open-index/open-github-issues
收藏Hugging Face2026-05-08 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/open-index/open-github-issues
下载链接
链接失效反馈官方服务:
资源简介:
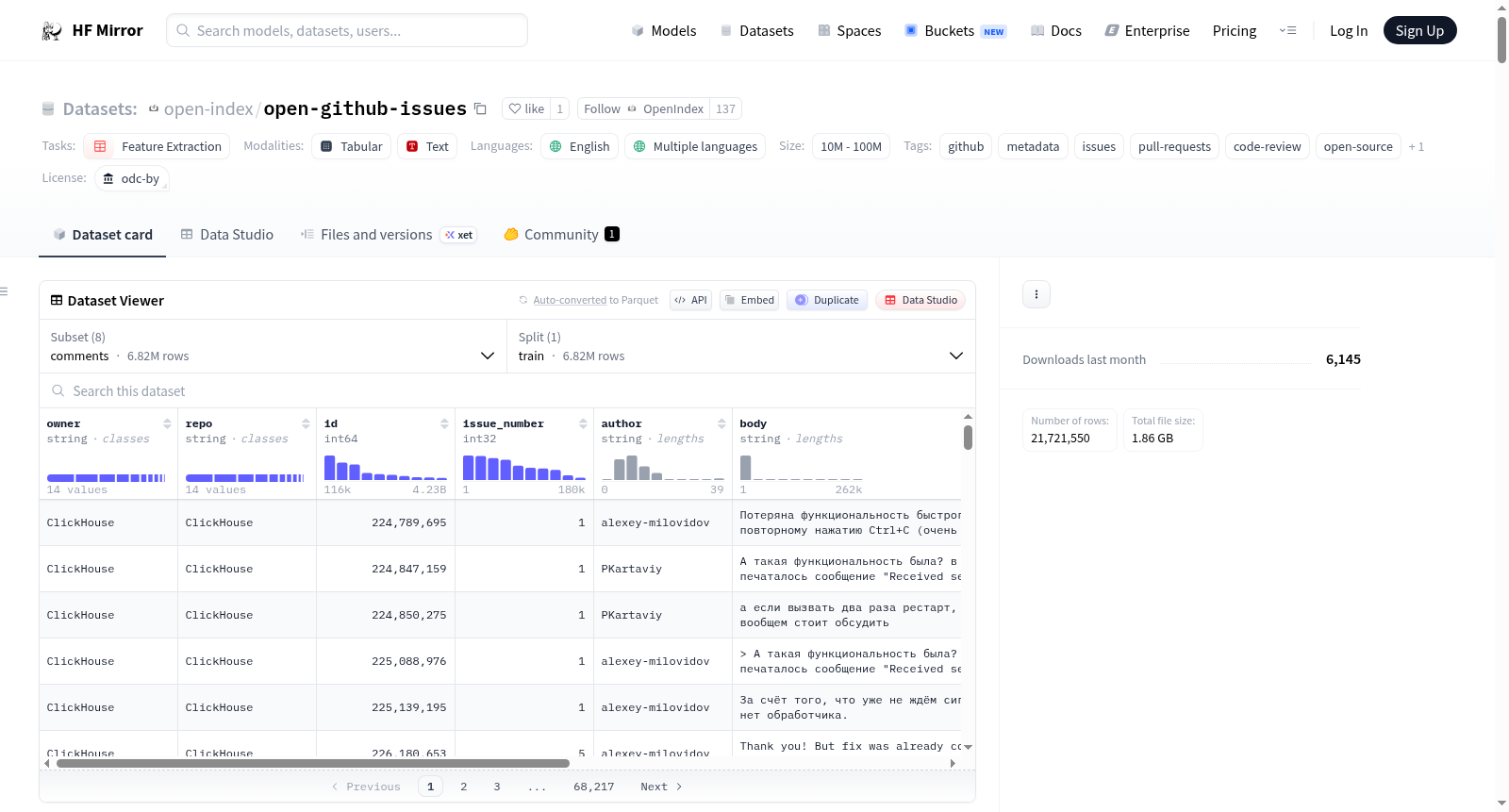
OpenGitHub Issues数据集包含15个公共GitHub仓库的完整开发元数据,从GitHub REST API和GraphQL API获取,转换为Parquet格式并托管于此以便于访问。目前存档包含8个表中的1830万行数据,压缩后为82.2 MB。每个问题、拉取请求、评论、代码审查、时间线事件、文件更改和CI状态检查都存储为单独的表,可以单独加载或一起查询。该数据集是OpenGitHub的配套数据集,用于特定仓库的完整画面:完整的问题线程、完整的PR审查对话、从开放到关闭的状态机。人们用它进行代码审查研究、项目健康指标、问题分类和软件工程过程挖掘。
The OpenGitHub Issues dataset contains the full development metadata of 15 public GitHub repositories, fetched from the GitHub REST API and GraphQL API, converted to Parquet and hosted here for easy access. Right now the archive has 18.3M rows across 8 tables in 82.2 MB of Zstd-compressed Parquet. Every issue, pull request, comment, code review, timeline event, file change, and CI status check is stored as a separate table you can load individually or query together. This is the companion to OpenGitHub, which gives you the full picture for specific repos: complete issue threads, full PR review conversations, the state machine from open to close. People use it for code review research, project health metrics, issue triage and classification, and software engineering process mining.
提供机构:
open-index
搜集汇总
数据集介绍
构建方式
在开源软件工程领域,全面记录项目开发过程的数据集对于理解协作模式至关重要。OpenGitHub Issues数据集的构建过程采用了双重API策略,通过GitHub的REST API进行批量数据获取,利用增量分页和并行抓取机制高效收集议题、评论等基础信息;同时借助GraphQL API获取每个项目的详细元数据,如代码审查、时间线事件和文件变更等。数据同步管道采用多令牌轮换机制以分散速率限制压力,确保采集过程的稳健性。所有原始数据首先存入DuckDB进行临时存储,随后转换为Zstd压缩的Parquet格式,保持了数据的完整性和可访问性,未经过滤或去重,真实反映了开源项目的实际运作状态。
特点
该数据集的核心特征在于其深度与广度兼备的结构化设计。它涵盖了17个知名开源仓库的完整开发元数据,包含超过2170万行记录,分布于议题、拉取请求、评论、审查评论、审查决策、时间线事件、PR文件变更和提交状态八个独立表中。这种多表架构允许研究者分别或联合查询不同维度的信息,例如将代码审查的评论与具体的差异行关联,或追踪议题从开启到关闭的完整状态机转换。数据集特别保留了自动化机器人的活动记录,为分析真实的软件工程流程提供了未经修饰的原始素材,其时间线事件表更是细致捕捉了标签变更、分配指派、合并引用等每一个状态转换细节。
使用方法
该数据集的使用具有高度的灵活性,支持多种主流数据处理工具。用户可通过Hugging Face的`datasets`库以流式或批量方式加载数据,或直接利用DuckDB的`read_parquet`函数从远程读取Parquet文件进行SQL查询,无需预先下载整个数据集。例如,可以轻松执行跨仓库的议题作者统计、拉取请求合并率分析或标签使用趋势的时间序列挖掘。对于特定研究需求,用户可以选择性加载单个仓库或特定数据表,例如仅获取`facebook/react`仓库的拉取请求数据。数据集采用标准Parquet布局,与Pandas、`huggingface_hub`等工具无缝兼容,为软件工程实证研究、项目健康度评估和代码审查分析提供了即用型高质量数据源。
背景与挑战
背景概述
在软件工程与开源协作研究领域,对大规模开发过程数据的系统性采集与分析,长期以来是理解项目演化与团队协作模式的关键。OpenGitHub Issues数据集由Open-Index研究团队于2026年创建,旨在通过整合GitHub平台上17个知名开源项目的完整开发元数据,构建一个覆盖议题、拉取请求、代码评审及时间线事件的全方位数据仓库。该数据集的核心研究问题聚焦于开源软件生命周期中的协作动态、代码评审效率与项目健康度评估,为软件工程实证研究提供了前所未有的细粒度数据支持,显著推动了开源生态量化分析领域的方法论发展。
当前挑战
该数据集致力于解决软件工程领域中开源协作过程量化分析的挑战,其核心问题在于如何从海量异构的协作数据中提取可解释的模式,以支撑代码评审质量评估、议题分类与项目健康度监测等任务。构建过程中的主要挑战体现在数据采集与整合层面:需协调GitHub REST与GraphQL双API以获取完整元数据,处理增量同步与海量历史数据的并行获取;同时需应对数据结构的高度异构性,如时间线事件的多样类型与嵌套JSON字段,并在保持数据原始性的前提下,实现跨表关联与高效存储。此外,数据规模达数千万行,在确保查询性能与存储效率之间需进行精细权衡。
常用场景
经典使用场景
在软件工程研究领域,OpenGitHub Issues数据集为代码审查分析提供了丰富的结构化数据。通过整合问题、拉取请求、评论及时间线事件等多元信息,研究人员能够深入探究代码审查过程中的交互模式与决策机制。该数据集支持对审查效率、代码变更质量以及团队协作动态的量化评估,为理解开源项目的开发流程奠定了实证基础。
实际应用
在实际开发场景中,OpenGitHub Issues数据集被广泛应用于构建智能化的项目管理工具。基于其提供的完整开发历史,团队可开发自动化问题分类系统、预测代码合并风险的工具,以及可视化项目健康度的仪表盘。这些应用有助于优化开源社区的协作流程,提升问题响应速度与代码审查质量,为大型项目的可持续维护提供数据驱动的决策支持。
衍生相关工作
围绕该数据集已衍生出多项经典研究工作,包括基于时间线事件序列的软件过程挖掘算法、利用代码审查评论的自动化质量评估模型,以及结合拉取请求元数据的开发者贡献度分析框架。这些研究不仅深化了对开源协作机制的理解,还推动了智能软件工程工具的发展,为后续的代码审查自动化与项目风险管理研究提供了重要参考。
以上内容由遇见数据集搜集并总结生成


