Panoptic nuScenes
收藏arXiv2021-12-24 更新2024-06-21 收录
下载链接:
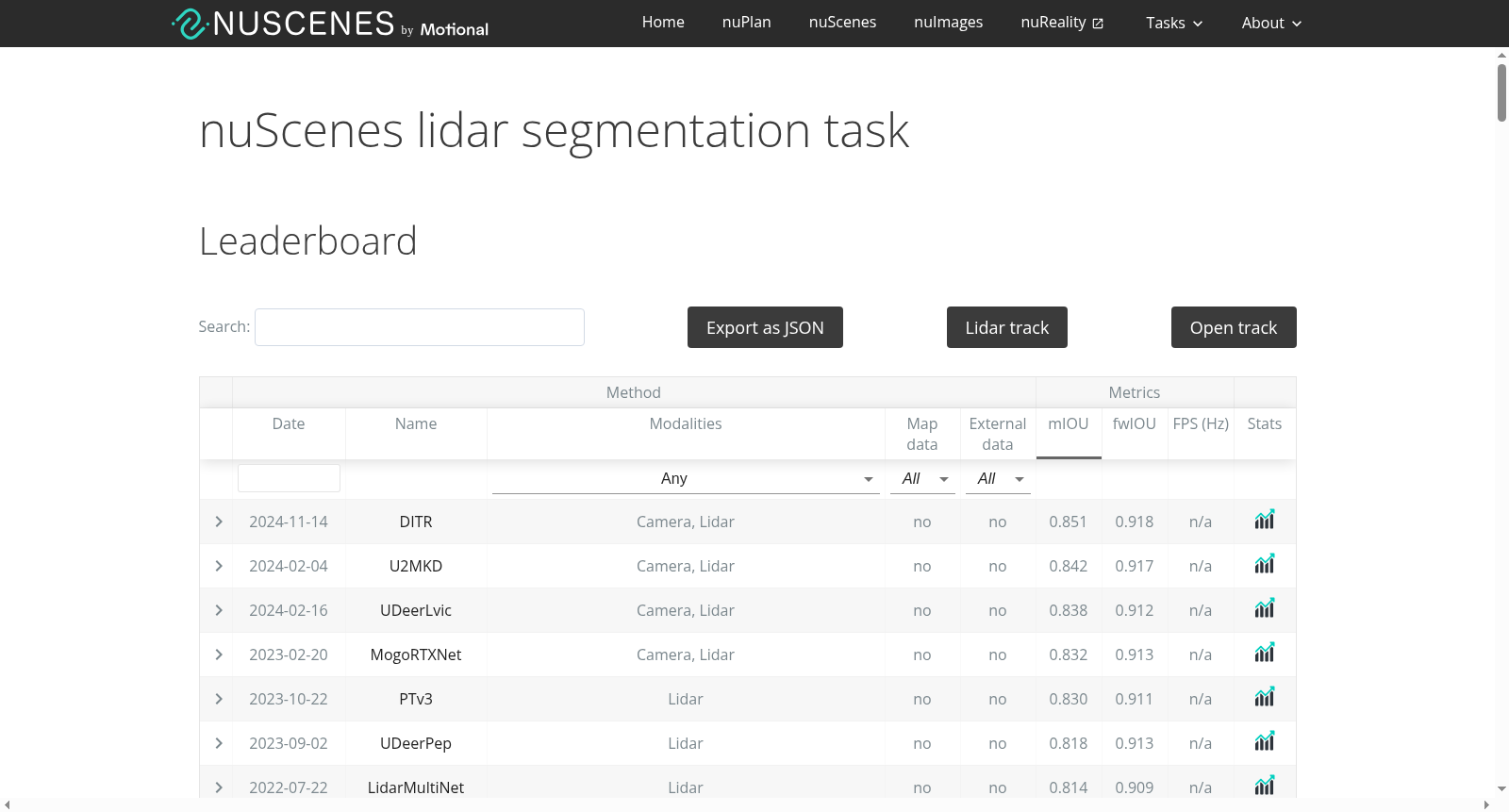
http://www.nuscenes.org/lidar-segmentation
下载链接
链接失效反馈官方服务:
资源简介:
Panoptic nuScenes是由慕尼黑工业大学开发的一个大规模激光雷达全景分割和跟踪基准数据集。该数据集扩展自流行的nuScenes数据集,包含了1000个场景,覆盖新加坡和波士顿的多个地点,具有高度的地理多样性。数据集包含11亿个标注的激光雷达点,涵盖32个语义类别,用于支持自动驾驶中的全景场景理解任务。Panoptic nuScenes不仅包含静态场景的分割,还特别关注动态对象的跟踪,为全景跟踪任务提供了丰富的实例和时间一致的标注。此数据集的应用领域主要集中在自动驾驶技术,旨在解决复杂城市环境中动态对象的准确识别和跟踪问题。
Panoptic nuScenes is a large-scale LiDAR panoptic segmentation and tracking benchmark dataset developed by the Technical University of Munich. It is extended from the popular nuScenes dataset, containing 1000 scenes collected across multiple locations in Singapore and Boston, with high geographic diversity. The dataset includes 1.1 billion annotated LiDAR points spanning 32 semantic categories, supporting panoptic scene understanding tasks in autonomous driving. Panoptic nuScenes not only covers segmentation of static scenes but also places special emphasis on tracking dynamic objects, providing rich instance-level and temporally consistent annotations for panoptic tracking tasks. Its application fields are mainly focused on autonomous driving technology, aiming to solve the problems of accurate recognition and tracking of dynamic objects in complex urban environments.
提供机构:
慕尼黑工业大学
创建时间:
2021-09-09
搜集汇总
数据集介绍
构建方式
在自动驾驶领域,激光雷达点云的全景分割与跟踪任务对场景理解至关重要。Panoptic nuScenes数据集基于nuScenes数据集扩展而成,通过人工标注40,000个关键帧中的11亿个激光雷达点,构建了包含32个语义类别的点级标注。标注过程中,利用现有3D边界框初始化物体类别的语义标签,并通过多轮手动修正与验证,确保点云语义与实例标注的精确性。实例标签通过结合点级语义与边界框信息生成,并利用轨迹ID保证时间一致性,最终形成涵盖语义分割、全景分割与全景跟踪任务的统一标注体系。
特点
Panoptic nuScenes数据集以其规模与多样性著称,包含来自新加坡和波士顿的1,000个场景,覆盖密集城市环境与多种动态物体。数据集提供23个物体类别与9个背景类别的点级标注,并包含超过120万个实例,其中动态物体实例数量显著高于现有数据集。标注的时空一致性支持全景跟踪任务,而细粒度的类别划分(如警车、救护车等长尾类别)增强了数据集的挑战性。此外,数据采集使用360度覆盖的传感器,包括雷达数据,进一步丰富了多模态研究潜力。
使用方法
该数据集支持激光雷达语义分割、全景分割与全景跟踪三大任务,每项任务均提供独立的评估协议与在线评测服务器。研究者可通过官方划分的训练集与验证集开发模型,并使用隐藏测试集提交结果进行公平比较。数据使用需遵循任务特定规范:语义分割任务评估点级类别预测;全景分割任务需同时输出点级语义与实例ID;全景跟踪任务则要求预测时间一致的实例轨迹。评估指标包括mIoU、PQ及新颖的PAT指标,其中PAT结合全景质量与跟踪质量,有效衡量实例级跟踪性能。
背景与挑战
背景概述
Panoptic nuScenes数据集于2021年由Motional与弗赖堡大学的研究团队联合推出,旨在为自动驾驶领域的激光雷达全景分割与跟踪任务提供大规模基准。该数据集基于广受欢迎的nuScenes数据集扩展,涵盖了新加坡和波士顿多个城市的密集城市场景,包含1000个场景、1.1亿个标注点,并提供了32个语义类别(包括23个物体类别和9个背景类别)的点级标注。其核心研究问题在于解决动态城市环境中全景场景理解与多目标跟踪的融合挑战,通过提供时序一致的实例标注,推动了激光雷达点云处理技术向更精细、更连贯的感知方向发展。该数据集的多样性与规模显著提升了相关模型的泛化能力,已成为自动驾驶感知研究中的重要基准之一。
当前挑战
Panoptic nuScenes数据集主要应对两大挑战:在领域问题层面,它致力于解决激光雷达全景分割与跟踪这一复杂任务,其中涉及在点云中同时实现语义分割、实例分割以及跨帧的时序实例关联。现有方法往往难以在密集动态场景中保持长时跟踪的一致性,且对罕见类别(如救护车、警车)的识别效果有限。在构建过程中,标注团队面临点云稀疏性、物体遮挡与重叠带来的标注歧义,以及如何高效融合3D边界框与点级语义信息以生成高质量全景标注的难题。此外,数据集的多样性虽提升了泛化性,但也引入了场景复杂度与标注一致性的平衡挑战,需通过多轮人工校验确保时序标注的准确性。
常用场景
经典使用场景
在自动驾驶与机器人导航领域,Panoptic nuScenes数据集为激光雷达点云的语义分割、全景分割及全景跟踪任务提供了标准化评估基准。该数据集通过融合点级语义标注与时间一致的实例标识,支持对动态城市环境中移动物体的精细化识别与轨迹追踪研究。其经典应用场景包括开发端到端的全景感知模型,以及评估不同算法在复杂交通场景下的鲁棒性与准确性。
衍生相关工作
基于Panoptic nuScenes数据集,学术界衍生出多项经典研究工作,例如EfficientLPS提出的高效激光雷达全景分割架构、PolarSeg-Panoptic基于极坐标鸟瞰图的全景分割方法,以及4D-PLS利用时序点云聚类的全景跟踪模型。这些工作通过引入新颖的网络模块、投影表示与关联策略,显著提升了点云全景理解任务的性能,并推动了端到端学习与多模态融合技术的进一步发展。
数据集最近研究
最新研究方向
在自动驾驶领域,激光雷达全景分割与跟踪作为环境感知的核心任务,正日益受到学术界与工业界的广泛关注。Panoptic nuScenes数据集的推出,以其大规模、高多样性的城市场景标注,为这一方向的研究提供了关键支撑。当前的前沿研究聚焦于端到端全景跟踪模型的优化,旨在克服传统方法中检测与跟踪任务分离导致的性能瓶颈。例如,结合卡尔曼滤波器的EfficientLPS方法在实例级跟踪一致性上表现突出,而基于极坐标鸟瞰图表示的PolarSeg-Panoptic则在分割精度上取得进展。同时,新型评估指标如实例中心化的PAT(Panoptic Tracking)被提出,以更全面地衡量跟踪碎片化与长期一致性,推动模型在动态复杂环境中的鲁棒性提升。这些进展不仅加速了激光雷达全景理解技术的发展,也为自动驾驶系统在真实世界中的安全部署奠定了理论基础。
相关研究论文
- 1Panoptic nuScenes: A Large-Scale Benchmark for LiDAR Panoptic Segmentation and Tracking慕尼黑工业大学 · 2021年
以上内容由遇见数据集搜集并总结生成


