nace-ai/policy-proficiency-auc-completion
收藏Hugging Face2026-04-02 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/nace-ai/policy-proficiency-auc-completion
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: source
dtype: string
- name: md_file
dtype: string
splits:
- name: train
num_bytes: 974469
num_examples: 2912
- name: test
num_bytes: 243050
num_examples: 728
download_size: 422037
dataset_size: 1217519
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
提供机构:
nace-ai
搜集汇总
数据集介绍
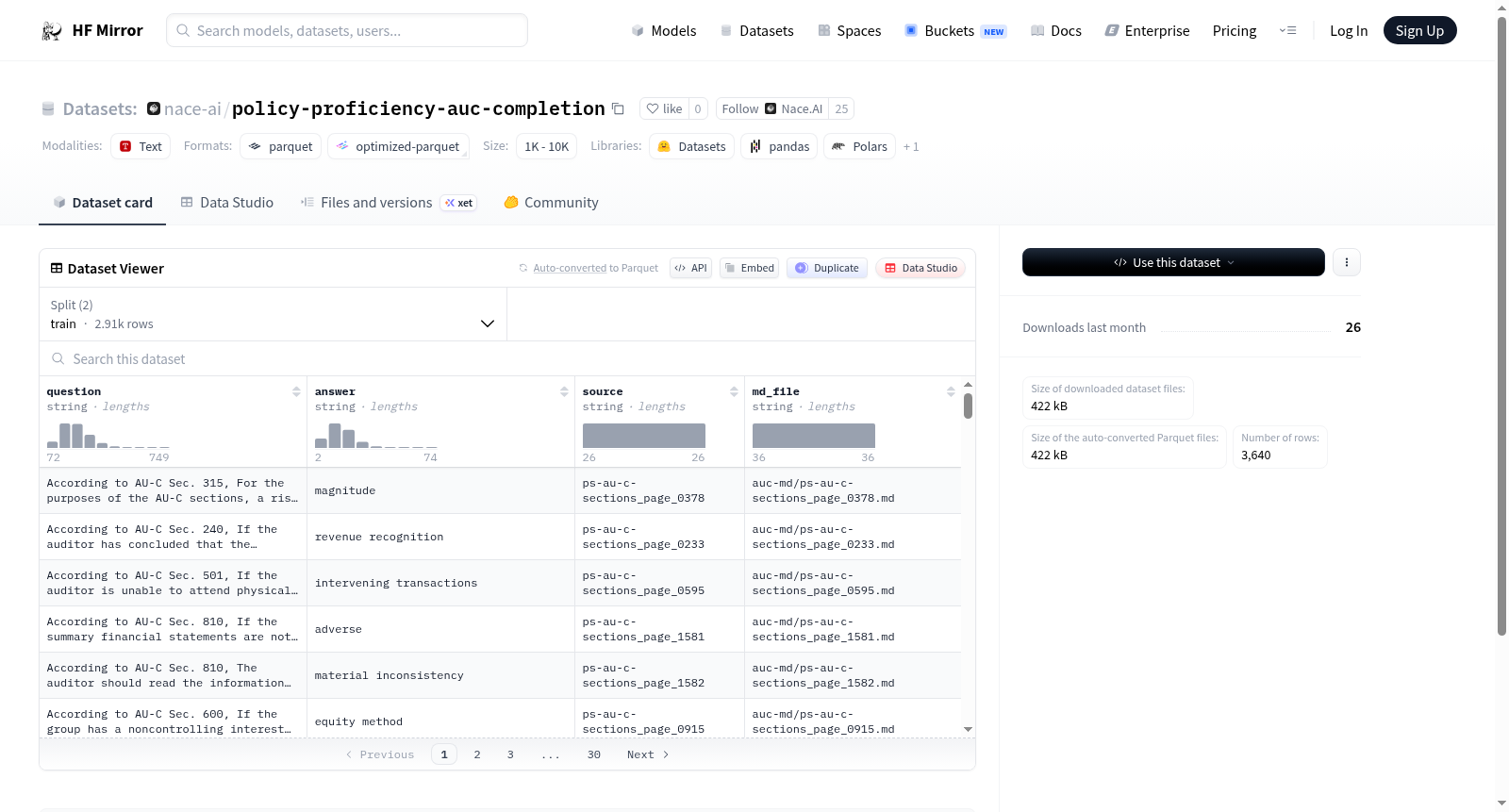
构建方式
在公共政策与治理领域,政策文件的解读与问答能力是评估专业素养的关键。policy-proficiency-auc-completion数据集通过系统收集与整理,构建了一个涵盖广泛政策主题的问答对集合。其构建过程基于真实政策文档,包括政府报告、法规条文及官方指南,从中提取核心问题并生成标准答案,确保内容的权威性与准确性。数据经过人工校验与结构化处理,划分为训练集与测试集,为模型训练与评估提供了可靠基础。
特点
该数据集以其专业性与实用性著称,每个样本包含问题、答案、来源及原始文档引用,结构清晰且易于追溯。数据覆盖多元政策领域,从经济调控到社会服务,体现了政策知识的广度与深度。其规模适中,包含超过3600个样本,平衡了训练效率与内容代表性,同时通过严格的来源标注增强了数据的可信度与可解释性,适用于需要高精度政策理解的任务。
使用方法
使用policy-proficiency-auc-completion数据集时,可将其应用于政策问答系统的开发与优化。用户可直接加载训练集进行模型微调,利用测试集评估模型在政策理解与生成方面的性能。数据集支持端到端的问答流程,鼓励结合来源信息进行多模态分析,以提升答案的准确性与上下文相关性。在学术与实务场景中,它可作为基准工具,推动政策智能辅助系统的创新与应用。
背景与挑战
背景概述
在自然语言处理与政策分析交叉领域,政策熟练度评估数据集(policy-proficiency-auc-completion)的构建标志着对专业领域知识自动化理解与生成能力测评的深化。该数据集由相关研究机构于近期开发,旨在通过结构化的问题-答案对,系统考察模型在政策文本理解、逻辑推理与内容补全方面的表现。其核心研究问题聚焦于如何量化模型对复杂政策文档的掌握程度,从而推动智能系统在公共管理、法律咨询等高风险领域的可靠应用。这一数据集的问世,为政策语义解析与生成任务提供了基准测试工具,促进了领域适应性语言模型的发展。
当前挑战
政策熟练度评估数据集所应对的领域挑战在于,政策文本通常蕴含严谨的法律逻辑、专业术语及隐含语境,要求模型不仅具备表层语义匹配能力,更需深入理解条款间的关联性与适用边界。构建过程中的挑战则体现在多源政策文档的收集与标准化处理上,包括如何从异构格式(如Markdown文件)中提取高质量问答对、确保答案的准确性与一致性,以及平衡数据覆盖的广度与深度,以全面反映政策领域的复杂性。这些挑战共同指向了专业领域知识表示与推理的瓶颈问题。
常用场景
经典使用场景
在政策文本分析与智能问答领域,该数据集为研究人员提供了一个结构化的问答对集合,专门用于训练和评估模型在政策文档理解与自动回答方面的能力。通过包含问题、答案、来源及原始Markdown文件,它支持模型学习从复杂政策文本中提取关键信息,并生成准确、连贯的回应,从而在政策咨询、自动化文档处理等场景中发挥核心作用。
解决学术问题
该数据集有效解决了政策文本中信息检索与语义理解的学术挑战,通过提供高质量的标注数据,促进了自然语言处理模型在特定领域知识上的泛化能力。它帮助研究者探索如何从非结构化政策文档中自动生成问答对,提升了模型对专业术语和复杂逻辑的解析精度,为政策智能系统的开发奠定了数据基础,推动了领域自适应学习与知识图谱构建的研究进展。
衍生相关工作
围绕该数据集,衍生了一系列经典研究工作,包括基于深度学习的政策问答模型优化、跨领域政策文本的迁移学习框架,以及结合知识增强的政策语义解析方法。这些工作不仅提升了模型在政策场景下的性能,还推动了开放域问答系统向专业化、细粒度方向发展,为后续政策智能助手、自动化法规分析工具的开发提供了理论支撑与实践范例。
以上内容由遇见数据集搜集并总结生成


