peft-unit-test-generation-experiments
收藏Hugging Face2025-07-19 更新2025-07-20 收录
下载链接:
https://huggingface.co/datasets/fals3/peft-unit-test-generation-experiments
下载链接
链接失效反馈官方服务:
资源简介:
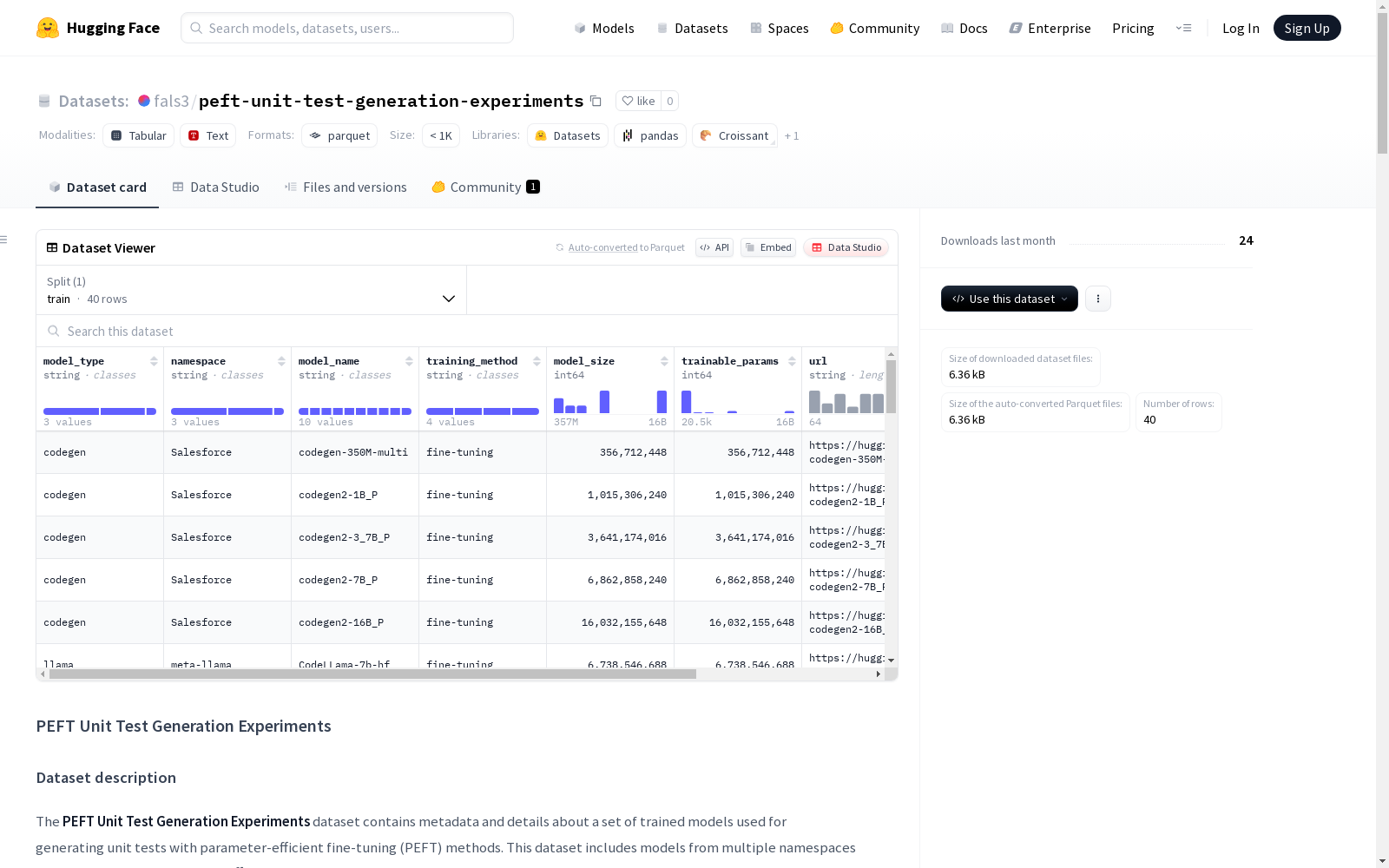
PEFT单元测试生成实验数据集包含了一系列使用参数效率调整(PEFT)方法训练的模型的元数据和详细信息。这些模型来自多个命名空间,具有不同的大小,并且使用了不同的调整方法,为单元测试生成研究提供了一个全面的数据资源。
创建时间:
2025-07-19
原始信息汇总
PEFT Unit Test Generation Experiments 数据集概述
数据集基本信息
- 数据集名称: PEFT Unit Test Generation Experiments
- 数据集大小: 6,257字节
- 下载大小: 4,879字节
- 样本数量: 40
- 数据分割: train
- 大小分类: n<1K
数据集描述
该数据集包含用于生成单元测试的参数高效微调(PEFT)方法的训练模型元数据和详细信息。数据集涵盖多个命名空间和不同大小的模型,采用多种调优方法训练,为单元测试生成研究提供全面资源。
数据结构
数据字段
| 字段名称 | 描述 |
|---|---|
model_type |
基础模型的类型或架构(如codegen、starcoder)。 |
namespace |
创建或发布基础模型的组织或团体(如Salesforce、meta-llama)。 |
model_name |
模型的具体名称或标识符。 |
training_method |
用于训练的PEFT方法(如全微调、LoRA、IA³)。 |
model_size |
模型大小,通常以参数数量衡量(如350M、7B)。 |
trainable_params |
特定调优方法和超参数的可训练参数数量。 |
url |
模型仓库的直接链接。 |
doi |
与训练模型关联的数字对象标识符。 |
训练超参数
模型无关超参数
| 超参数 | 方法 | 值 |
|---|---|---|
| 通用参数 | ||
| Optimizer | - | AdamW |
| LR schedule | - | Linear |
| LR warmup ratio | - | 0.1 |
| Batch size | - | 1 |
| Gradient accumulation steps | - | 8 |
| # Epochs | - | 3 |
| Precision | - | Mixed |
| Learning rate | Full fine-tuning | 5E-5 |
| Learning rate | LoRA | 3E-4 |
| Learning rate | (IA)³ | 3E-4 |
| Learning rate | Prompt tuning | 3E-3 |
| 方法特定参数 | ||
| Alpha | LoRA | 32 |
| Dropout | LoRA | 0.1 |
| Rank | LoRA | 16 |
| Virtual tokens | Prompt tuning | 20 |
模型特定超参数
| 超参数 | 方法 | 模型 | 值 |
|---|---|---|---|
| Targeted attention modules | LoRA, (IA)³ | codegen-350M-multi | qkv_proj |
| Targeted attention modules | LoRA, (IA)³ | Salesforce/codegen2-1B_P | qkv_proj |
| Targeted attention modules | LoRA, (IA)³ | Salesforce/codegen2-3_7B_P | qkv_proj |
| Targeted attention modules | LoRA, (IA)³ | Salesforce/codegen2-7B_P | qkv_proj |
| Targeted attention modules | LoRA, (IA)³ | Salesforce/codegen2-16B_P | qkv_proj |
| Targeted attention modules | LoRA, (IA)³ | meta-llama/CodeLlama-7b-hf | q_proj, v_proj |
| Targeted attention modules | LoRA, (IA)³ | bigcode/starcoderbase | c_attn |
| Targeted attention modules | LoRA, (IA)³ | bigcode/starcoder2-3b | q_proj, v_proj |
| Targeted attention modules | LoRA, (IA)³ | bigcode/starcoder2-7b | q_proj, v_proj |
| Targeted attention modules | LoRA, (IA)³ | bigcode/starcoder2-15b | q_proj, v_proj |
| Targeted feedforward modules | (IA)³ | codegen-350M-multi | fc_out |
| Targeted feedforward modules | (IA)³ | Salesforce/codegen2-1B_P | fc_out |
| Targeted feedforward modules | (IA)³ | Salesforce/codegen2-3_7B_P | fc_out |
| Targeted feedforward modules | (IA)³ | Salesforce/codegen2-7B_P | fc_out |
| Targeted feedforward modules | (IA)³ | Salesforce/codegen2-16B_P | fc_out |
| Targeted feedforward modules | (IA)³ | meta-llama/CodeLlama-7b-hf | down_proj |
| Targeted feedforward modules | (IA)³ | bigcode/starcoderbase | mlp.c_proj |
| Targeted feedforward modules | (IA)³ | bigcode/starcoder2-3b | q_proj, c_proj |
| Targeted feedforward modules | (IA)³ | bigcode/starcoder2-7b | q_proj, c_proj |
| Targeted feedforward modules | (IA)³ | bigcode/starcoder2-15b | q_proj, c_proj |
训练运行可视化
搜集汇总
数据集介绍
构建方式
在参数高效微调技术快速发展的背景下,PEFT单元测试生成实验数据集通过系统化采集不同架构的预训练模型元数据构建而成。该数据集精选了包括Salesforce、Meta等机构开发的40个模型变体,涵盖CodeGen、StarCoder等多种模型架构,并详细记录了各模型采用的LoRA、IA³等微调方法及其超参数配置。研究人员通过统一训练框架下的对比实验,确保了不同模型间数据的可比性,所有训练过程均采用AdamW优化器和线性学习率调度策略。
使用方法
研究者可通过HuggingFace平台直接下载该数据集,其标准化的JSON格式便于进行批量数据处理。典型应用场景包括:通过model_type字段筛选特定架构模型进行横向对比;利用training_method字段分析不同微调技术的性能差异;结合trainable_params字段研究参数效率与模型效果的关系。数据集提供的训练损失曲线可视化结果,可辅助研究者快速评估不同配置下的模型收敛特性。对于进阶研究,建议结合原始论文DOI进行深度分析。
背景与挑战
背景概述
PEFT Unit Test Generation Experiments数据集聚焦于参数高效微调(PEFT)技术在单元测试生成领域的应用研究。该数据集由多个组织联合构建,收录了包括Salesforce、meta-llama等机构开发的多种模型架构,涵盖codegen、starcoder等不同规模的预训练模型。数据集通过记录LoRA、IA³等前沿微调方法的超参数配置和训练指标,为软件工程中自动化测试生成的研究提供了标准化评估基准。其核心价值在于探索大语言模型在代码理解与测试用例生成任务中,如何通过参数高效的方式实现知识迁移。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,单元测试生成需要模型同时具备代码语义理解能力和测试逻辑构建能力,而不同编程语言的语法差异和测试范式多样性加剧了模型泛化难度。在构建过程中,参数高效微调涉及复杂的模块选择策略,如注意力机制与前馈网络的目标模块确定需结合模型架构特性;此外,超参数组合对训练效率的影响、不同规模模型的显存优化等问题,均需通过大量实验验证才能建立可靠基准。
常用场景
经典使用场景
在软件工程领域,自动化单元测试生成是提升开发效率的关键技术。该数据集通过整合多种参数高效微调(PEFT)方法训练的模型,为研究者提供了丰富的实验基础。经典使用场景包括比较不同PEFT方法(如LoRA、IA³)在代码生成任务中的性能差异,以及探索模型规模与测试生成质量之间的关联性。
解决学术问题
该数据集有效解决了大语言模型在单元测试生成中面临的参数效率与计算成本平衡问题。通过系统记录不同架构模型(如CodeLlama、StarCoder)的微调参数和训练指标,为研究社区提供了量化分析PEFT方法对测试覆盖率、代码语义理解等关键指标影响的基准数据,填补了该领域标准化评估框架的空白。
实际应用
在实际开发环境中,数据集支撑的模型可集成至持续集成流程,实现智能测试用例生成。企业级应用包括自动补全开发者的测试代码、检测边缘案例以及优化测试套件的执行效率。特别适用于需要快速迭代的敏捷开发场景,显著降低人工编写测试用例的时间成本。
数据集最近研究
最新研究方向
在软件工程领域,单元测试生成一直是提升代码质量与开发效率的关键环节。PEFT Unit Test Generation Experiments数据集通过整合多种参数高效微调方法(如LoRA、IA³等)训练的模型元数据,为研究者提供了探索高效测试生成技术的宝贵资源。当前研究聚焦于如何利用这些轻量化微调策略,在降低计算成本的同时保持或提升测试用例的覆盖率和准确性。特别是针对不同规模的基础模型(如CodeLlama、StarCoder等),探索最优的微调模块组合与超参数配置,成为近期热点。这一方向的发展不仅能够推动自动化测试工具的进步,也为大模型在代码生成领域的实用化提供了重要参考。
以上内容由遇见数据集搜集并总结生成



{kind=link}
{kind=link}
{kind=link}
{kind=link}