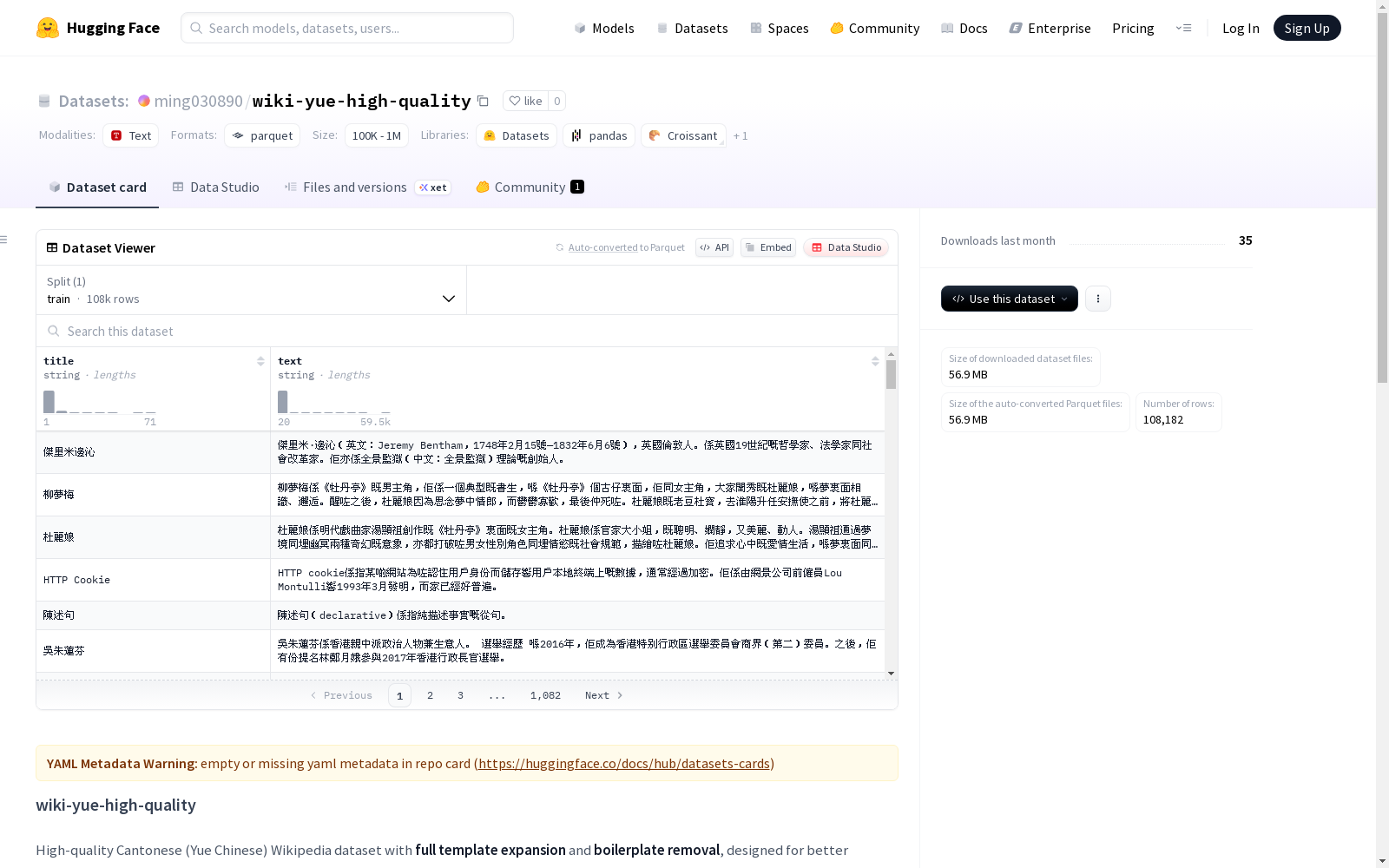
wiki-yue-high-quality
收藏Hugging Face2025-08-12 更新2025-08-13 收录
下载链接:
https://huggingface.co/datasets/ming030890/wiki-yue-high-quality
下载链接
链接失效反馈官方服务:
资源简介:
这是一个高质量、经过完整模板扩展和无关内容移除的粤语维基百科数据集,旨在为语言模型训练提供更好的数据。
创建时间:
2025-08-11
原始信息汇总
wiki-yue-high-quality 数据集概述
数据集简介
- 名称: wiki-yue-high-quality
- 描述: 高质量粤语(Yue Chinese)维基百科数据集,具有完整模板扩展和样板文本移除功能,专为语言模型训练设计。
重要性
- 语言资源状况: 粤语是NLP领域的低资源语言。
- 问题解决: 原始维基百科转储常存在缺失词语(未扩展模板)和无关样板文本的问题,本数据集修复了这两个问题。
示例对比
-
其他粤语维基百科数据集:
港鐵單程票,係可以喺、、、、、、、同一共九條港鐵綫所用嘅車飛,係港鐵一般車飛嘅種類。 ... 參攷 港鐵 香港鐵路車飛
-
本数据集:
港鐵單程票(英文:MTR Single Journey Ticket),係可以喺東涌綫、觀塘綫、荃灣綫、港島綫、東涌綫、將軍澳綫、西鐵綫、馬鞍山綫同迪士尼綫一共九條港鐵綫所用嘅車飛。
数据集详情
- 来源: 粤语维基百科转储
- 语言: 粤语(Yue Chinese, zh-yue)
- 处理: 完整模板扩展,样板文本移除
- 格式: JSON / Parquet
- 分割:
train(完整数据集) - 提取工具: mwparserfromhtml
- 原始数据文件:
zh_yuewiki-NS0-20250320-ENTERPRISE-HTML.json.tar.gz
许可证
- 来源许可证: 源自维基百科,遵循CC BY-SA 3.0。
- 要求: 必须署名维基百科贡献者,并在相同许可证下共享衍生作品。
搜集汇总
数据集介绍
构建方式
在低资源语言处理领域,粤语(Yue Chinese)的文本数据尤为稀缺。wiki-yue-high-quality数据集基于粤语维基百科的原始数据转储,通过专业工具mwparserfromhtml进行深度处理,实现了模板的完整扩展和无关文本的彻底清除。该过程不仅还原了被模板标记隐藏的关键词汇,还移除了干扰模型训练的冗余信息,最终以JSON和Parquet格式呈现,确保了数据的结构化和高效存取。
特点
作为粤语自然语言处理的重要资源,该数据集显著提升了原始维基百科数据的质量。其核心优势在于完整保留语义内容的同时,消除了未扩展模板导致的词汇缺失问题。经处理的文本呈现出更高的连贯性和纯净度,例如将简略表述的线路名称完整还原,使得语料更符合实际语言使用场景。这种精细化的处理为语言模型训练提供了优质的底层数据支撑。
使用方法
针对粤语NLP研究的特殊需求,该数据集可直接应用于语言模型的预训练或微调阶段。研究者可通过HuggingFace平台便捷加载数据,利用其标准化的train分割快速构建训练集。由于数据已完成清洗和结构化处理,使用者可跳过繁琐的预处理步骤,直接聚焦于模型架构设计或下游任务开发。对于需要扩展粤语语料库的场景,该数据集亦可作为高质量的基础语料进行二次加工。
背景与挑战
背景概述
粤语作为一种重要的汉语方言,在自然语言处理领域长期面临资源匮乏的困境。wiki-yue-high-quality数据集由专注于低资源语言处理的团队于2025年创建,基于粤语维基百科原始数据进行深度加工。该数据集的核心价值在于通过完整模板扩展和标准化清洗流程,解决了原始数据中模板未展开和冗余信息过多的问题,为粤语语言模型的训练提供了高质量的文本资源。该数据集的推出显著改善了粤语NLP研究的基线条件,对保护语言多样性及促进方言计算语言学发展具有深远意义。
当前挑战
粤语维基百科数据的处理面临双重挑战。在领域问题层面,低资源语言的特性导致数据稀疏性严重,模板嵌套结构复杂,且存在大量非标准表达,这对语言模型的语义理解能力提出极高要求。在构建技术层面,原始数据中的动态模板扩展涉及多级引用解析,而版面元素的精准剥离需要设计复杂的启发式规则,任何处理不当都会导致语义完整性受损。此外,粤语特有的方言用字和语法结构也增加了数据清洗的难度,需要开发专门的文本规范化流程。
常用场景
经典使用场景
在自然语言处理领域,低资源语言的语料库构建一直面临严峻挑战。wiki-yue-high-quality数据集通过完整的模板扩展和无关文本清理,为粤语(Yue Chinese)这一低资源语言提供了高质量的文本语料,成为训练粤语语言模型的黄金标准。该数据集特别适用于需要精确语言建模的场景,如机器翻译系统训练、语音识别模型优化等。
解决学术问题
该数据集有效解决了粤语自然语言处理中的两大核心问题:一是通过模板扩展弥补了原始维基百科数据中常见的词汇缺失现象,二是通过清理无关文本提高了语料质量。这不仅为低资源语言处理提供了方法论参考,更填补了粤语计算语言学研究的语料空白,对保护语言多样性具有重要意义。
衍生相关工作
围绕该数据集已产生多项重要研究,包括基于对比学习的粤语预训练模型YueBERT、粤语文本生成系统CantoGPT等。这些工作不仅验证了数据集的质量,更推动了低资源语言处理技术的发展。香港科技大学团队利用该数据集进行的方言保护研究,为全球濒危语言数字化提供了宝贵经验。
以上内容由遇见数据集搜集并总结生成


