HuggingFaceH4/ultrachat_200k
收藏Hugging Face2024-02-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/HuggingFaceH4/ultrachat_200k
下载链接
链接失效反馈资源简介:
UltraChat 200k数据集是从UltraChat数据集中经过严格筛选得到的,用于训练Zephyr-7B-β模型。处理过程包括数据子集选择、语法错误修正和删除不合适的对话内容。数据集分为四个部分,适用于监督微调和生成排名。每个部分的数据量和存储格式也进行了详细说明。
The UltraChat 200k dataset is rigorously curated from the original UltraChat dataset for training the Zephyr-7B-β model. The data processing procedures include subset selection, grammatical error correction, and the removal of inappropriate conversational content. This dataset is divided into four partitions, which are suitable for supervised fine-tuning and generation ranking tasks. Detailed descriptions of the data volume and storage format for each partition are also provided.
提供机构:
HuggingFaceH4
原始信息汇总
数据集概述
基本信息
- 名称: UltraChat 200k
- 语言: 英语
- 许可证: MIT
- 大小: 100K<n<1M
- 任务类型: 文本生成
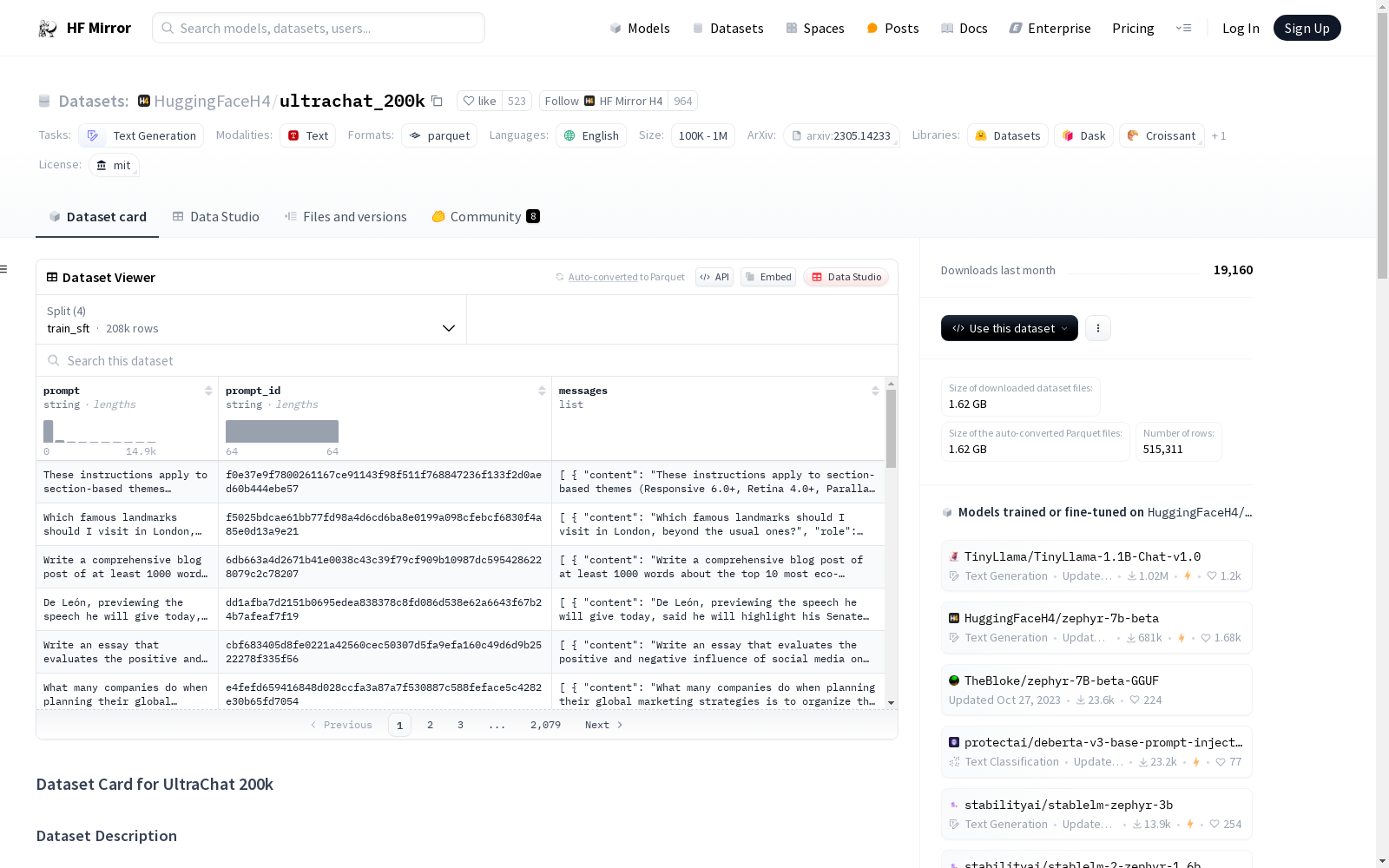
数据集结构
-
配置:
- 默认配置
- 训练数据:
train_sft,train_gen- 路径:
data/train_sft-*,data/train_gen-*
- 路径:
- 测试数据:
test_sft,test_gen- 路径:
data/test_sft-*,data/test_gen-*
- 路径:
- 训练数据:
- 默认配置
-
特征:
- prompt: 字符串类型
- prompt_id: 字符串类型
- messages: 列表类型
- content: 字符串类型
- role: 字符串类型
-
数据分割:
- train_sft: 207865个样本, 1397058554字节
- test_sft: 23110个样本, 154695659字节
- train_gen: 256032个样本, 1347396812字节
- test_gen: 28304个样本, 148276089字节
-
下载大小: 1624049723字节
-
数据集大小: 3047427114字节
使用场景
- 监督微调 (
sft) - 生成排名 (
gen) 使用技术如拒绝采样或PPO
数据示例
json { "prompt": "...", "messages": [ { "content": "...", "role": "user" }, { "content": "...", "role": "assistant" } ], "prompt_id": "..." }
搜集汇总
数据集介绍
构建方式
UltraChat 200k数据集是对原始UltraChat数据集的深度筛选与优化,旨在为监督微调提供更快速、准确的数据基础。该数据集的构建过程包括对语料的子集选择,以加快微调速度;对数据执行Truecasing处理,以修正语法错误;并移除助手回复中包含无情感或无观点表述的对话,以提升模型在事实性提示下的表现。
特点
该数据集具有四个分割,分别适用于监督微调(sft)和生成排序(gen)等任务。存储格式为parquet,每条记录包含提示信息、消息列表(包括内容和角色)、以及提示ID。数据集涵盖207,865条训练微调数据、23,110条测试微调数据、256,032条训练生成数据以及28,304条测试生成数据,总计超过300万条数据实例,保证了模型的训练质量和多样性。
使用方法
用户可以通过HuggingFace的库直接加载该数据集,并根据不同的任务需求选择相应的数据分割。数据集以parquet格式存储,便于高效的数据处理和访问。用户在进行监督微调或生成排序任务时,可以根据具体的任务配置和数据集结构进行相应的预处理和模型训练。
背景与挑战
背景概述
UltraChat 200k数据集,源于对UltraChat原始数据集的深度筛选,旨在为Zephyr-7B-β这一先进的7b聊天模型提供训练资源。UltraChat 200k的构建,依托于ChatGPT产生的140万对话样本,覆盖了广泛的话题。该数据集的创建过程包括子集选择以加快监督微调、数据真值化以降低语法错误率、以及对包含特定回复的对话进行剔除。该数据集自推出以来,对聊天机器人模型训练领域产生了显著影响,被广泛应用于监督微调与生成排序任务中。
当前挑战
在数据集构建过程中,研究人员面临了多重挑战。首先,如何从庞大的原始数据集中筛选出高质量、适合微调的子集,确保数据既具有代表性又足够精确。其次,数据真值化的过程要求对语法错误进行细致的校对,这是一项费时且需高度注意力的任务。此外,对话数据中非期望回复的识别与移除,也要求复杂的数据处理策略。在研究领域中,如何有效利用该数据集进行模型训练,以及如何评估模型的生成质量,都是当前面临的挑战。
常用场景
经典使用场景
在自然语言处理领域,UltraChat 200k数据集的典型应用场景是用于训练和微调聊天机器人模型,以便生成更加自然、流畅的对话。该数据集提供了大量经过精心筛选和处理的对话示例,涵盖了广泛的话题,从而使得模型能够在多样化的语境中学习有效的交流策略。
解决学术问题
UltraChat 200k数据集解决了学术研究中如何提高聊天机器人响应质量和语境适应性的问题。通过使用该数据集,研究者能够训练出能够处理复杂对话情景的模型,进而提升机器人在实际交流中的表现,这对于自然语言理解和生成领域具有重要意义。
衍生相关工作
UltraChat 200k数据集衍生出的相关工作包括了对聊天机器人模型的性能评估、对话系统的优化策略研究以及对话生成中的伦理和隐私问题探讨等,推动了自然语言处理领域的研究进展和实践应用。
以上内容由遇见数据集搜集并总结生成


