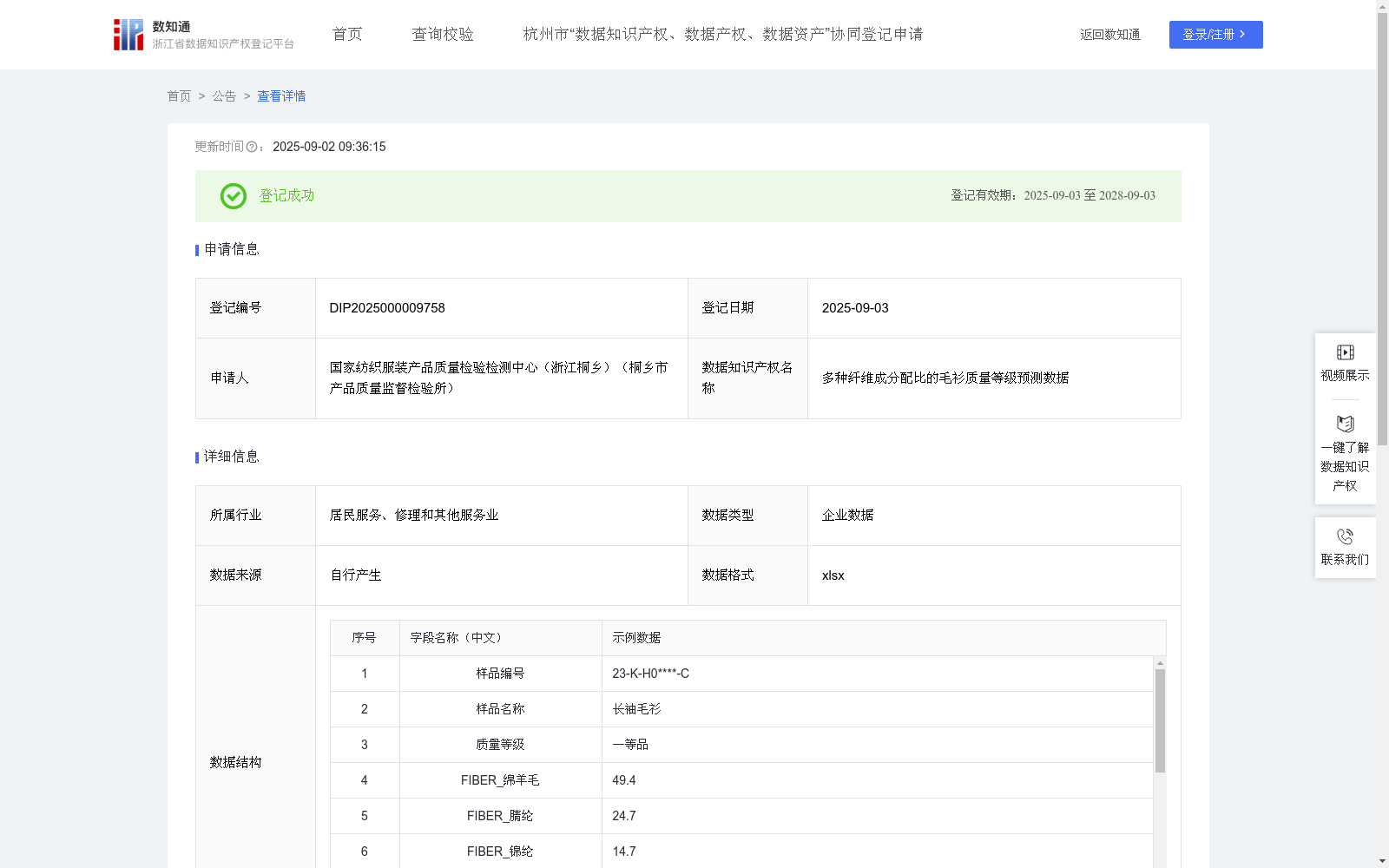
多种纤维成分配比的毛衫质量等级预测数据
收藏浙江省数据知识产权登记平台2025-09-02 更新2025-09-06 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/173741
下载链接
链接失效反馈官方服务:
资源简介:
本数据应用于毛衫类纺织品的智能制造与质量评估体系中,其核心价值在于能够处理和分析包含天然动物纤维、人工合成纤维等多种复杂成分配比的毛衫产品。通过数据模型对产品纤维成分进行深度解析,自动化预测其质量等级,该应用不仅适用于传统羊毛、羊绒类毛衫,同样能够精准评估由聚酯纤维、粘纤等混合材料制成的新型毛衫,为企业的生产质控、新品研发和市场策略提供了覆盖面更广、适应性更强的数据决策支持,推动了毛衫品类质检流程的全面智能化。"数据收集阶段覆盖了市场上多样化的毛衫产品,不仅包括传统意义上的毛制针织品,也广泛纳入了采用多种合成纤维混纺的新式针织衫。每个产品样本均通过实验室标准流程进行检测,获取其唯一的“样品编号”、产品“样品名称”,以及详细的纤维成分数据,并由权威质检员进行质量等级评定,确保了源头数据的多样性与准确性。
数据处理环节旨在将收集到的异构、多源的原始数据转化为标准、干净的机器学习可用格式。此过程专注于数据清洗与特征工程,对包含“FIBER_腈纶”、“FIBER_锦纶”、“FIBER_聚酯纤维”、“FIBER_粘纤”在内的多维度纤维成分数据进行标准化处理,构建统一的特征向量,从而形成一个能够全面反映不同材质毛衫内在属性的结构化数据集。
数据加工的核心是构建一个具有高泛化能力的等级预测模型,使其能够适应不同纤维配方的毛衫产品。该模型基于一个智能分类算法,通过学习大量样本数据来建立纤维成分与质量等级的关联,其预测逻辑可表达为公式:预测质量等级 = 等级预测分类器(FIBER_聚酯纤维, FIBER_腈纶, FIBER_锦纶, FIBER_粘纤, ...)。在此公式中,“预测质量等级”是模型对拥有特定“样品编号”的“样品名称”产品输出的最终结论;“等级预测分类器”是经过充分训练的随机森林算法,其中决策树数量为190,最大深度为15;而输入的各类纤维含量,如“FIBER_聚酯纤维”、“FIBER_腈纶”、“FIBER_锦纶”和“FIBER_粘纤”,则是模型进行判断的关键依据。"
提供机构:
国家纺织服装产品质量检验检测中心(浙江桐乡)(桐乡市产品质量监督检验所)
创建时间:
2025-06-30
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含2429条毛衫产品的纤维成分和质量数据,涵盖12种纤维类型的含量信息。其核心价值在于通过机器学习算法(随机森林)建立纤维成分与质量等级的映射关系,为毛衫制造业提供智能质量预测和产品研发的数据支持。
以上内容由遇见数据集搜集并总结生成


