tokenizer-robustness-mmlu
收藏Hugging Face2025-05-25 更新2025-05-26 收录
下载链接:
https://huggingface.co/datasets/Malikeh1375/tokenizer-robustness-mmlu
下载链接
链接失效反馈官方服务:
资源简介:
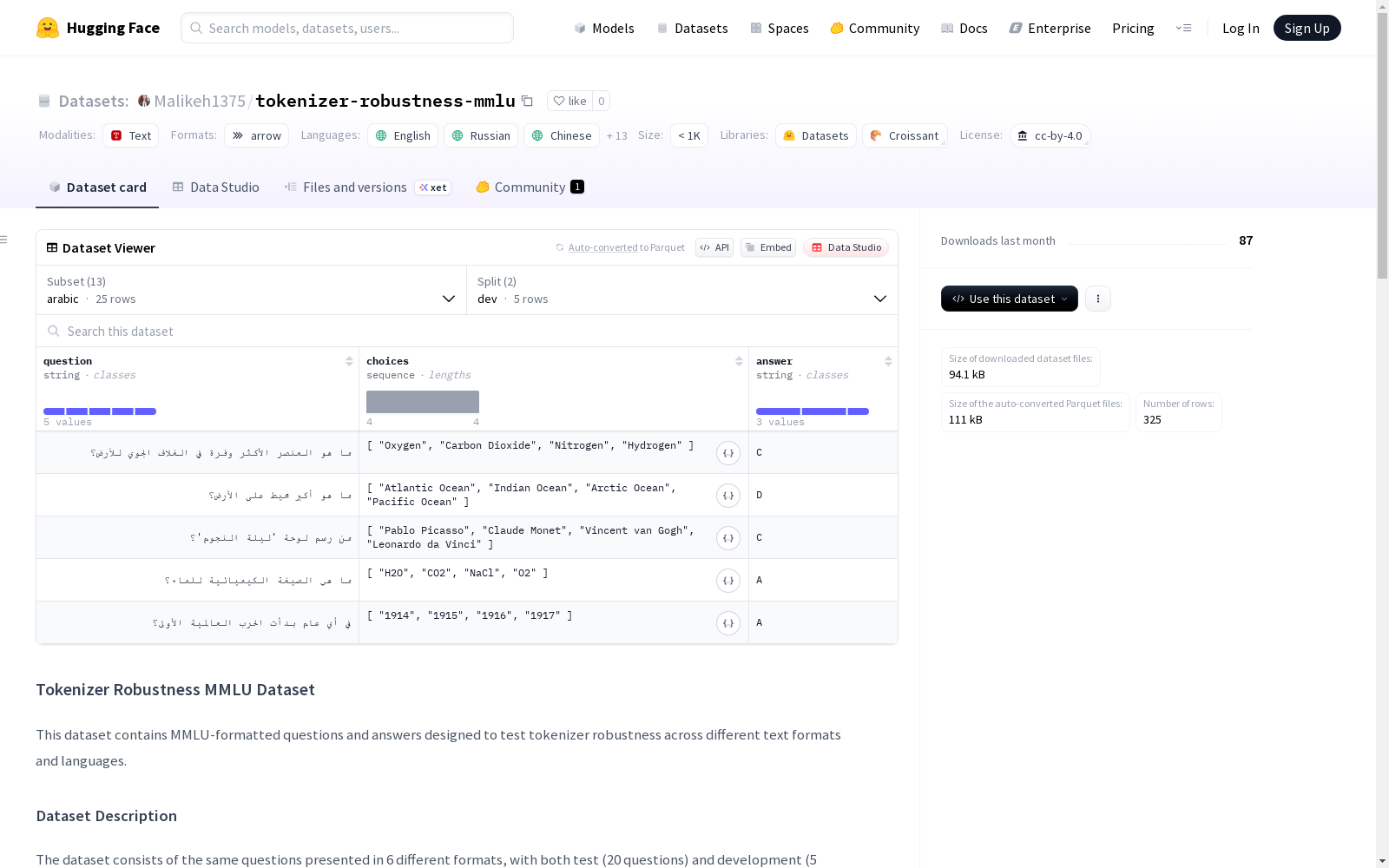
该数据集是一个用于测试标记器鲁棒性的MMLU格式的问题和答案集,包含6种不同格式的问题,分别为标准格式、轻微拼写错误、口语化语言、阿拉伯语翻译、泰卢固语翻译、严重拼写错误,以及包含代码的Python、Java、R语言问题,还有特殊文本格式和语言切换的挑战性问题。每个配置都有测试集和开发集,包含20个测试问题和5个开发问题。
创建时间:
2025-05-15
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,Tokenizer Robustness MMLU数据集的构建基于MMLU基准测试框架,通过系统化设计13种不同文本格式的变体来评估分词器的鲁棒性。该数据集采用统一的多选题结构,每种配置包含相同的知识问题,但在文本表达上进行了多样化处理,包括原始规范问题、轻微拼写错误、口语化表达、阿拉伯语和泰卢固语翻译、严重拼写变形、Python/Java/R代码片段、Unicode文本格式化挑战、特殊字符翻转、扎尔戈文字同形异义符以及多语言代码切换等变形版本。开发集与测试集分别包含5个和20个平行问题样本,确保各变体间内容一致性。
特点
该数据集的核心特征体现在其多维度的文本扰动设计上,覆盖了从表层拼写变异到深层语言结构变化的连续谱系。除基础的语言格式转换外,特别集成了编程语言代码嵌入、特殊字符处理、多语言混合等前沿测试场景。13种配置模块分别对应不同的文本噪声类型,其中代码类变体要求模型解析程序逻辑,而Unicode挑战配置则测试文本渲染鲁棒性。数据集支持跨语言评估,涵盖英语、俄语、中文等16种语言环境,为分词器在真实复杂场景下的性能评估提供立体化基准。
使用方法
使用该数据集时,研究人员可通过HuggingFace数据集库的配置加载机制定向调用特定文本变体。典型流程包括使用load_dataset函数指定原始仓库路径与目标配置名称,如'major_spelling_errors'或'code_switching',进而访问开发集或测试集分割。每个样本呈现为结构化JSON对象,包含问题描述、选项列表和标准答案键值。评估时需平行比较同一问题在不同配置下的模型输出一致性,特别关注代码解析、特殊字符处理等专项能力。该设计支持端到端的分词器鲁棒性诊断,适用于多语言模型、代码理解模型等前沿系统的验证场景。
背景与挑战
背景概述
Tokenizer Robustness MMLU数据集作为多语言自然语言处理领域的重要基准,旨在系统评估语言模型在多样化文本格式下的鲁棒性表现。该数据集基于MMLU(Massive Multitask Language Understanding)框架构建,通过涵盖原始文本、拼写错误、口语化表达及多语言翻译等13种文本变体,深入探究分词器对输入扰动的敏感性。其设计理念源于当前预训练语言模型在实际应用中面临的泛化能力不足问题,特别是在处理非规范文本时性能显著下降的挑战。数据集采用CC-BY-4.0许可协议,支持包括英语、阿拉伯语、泰卢固语等16种语言,为研究社区提供了跨语言分词鲁棒性的标准化评估平台。
当前挑战
该数据集核心挑战在于解决语言模型对文本表面形式变化的过度敏感问题,即模型应具备超越表层特征而理解语义本质的能力。构建过程中需克服多语言对齐的技术难题,确保不同语言版本间语义等价性;同时要精确控制文本扰动程度,如从轻微拼写错误到严重字符变形之间的梯度设计。针对代码混合场景,需要平衡语言切换的自然性与评估有效性;在特殊字符处理方面,需系统分类Unicode变体、同形异义字等非常规文本表征。这些挑战共同指向分词器泛化能力的核心瓶颈,为提升模型在实际应用中的稳定性提供关键诊断依据。
常用场景
经典使用场景
在自然语言处理领域,Tokenizer Robustness MMLU数据集被广泛用于评估语言模型对多样化文本输入的适应能力。该数据集通过呈现13种不同格式的相同知识问题,包括标准文本、拼写错误、口语化表达、多语言翻译及代码混合等场景,为研究者提供了系统测试分词器鲁棒性的标准化平台。模型在此数据集上的表现直接反映了其对真实世界文本噪声的容忍度。
衍生相关工作
该数据集催生了多项关于分词鲁棒性的创新研究。例如有工作基于其多语言配置开发了动态词汇表调整算法,另有研究利用其代码混合数据训练出具有跨语言泛化能力的分词器。这些衍生工作不仅深化了对分词机制的理论理解,还推动了自适应分词技术在低资源语言处理、噪声文本清洗等方向的实际应用。
数据集最近研究
最新研究方向
在自然语言处理领域,Tokenizer Robustness MMLU数据集正推动着模型鲁棒性研究的前沿探索。该数据集通过多语言、拼写变异及代码混合等13种文本扰动形式,系统评估分词器对噪声输入的适应能力。随着大语言模型在多语种环境中的广泛应用,研究者聚焦于模型在非规范文本(如Zalgo装饰字符、特殊符号翻转等)下的性能稳定性,这一方向与当前AI安全性和可解释性研究热点紧密相连。该数据集的构建为提升模型在实际场景中的泛化性能提供了关键基准,对推动跨语言智能系统的稳健发展具有深远意义。
以上内容由遇见数据集搜集并总结生成


