chiayewken/m3exam
收藏Hugging Face2023-10-09 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/chiayewken/m3exam
下载链接
链接失效反馈官方服务:
资源简介:
M3Exam是一个多语言、多模态、多层次的基准测试数据集,用于评估大型语言模型(LLMs)。该数据集包含多个语言的配置,每个配置都有相同的特征,并且每个配置都分为dev和test两个分割。数据集的特征包括问题文本、背景信息、答案文本、选项、语言、难度级别、学科和学科类别。
M3Exam is a multilingual, multimodal, multi-level benchmark dataset designed for evaluating Large Language Models (LLMs). This dataset provides configurations across multiple languages, each of which shares an identical set of features, and each configuration is split into two subsets: dev and test. The features contained in the dataset include question text, background information, answer text, options, language, difficulty level, discipline, and discipline category.
提供机构:
chiayewken
原始信息汇总
数据集概述
数据集配置
Afrikaans
- 特征:
question_text: stringbackground: stringanswer_text: stringoptions: sequence of stringlanguage: stringlevel: stringsubject: stringsubject_category: string
- 分割:
dev:num_bytes: 8860num_examples: 25
test:num_bytes: 194333num_examples: 258
- 下载大小: 71295
- 数据集大小: 203193
Chinese
- 特征:
question_text: stringbackground: stringanswer_text: stringoptions: sequence of stringlanguage: stringlevel: stringsubject: stringsubject_category: string
- 分割:
dev:num_bytes: 25055num_examples: 29
test:num_bytes: 485093num_examples: 682
- 下载大小: 289255
- 数据集大小: 510148
English
- 特征:
question_text: stringbackground: stringanswer_text: stringoptions: sequence of stringlanguage: stringlevel: stringsubject: stringsubject_category: string
- 分割:
dev:num_bytes: 12792num_examples: 32
test:num_bytes: 2573796num_examples: 1911
- 下载大小: 697219
- 数据集大小: 2586588
Italian
- 特征:
question_text: stringbackground: stringanswer_text: stringoptions: sequence of stringlanguage: stringlevel: stringsubject: stringsubject_category: string
- 分割:
dev:num_bytes: 5834num_examples: 18
test:num_bytes: 2397963num_examples: 811
- 下载大小: 326671
- 数据集大小: 2403797
Javanese
- 特征:
question_text: stringbackground: stringanswer_text: stringoptions: sequence of stringlanguage: stringlevel: stringsubject: stringsubject_category: string
- 分割:
dev:num_bytes: 1425num_examples: 6
test:num_bytes: 187280num_examples: 371
- 下载大小: 84085
- 数据集大小: 188705
Portuguese
- 特征:
question_text: stringbackground: stringanswer_text: stringoptions: sequence of stringlanguage: stringlevel: stringsubject: stringsubject_category: string
- 分割:
dev:num_bytes: 20979num_examples: 24
test:num_bytes: 941655num_examples: 889
- 下载大小: 614816
- 数据集大小: 962634
Swahili
- 特征:
question_text: stringbackground: stringanswer_text: stringoptions: sequence of stringlanguage: stringlevel: stringsubject: stringsubject_category: string
- 分割:
dev:num_bytes: 2053num_examples: 6
test:num_bytes: 607215num_examples: 428
- 下载大小: 94031
- 数据集大小: 609268
Thai
- 特征:
question_text: stringbackground: stringanswer_text: stringoptions: sequence of stringlanguage: stringlevel: stringsubject: stringsubject_category: string
- 分割:
dev:num_bytes: 16185num_examples: 26
test:num_bytes: 2249737num_examples: 2168
- 下载大小: 901256
- 数据集大小: 2265922
Vietnamese
- 特征:
question_text: stringbackground: stringanswer_text: stringoptions: sequence of stringlanguage: stringlevel: stringsubject: stringsubject_category: string
- 分割:
dev:num_bytes: 7974num_examples: 28
test:num_bytes: 767759num_examples: 1789
- 下载大小: 375774
- 数据集大小: 775733
搜集汇总
数据集介绍
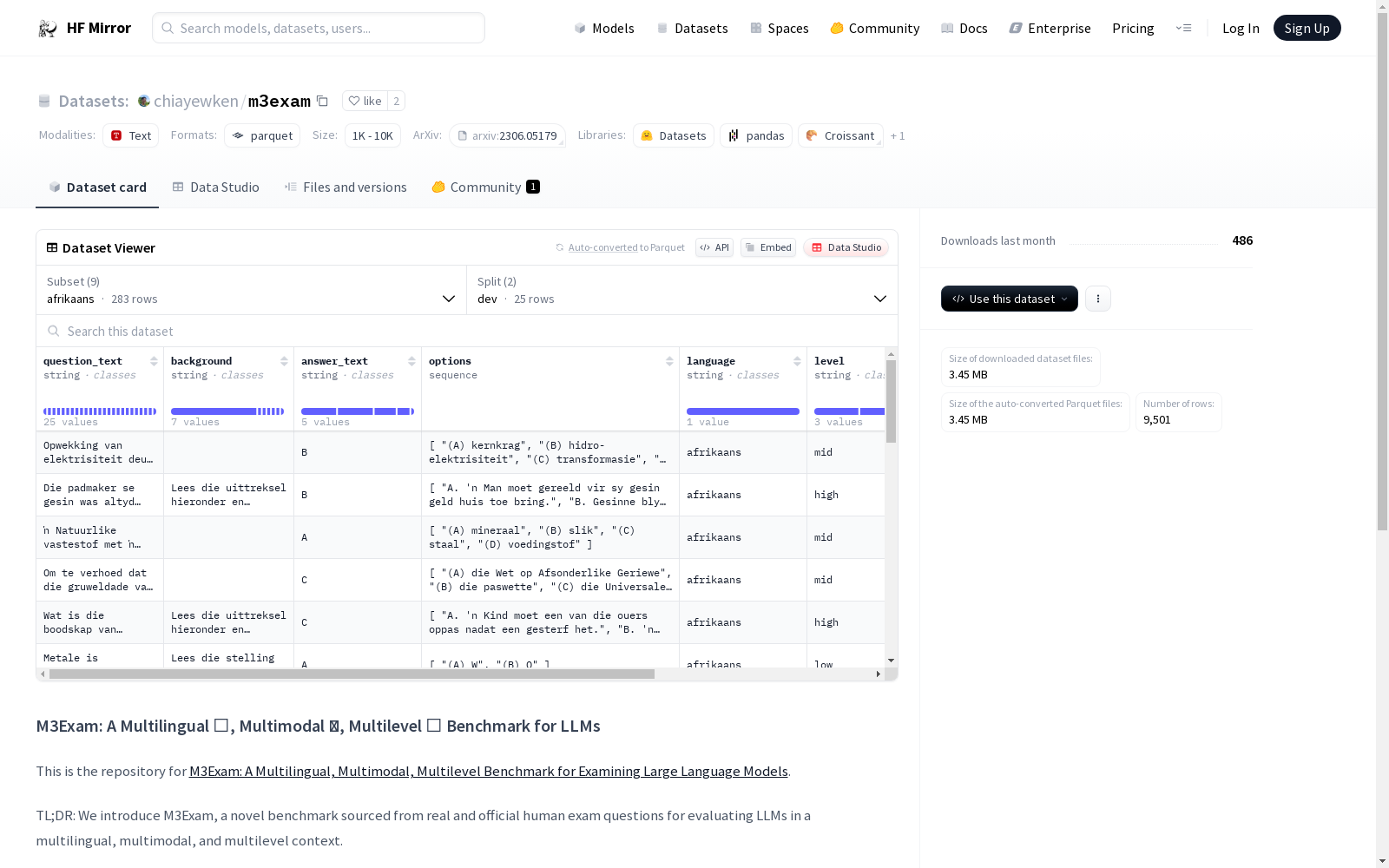
构建方式
M3Exam数据集的构建采用现实世界中官方的人类考试问题作为来源,涵盖多种语言、模态和难度级别。数据集包含多个配置,每个配置针对不同语言(如中文、英文等)提供问题文本、背景信息、答案文本、选项、语言类型、难度级别、科目和科目类别等字段。通过精心设计的数据收集和预处理流程,确保了数据的质量和多样性,为大型语言模型在多语言、多模态和多级别环境下的评估提供了可靠的数据基础。
特点
M3Exam数据集的特点在于其多语言、多模态和多级别的综合特性。它不仅包含文本信息,还涉及图像等模态的数据,且覆盖从基础到高级的不同难度级别,适用于不同层次的语言模型评估。此外,数据集的问题来源真实可靠,能够有效反映语言模型在现实考试场景中的表现,为研究者和开发者提供了全面而深刻的评估视角。
使用方法
使用M3Exam数据集时,用户需根据所需语言和难度级别选择相应的配置文件。数据集提供了开发集和测试集,方便用户进行模型训练和性能评估。用户可以通过HuggingFace的库直接加载和利用这些数据,按照既定的数据格式进行模型输入,进而开展针对性的研究和实验。
背景与挑战
背景概述
M3Exam数据集,全称为Multilingual, Multimodal, Multilevel Exam Dataset,是一项针对大型语言模型(LLM)的多语言、多模态、多层次评估的基准数据集。该数据集的创建旨在为评估LLM在不同语言、不同难度层次以及处理不同模态数据的能力提供一个可靠的测试平台。M3Exam的构建基于真实的人类考试问题,涵盖了包括中文、英文、意大利语、葡萄牙语等在内的多种语言,并包含了文本和图片等多种模态的数据。该数据集的发布对于自然语言处理领域有着重要的推动作用,特别是在大型语言模型的评估和比较方面,提供了新的视角和工具。
当前挑战
M3Exam数据集在构建过程中面临的挑战主要包括:1)如何确保收集到的考试问题能够全面反映不同语言、不同难度层次的特点;2)如何有效地整合和处理多模态数据,使之能够适应大型语言模型的评估需求;3)如何保证数据集的质量和一致性,确保评估结果的可靠性和有效性。在解决领域问题方面,M3Exam的挑战在于,它需要能够准确地评估LLM在处理真实世界考试问题时的表现,这要求数据集不仅要有足够的多样性和复杂性,还要能够模拟真实考试环境中的各种情况。
常用场景
经典使用场景
M3Exam数据集作为一项多语言、多模态、多层次的评价基准,其经典使用场景主要在于对大型语言模型(LLM)的能力进行全面的测试与评估。该数据集汇聚了真实的人类考试问题,涵盖了不同语言、难度和学科类别,从而使得研究者能够利用这一综合资源对LLM进行跨文化、跨学科的性能评价。
实际应用
在实际应用中,M3Exam数据集可以用于指导教育技术领域的发展,如在线学习系统的智能问答功能,以及多语言教学材料的自动生成。此外,它还能够服务于智能客服、多语言翻译服务等实际场景,提升跨语言信息交流的效率和准确度。
衍生相关工作
M3Exam数据集的推出催生了一系列相关研究工作,包括但不限于对现有LLM的多语言和多模态扩展研究,对考试问题生成和自动评分系统的开发,以及对不同语言和学科类别下LLM性能差异的深入分析,这些研究为语言模型在教育和评估领域的应用提供了新的视角和方法论。
以上内容由遇见数据集搜集并总结生成


