TWIN
收藏arXiv2025-12-30 更新2025-12-31 收录
下载链接:
https://glab-caltech.github.io/twin/
下载链接
链接失效反馈官方服务:
资源简介:
TWIN是由加州理工学院团队构建的大规模视觉问答数据集,包含56.1万对家居物品图像对比查询,旨在提升视觉语言模型对细粒度视觉差异的感知能力。数据集涵盖1,836个物体实例的22,157张图像,通过人工标注和DreamBooth生成技术构建正负样本对,重点关注形状、纹理等细微特征差异。该数据集主要应用于增强模型在机器人交互、零售产品识别等需要精细视觉理解的场景中的表现,通过对比学习机制解决现有模型忽视细节差异的核心问题。
TWIN is a large-scale visual question answering dataset constructed by a team from the California Institute of Technology (Caltech). It contains 561,000 pairs of comparative queries for household item images, aiming to improve the perceptual ability of visual-language models for fine-grained visual differences. The dataset covers 22,157 images of 1,836 object instances, where positive and negative sample pairs are generated via manual annotation and DreamBooth generation technology, with an emphasis on subtle feature disparities such as shape and texture. This dataset is primarily applied to enhance model performance in scenarios requiring fine-grained visual understanding, including robot interaction and retail product recognition, and it resolves the core problem that existing models overlook subtle detail differences through contrastive learning mechanisms.
提供机构:
加州理工学院
创建时间:
2025-12-30
原始信息汇总
TWIN数据集概述
数据集简介
- 名称:TWIN
- 核心任务:训练视觉语言模型(VLM)通过判断两张相似图像是否显示同一物体实例来检测细微的视觉差异。
- 规模:包含561,000个以实例为中心的图像对查询。
- 构成:包含22,157张独特图像,涵盖1,836个物体实例,跨越36个常见物体类别。
数据集构建
- 实例定义:同一物理物体在不同视角、光照和背景下的图像集合。
- 数据来源:从Amazon Reviews中获取不同类别的物体实例。
- 难点构建:专注于收集“困难负样本对”,即外观相似的不同物体,由人工标注者协助收集。
- 可扩展性:其成对表述方式使得数据集能够随着物体实例数量的增加而良好扩展。
训练与应用
- 训练方法:使用强化学习对现有VLM进行后训练,仅依赖于成对分配的真值标签进行监督,无需任何描述性文本注释。
- 训练模型示例:在Qwen2.5-VL 3B Instruct模型上进行后训练。
- 数据规模重要性:分析表明,使用从5K到561K不同数量的TWIN样本对进行训练,模型在所有评估数据集上的性能持续提升。
评估基准:FGVQA
- 目的:评估模型在细粒度视觉问答上的跨领域泛化能力。
- 构成:包含六个基准数据集,总计12,000个查询,涵盖零售产品、动植物、地标、鸟类和艺术领域。
- TWIN-Eval:TWIN的评估集。
- ILIAS:大规模实例级图像检索测试数据集。
- Google Landmarks v2:地标识别数据集。
- MET:大都会艺术博物馆的艺术品图像检索数据集。
- CUB:专注于鸟类物种识别的细粒度分类数据集。
- Inquire:自然世界图像检索基准。
- 查询类型:
- 配对查询:展示两张图像,询问它们是否描绘同一实例、艺术品或物种。
- 多重查询:提供一张参考图像和三张候选图像,询问有多少张与参考图像匹配。
效果评估
- 定量结果:在TWIN上后训练的模型在FGVQA基准套件上显示出显著提升。在ILIAS上提升+18.3%,在TWIN-Eval上提升+17.2%。改进也迁移到未见过的领域,如在INQUIRE、CUB、MET和LANDMARKS数据集上观察到显著增益。
- 定性结果:后训练的模型能够区分基模型忽略的细微颜色差异(如数字和时钟指针)。
- 通用性保持:在FGVQA上性能的提升并未损害模型在通用VQA基准上的性能。
引用信息
-
论文标题:Same or Not? Enhancing Visual Perception in Vision-Language Models
-
作者:Damiano Marsili, Aditya Mehta, Ryan Y. Lin, Georgia Gkioxari
-
年份:2025
-
arXiv编号:2512.23592
-
arXiv链接:https://arxiv.org/abs/2512.23592
-
BibTeX:
@misc{marsili2025notenhancingvisualperception, title={Same or Not? Enhancing Visual Perception in Vision-Language Models}, author={Damiano Marsili and Aditya Mehta and Ryan Y. Lin and Georgia Gkioxari}, year={2025}, eprint={2512.23592}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2512.23592}, }
搜集汇总
数据集介绍
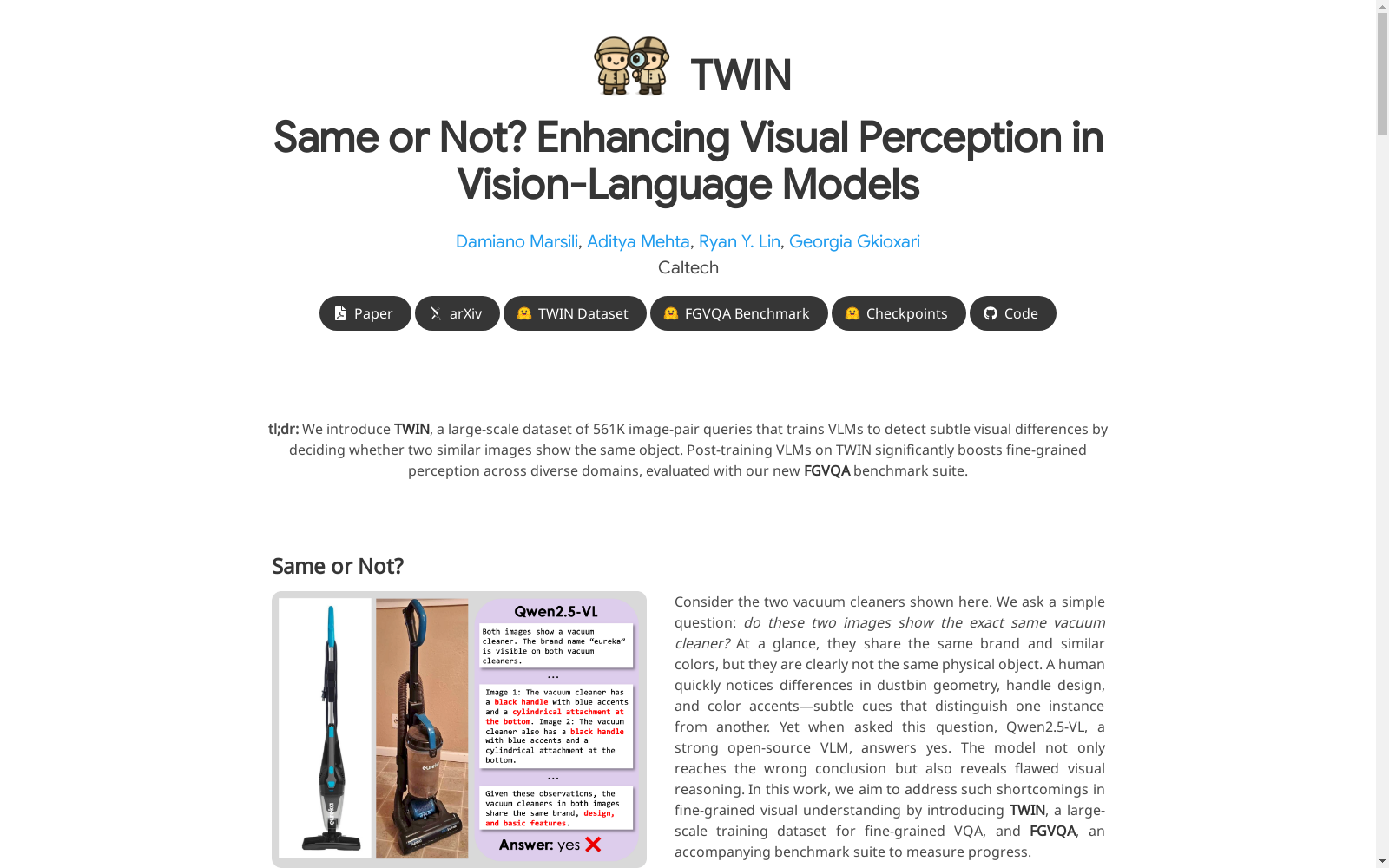
构建方式
在视觉语言模型领域,提升细粒度视觉理解能力是当前研究的核心挑战之一。TWIN数据集的构建旨在通过大规模图像对比较任务,强化模型对细微视觉差异的敏感度。该数据集从亚马逊评论平台中采集了1,836个日常物品实例,涵盖36个类别,并通过人工标注确保每个实例在不同视角、光照和背景下的图像多样性。数据集中包含56.1万个视觉问答查询,其中12.3万个为正样本对(同一实例),43.8万个为负样本对(不同实例)。负样本对进一步分为人工筛选的困难负样本和通过DreamBooth生成的合成负样本,以模拟细微的外观差异,从而构建一个既平衡又具有挑战性的训练资源。
特点
TWIN数据集的核心特点在于其专注于实例级别的细粒度视觉比较,而非传统的类别识别。该数据集通过精心设计的困难负样本对,迫使模型关注形状、纹理和部件几何等细微视觉线索,从而超越粗粒度的语义理解。其规模达到56.1万个查询,覆盖了电子产品、家具、时尚用品等多个日常物品领域,确保了数据的多样性和广泛性。此外,数据集的构建方式具有良好的可扩展性,实例数量的增加能高效转化为更多的成对查询,为大规模模型训练提供了坚实基础。这些特点共同使TWIN成为提升视觉语言模型感知精度的有效工具。
使用方法
TWIN数据集主要用于视觉语言模型的后续训练,以增强其细粒度视觉理解能力。典型的使用方法包括采用强化学习策略,如组相对策略优化(GRPO),对预训练模型进行微调。在训练过程中,模型接收一对图像,并生成推理解释和最终的是/否答案,判断它们是否描绘同一实例。奖励信号仅基于答案的正确性,无需额外的文本标注监督。经过TWIN训练的模型在FGVQA基准测试中展现出显著的性能提升,即使在艺术、动物、植物等未见领域也能实现有效的知识迁移。这种训练方法不仅提高了模型的感知精度,还保持了其在通用视觉问答任务上的原有能力。
背景与挑战
背景概述
在视觉-语言模型(VLMs)快速发展的背景下,模型在粗粒度视觉理解上表现出色,但在需要识别细微视觉差异的细粒度感知任务中仍存在明显不足。现有的大规模训练语料库多侧重于类别级别的识别,缺乏对实例级细节差异的关注。为弥补这一研究空白,加州理工学院的研究团队于2025年推出了TWIN数据集。该数据集包含56.1万对图像查询,核心研究问题是判断两幅视觉上高度相似的图像是否描绘了同一个物理对象实例,旨在通过强化模型对形状、纹理、部件几何等细微线索的注意力,系统性提升VLMs的细粒度视觉感知能力。TWIN的构建标志着视觉-语言模型从宏观语义理解向微观实例辨别的范式演进,为机器人学、具身交互等依赖精确视觉感知的领域提供了关键数据支撑。
当前挑战
TWIN数据集致力于解决视觉-语言模型在细粒度视觉问答(VQA)任务中的核心挑战,即如何准确区分外观高度相似但属于不同实例的对象,例如判断两个品牌相同、颜色相近但型号不同的吸尘器是否为同一产品。这一任务超越了传统的类别识别,要求模型具备对实例特异性细节的敏锐感知。在数据集构建过程中,研究团队面临多重挑战:首要挑战在于高效获取并标注海量的‘困难负样本对’,即视觉相似但实例不同的图像对,这需要结合CLIP模型初筛与人工精细校验,成本高昂且难以扩展;其次,为确保数据多样性并模拟真实世界的细微差异,团队需利用DreamBooth等生成模型合成保留对象整体外观但改变局部细节的负样本,并对其进行人工验证,以平衡数据的规模与质量;最后,如何设计一个能够公平评估模型跨领域细粒度感知能力的基准套件(FGVQA),将不同域(如艺术品、鸟类、地标)的现有数据集重新转化为统一的VQA任务格式,也是一项复杂的系统工程。
常用场景
经典使用场景
在视觉-语言模型的研究领域,TWIN数据集主要用于提升模型对图像细节的感知能力。该数据集通过呈现大量视觉上高度相似的图像对,要求模型判断它们是否描绘了同一实体对象,从而迫使模型关注形状、纹理、部件几何结构等细微视觉线索。这种设计突破了传统视觉问答任务中仅关注类别级识别的局限,为模型提供了专注于实例级差异的训练环境,成为评估和增强视觉-语言模型细粒度理解能力的经典基准。
实际应用
TWIN数据集的实际应用场景广泛涉及需要高精度视觉辨别的领域。在电子商务领域,该数据集可辅助商品识别系统准确区分外观相似的不同产品,提升购物体验与库存管理效率。在文化遗产保护中,模型能够更精确地识别和匹配不同角度、光照下的艺术品或建筑细节。生物多样性监测也可受益于此,帮助自动识别外观相近的动植物物种。这些应用均依赖于模型对视觉细节的敏锐捕捉能力,而TWIN通过提供专门的训练资源,使视觉-语言模型在实际任务中表现出更强的实用性与可靠性。
衍生相关工作
TWIN数据集的推出催生了一系列围绕细粒度视觉理解的衍生研究。基于该数据集构建的FGVQA基准套件,整合了艺术品、地标、鸟类、动植物等多个领域的细粒度识别任务,成为评估模型跨领域泛化能力的重要工具。研究社区进一步探索了结合强化学习与监督微调的训练策略,以优化模型在保持通用能力的同时提升感知精度。此外,针对硬负样本挖掘、三维表征融合以及自动化数据增强方法的研究也应运而生,这些工作共同推动了视觉-语言模型在细节感知方面的算法进步与理论深化。
以上内容由遇见数据集搜集并总结生成


