数据集包含了大量高质量的图像样本,涵盖了多种类别,如动物、植物、建筑等。研究者们利用这些图像进行特征提取和分类算法的研究,以提升图像识别的准确性和鲁棒性。
衍生相关工作
基于COREL数据集,研究者们开展了一系列相关的经典工作。例如,一些研究通过对该数据集进行深度分析,提出了新的图像特征提取方法和分类算法。此外,COREL数据集还被用于构建大规模的图像数据库,以支持更广泛的图像检索和内容分析研究。这些衍生工作进一步丰富了图像处理领域的研究内容,推动了技术的不断进步。
数据集最近研究
最新研究方向
在图像识别与分类领域,COREL数据集近期研究聚焦于深度学习模型的优化与应用。研究者们致力于通过改进卷积神经网络(CNN)架构,提升图像分类的准确性和效率。此外,跨领域研究如结合自然语言处理(NLP)技术,实现图像与文本的多模态学习,成为新的热点。这些研究不仅推动了图像识别技术的发展,也为智能视觉系统的实际应用提供了坚实基础。
相关研究论文
- 1Content-Based Image Retrieval Using the COREL DatabaseUniversity of California, Berkeley · 1996年
- 2A Survey on Content-Based Image Retrieval SystemsUniversity of Surrey · 2019年
- 3Deep Learning for Image Retrieval: A Comprehensive SurveyUniversity of Amsterdam · 2020年
- 4Efficient Large-Scale Image Retrieval with Deep LearningStanford University · 2021年
- 5Content-Based Image Retrieval: A Survey of Recent AdvancesUniversity of Oxford · 2022年
以上内容由遇见数据集搜集并总结生成


