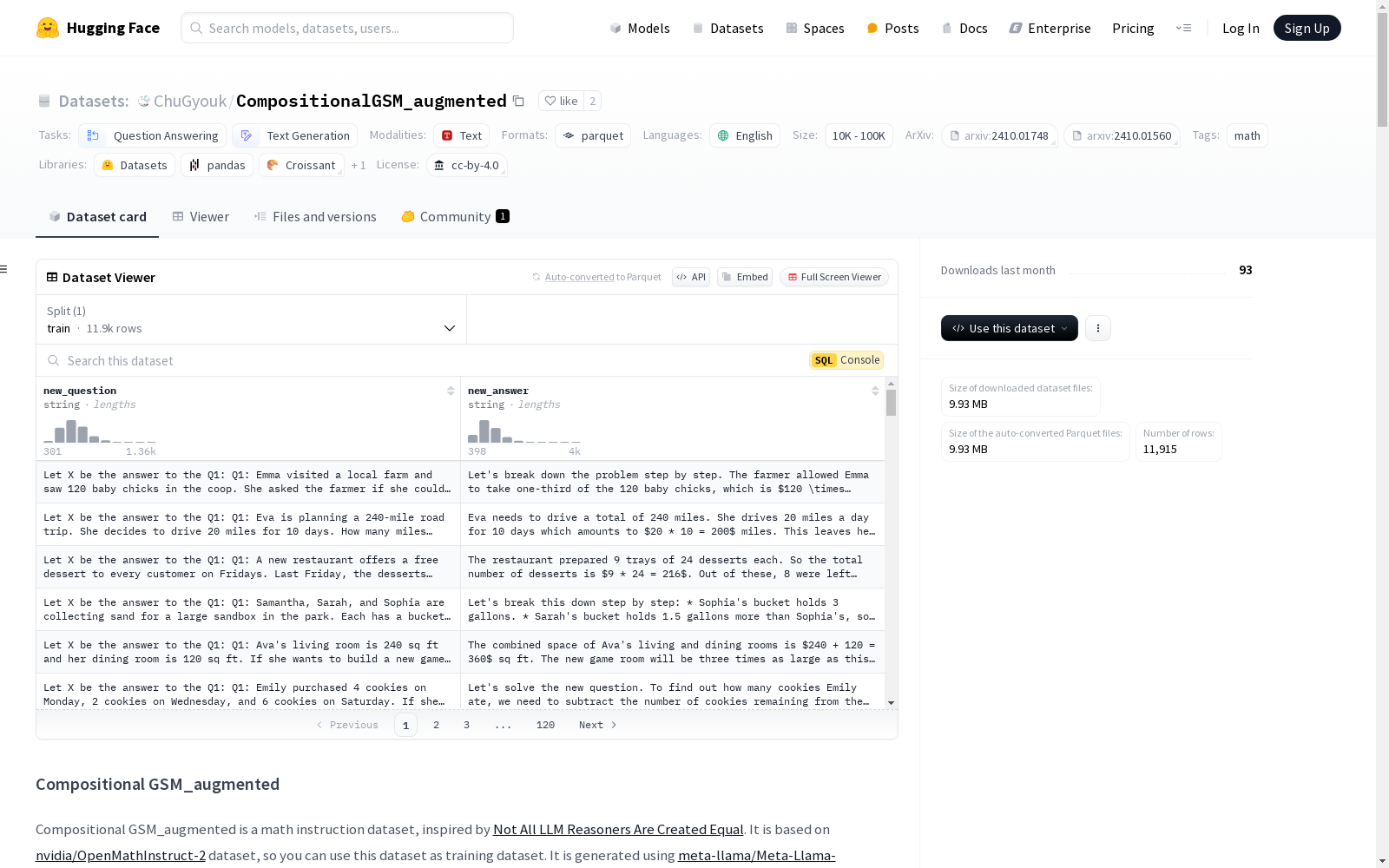
CompositionalGSM_augmented
收藏Compositional GSM_augmented 数据集概述
基本信息
- 语言: 英语
- 许可证: CC-BY-4.0
- 任务类别: 问答、文本生成
- 标签: 数学
数据集结构
- 特征:
new_question: 字符串类型new_answer: 字符串类型
- 分割:
train: 包含11915个样本,大小为21256871.72376337字节
数据生成
- 基础数据集: 基于nvidia/OpenMathInstruct-2
- 生成模型: 使用meta-llama/Meta-Llama-3.1-70B-Instruct模型生成
数据集描述
- 问题结构: 每个问题包含两个子问题(Q1和Q2),Q1的答案作为Q2中的变量X。
- 生成方法: 通过将两个数学问题合并为一个新问题,Q1的答案用于Q2的求解。
示例
有效示例
问题
Q1: Ava is three times Ethans age. Julian is 5 years older than Ava. If Ethan is 9, how many years old is Julian? Q2: Tom visited a seafood market and ordered X pounds of salmon fillets that cost $12.00 per pound. He also purchased 2 pounds of shrimp that were priced at $10.00 per pound. How much did Tom spend at the seafood market?
答案
Ava is 27 years old, Julian is 32 years old. Tom spent $404 at the seafood market.
无效示例
问题
Q1: Dr. Lee is working on two medical research projects. The first project has a 40% chance of securing a grant of $3,000,000 if successful and $0 if unsuccessful. The second project has a 60% chance of receiving $750,000 if the project is rejected and a 40% chance of receiving $1,500,000 if the project is accepted. Expressed as a percentage, how much more likely is it that Dr. Lees projects are both rejected compared to both being accepted? Q2: In a city, X people reside. 3,200 males live in that city and the rest of the population are females. Forty-five percent of the female population has long hair. How many females have long hair?
答案
Dr. Lees projects are 20% more likely to be both rejected compared to both being accepted. The number of females with long hair is not a meaningful result in this case.
引用
bibtex @article{toshniwal2024openmath2, title = {OpenMathInstruct-2: Accelerating AI for Math with Massive Open-Source Instruction Data}, author = {Shubham Toshniwal and Wei Du and Ivan Moshkov and Branislav Kisacanin and Alexan Ayrapetyan and Igor Gitman}, year = {2024}, journal = {arXiv preprint arXiv:2410.01560} }
@article{hosseini2024compositionalGSM, title = {Not All LLM Reasoners Are Created Equal}, author = {Arian Hosseini and Alessandro Sordoni and Daniel Toyama and Aaron Courville and Rishabh Agarwal}, year = {2024}, journal = {arXiv preprint arXiv:2410.01748} }