SKIML-ICL/hoh_10000
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/SKIML-ICL/hoh_10000
下载链接
链接失效反馈官方服务:
资源简介:
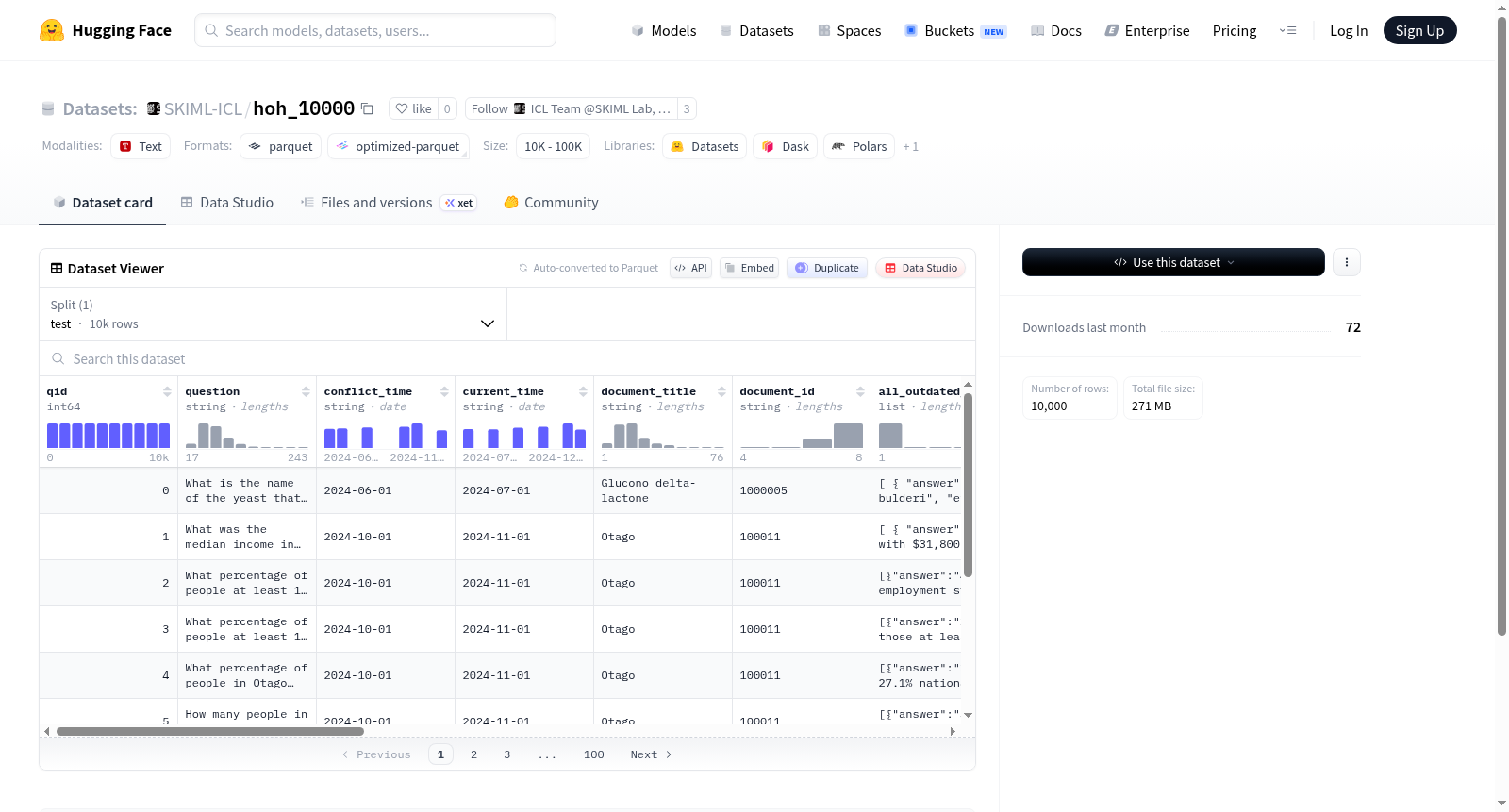
该数据集包含多个特征字段,如问题ID、问题文本、冲突时间、当前时间、文档标题、文档ID等。此外,数据集还包含多个列表类型的字段,如所有过时信息、上下文信息、可回答前缀、冲突答案等。数据集的分割信息显示,只有一个测试集,包含10,000个样本。
The dataset contains multiple feature fields, such as question ID, question text, conflict time, current time, document title, document ID, etc. In addition, the dataset also includes multiple list-type fields, such as all outdated information, context information, answerable prefix, conflict answers, etc. The split information of the dataset shows that there is only one test set, containing 10,000 samples.
提供机构:
SKIML-ICL
搜集汇总
数据集介绍
构建方式
该数据集名为hoh_10000,专注于检索增强生成(RAG)场景下时间敏感问题的处理。构建过程通过收集包含过时信息的问答对,并利用维基百科等动态知识源对每个问题关联多个可能过时的答案及证据。每条数据标注了冲突时间、当前时间以及过时信息的具体内容,同时提供相关上下文段落和检索文档,确保模型能识别并应对信息时效性带来的答案不一致问题。
使用方法
使用时,可直接加载test数据拆分,通过字段'question'输入问题,利用'ctxs'中的检索文本和'score'评估相关性。模型需基于'current_time'和'conflict_time'区分新旧信息,并参考'answerable_prefix'和'conflict_answers'生成正确回答。适用于测试RAG模型在时间动态场景下的鲁棒性,尤其关注其能否从'context'和'conflict_passage'中筛选出符合当前时间的准确答案。
背景与挑战
背景概述
在信息检索与问答系统领域,时间动态性对知识准确性提出了严峻挑战。传统问答数据集多假设知识库静态不变,忽略了信息随时间的演化与冲突。hoh_10000数据集由研究机构于近期创建,聚焦于知识时效性引发的歧义问题,核心研究在于模拟真实世界中因更新滞后、多方来源矛盾导致的答案冲突场景。该数据集通过收录问题、时间戳、冲突信息及上下文段落,为评估模型处理时序不一致性提供了基准,其影响力体现在推动开放域问答模型从静态推理向动态认知的转型,尤其对知识蒸馏、持续学习等方向具有重要参考价值。
当前挑战
当前hoh_10000数据集面临的首要挑战是模型对时间认知的鲁棒性不足。传统问答模型依赖静态文本匹配,难以区分过时信息与当前有效证据,导致在‘冲突时间’与‘当前时间’并存的样本中准确率骤降。此外,构建过程中需人工标注冲突证据的有效性(is_valid_conflict_passage),面临标注者间一致性低、冲突粒度界定模糊的难题。同时,多源证据(ctxs)的时序排序与可信度评估缺乏标准化,使得模型在跨时间片段推理时易陷入局部最优解,这些局限限制了数据集在实时问答与知识库更新场景中的泛化应用。
常用场景
经典使用场景
在自然语言处理与信息检索的交叉领域,hoh_10000数据集凭借其独特的'冲突时间'与'过期信息'标注,成为评估问答系统时间鲁棒性的基准。该数据集聚焦于维基百科等动态知识源中信息过时引发的回答矛盾问题,经典使用场景是训练和测试模型对时效性敏感的开放域问答能力。研究者通过对比模型在'当前时间'与'冲突时间'下的回答差异,量化系统对知识演变的适应程度,从而推动时间感知问答技术的发展。
解决学术问题
hoh_10000数据集系统性地解决了信息时间错位导致的问答不一致这一学术难题。传统问答数据集假定知识静态不变,而现实世界中的事实持续更新,这使得模型在面临新旧信息冲突时易产生错误答案。该数据集通过标注过期证据与有效答案的对应关系,为研究知识时效性对模型性能的影响提供了量化基础,推动学界从静态检索转向动态知识追踪,显著提升了问答系统在动态环境下的可靠性评估范式。
实际应用
在实际应用中,hoh_10000数据集为智能助手、搜索引擎和知识图谱维护系统的时间感知升级提供了关键支撑。例如,在医疗咨询或金融资讯场景中,信息时效性至关重要,利用该数据集训练的模型能够识别并规避过时的治疗方案或过期的股票数据,优先采纳最新权威来源。同时,该数据集启发开发了自动检测维基百科冲突版本的工具,协助编辑者快速定位需要更新的矛盾段落,增强了知识库维护的效率与准确性。
数据集最近研究
最新研究方向
在自然语言处理领域,hoh_10000数据集聚焦于时态信息冲突检测与过时知识动态甄别的前沿探索。该数据集以10,000条精心构建的样本为基础,每个样本包含问题、文档、冲突时间及多版本答案等结构化信息,旨在模拟真实世界中知识随时间演进而产生的语义矛盾。当前研究热点集中于利用该数据集训练模型识别文本间的时序不一致性,推动开放域问答系统在时效性感知、动态知识溯源及多源信息融合方面的能力跃升。这一方向与大型语言模型在实时信息处理中的可靠性挑战紧密相连,为构建能够主动感知知识更新、规避过时信息误导的智能系统提供了关键基准,对金融、医疗等需持续知识更新的领域具有深远意义。
以上内容由遇见数据集搜集并总结生成


