FLUX-Reason-6M
收藏arXiv2025-09-12 更新2025-09-13 收录
下载链接:
https://flux-reason-6m.github.io
下载链接
链接失效反馈官方服务:
资源简介:
FLUX-Reason-6M是一个包含600万张高质量图像和2000万条双语描述(英文和中文)的大规模数据集,旨在教授复杂的推理能力。图像按照六个关键特征组织:想象力、实体、文本渲染、风格、情感和构图,并设计了明确的生成思维链(GCoT)来提供图像生成步骤的详细分解。该数据集的创建过程耗资巨大,耗时15000个A100 GPU天,为社区提供了之前只有大型工业实验室才能获得的资源。数据集的创建、评估代码和基准测试已公开发布,以促进推理导向的文本到图像生成研究。
FLUX-Reason-6M is a large-scale dataset containing 6 million high-quality images and 20 million bilingual descriptions (English and Chinese), aimed at cultivating complex reasoning capabilities. The images within the dataset are categorized by six core attributes: Imagination, Entities, Text Rendering, Style, Emotion, and Composition. An explicit Generative Chain-of-Thought (GCoT) framework is designed to offer detailed step-by-step breakdowns of the image generation process. The development of this dataset incurred significant costs and consumed 15,000 A100 GPU days, thus granting the research community access to resources that were previously exclusively available to large industrial laboratories. The dataset creation, evaluation code, and benchmark tests have been publicly released to facilitate research on reasoning-oriented text-to-image generation.
提供机构:
香港中文大学, 香港大学, 北京航空航天大学, 阿里巴巴
创建时间:
2025-09-12
原始信息汇总
FLUX-Reason-6M & PRISM-Bench 数据集概述
数据集简介
FLUX-Reason-6M 是一个包含600万张高质量图像和2000万条双语(英文和中文)描述的大规模合成数据集,专门设计用于增强文本到图像(T2I)生成架构的推理能力。PRISM-Bench 是一个全面的、具有判别性的基准测试,包含7个独立轨道,与人类判断密切对齐。
关键特征
- 规模:600万张图像,2000万条双语描述。
- 计算资源:使用128块A100 GPU进行四个月的计算。
- 关键特性:图像根据六个关键特征组织:想象力(Imagination)、实体(Entity)、文本渲染(Text rendering)、风格(Style)、情感(Affection)和构图(Composition)。
- 生成思维链(GCoT):设计明确的生成思维链,提供图像生成步骤的详细分解。
基准测试(PRISM-Bench)
- 轨道数量:7个独立轨道。
- 评估方法:使用GPT-4.1和Qwen2.5-VL-72B等先进视觉语言模型进行细致的人类对齐评估,包括提示-图像对齐和图像美学。
- 挑战:包括一个使用GCoT的长文本挑战。
贡献
- FLUX-Reason-6M:首个为推理设计的600万规模T2I数据集,包含2000万条双语标题和开创性的生成思维链提示。
- PRISM-Bench:使用GPT-4.1和Qwen2.5-VL-72B进行细致和鲁棒评估的全面七轨道基准测试。
- 可操作的见解:通过对领先模型的广泛和严格评估,揭示不同模型之间的差距和潜在的改进领域。
- 民主化T2I革命:公开发布整个数据集、基准测试和评估套件,以降低财务和计算门槛。
官方排行榜
- PRISM-Bench (GPT4.1)
- PRISM-Bench (Qwen2.5-VL)
- PRISM-Bench-ZH (GPT4.1)
- PRISM-Bench-ZH (Qwen2.5-VL)
引用
bibtex @article{fang2025flux, title={FLUX-Reason-6M & PRISM-Bench: A Million-Scale Text-to-Image Reasoning Dataset and Comprehensive Benchmark}, author={Fang, Rongyao and Yu, Aldrich and Duan, Chengqi and Huang, Linjiang and Bai, Shuai and Cai, Yuxuan and Wang, Kun and Liu, Si and Liu, Xihui and Li, Hongsheng}, journal={arXiv preprint arXiv:2509.09680}, year={2025} }
搜集汇总
数据集介绍
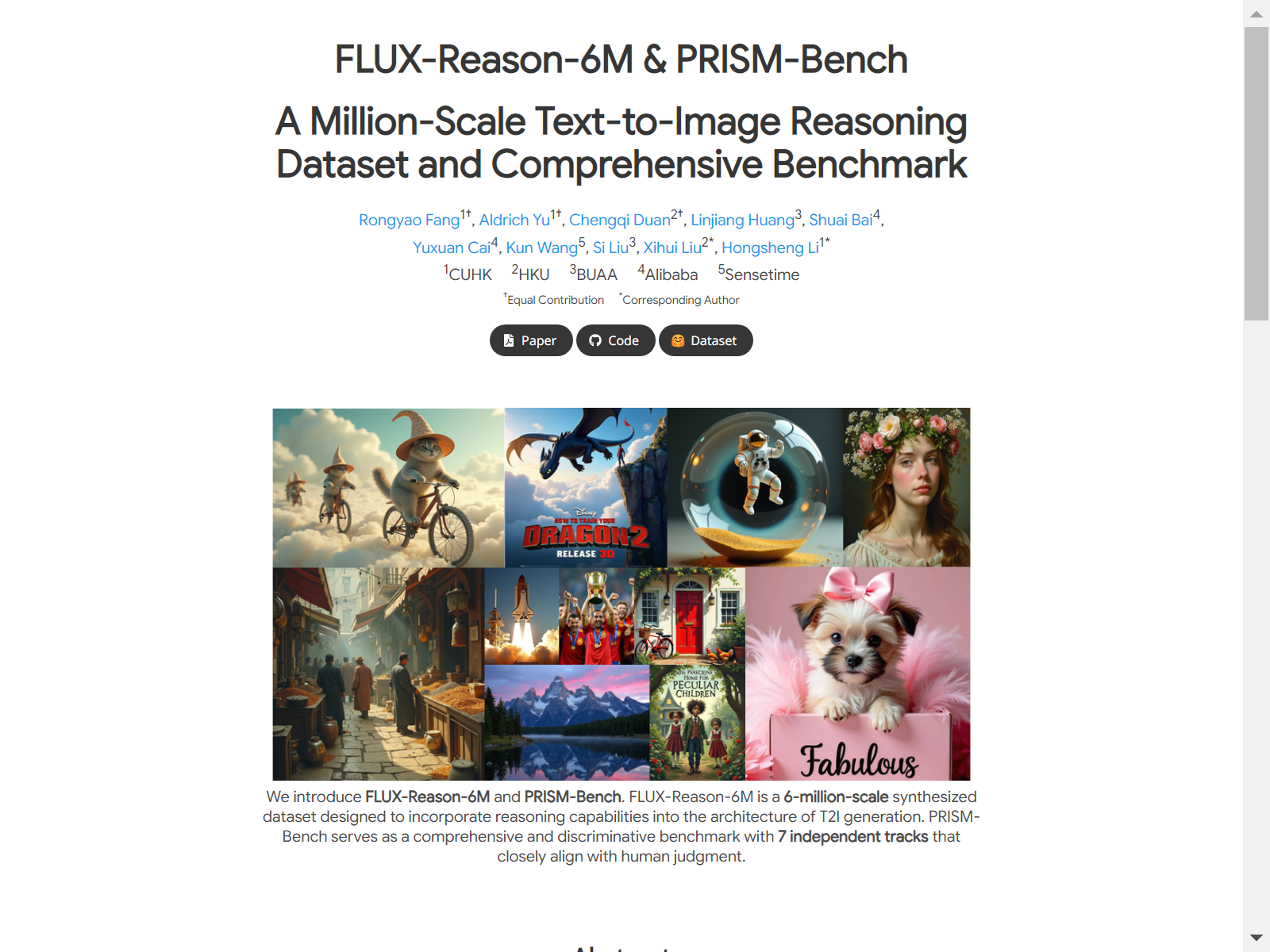
构建方式
FLUX-Reason-6M采用多阶段流水线构建方法,依托FLUX.1-dev模型合成600万张高质量图像。通过视觉语言模型对原始标注进行重写与扩充,并针对想象力与文本渲染两个薄弱维度实施专项增强:采用渐进式想象力培育策略生成创意描述,建立挖掘-生成-合成三级流水线提升文本渲染质量。经过多维质量过滤与分类评分,最终形成包含2000万条中英双语标注的推理数据集,总计算消耗达15,000个A100 GPU天。
特点
该数据集以生成思维链为核心特征,通过六维框架系统解构图像生成逻辑:想象力聚焦超现实概念合成,实体强调真实物体精确呈现,文本渲染注重字形可控生成,风格涵盖多元艺术表现形式,情感关联抽象情绪可视化,构图关注空间关系解析。采用多标签设计允许单图像跨类别标注,并配备详尽的生成思维链描述,为模型提供从概念分解到视觉实现的完整推理路径。
使用方法
研究者可通过Hugging Face平台获取数据集,支持端到端训练与微调场景。使用时应依据六维特性划分数据子集,优先采用生成思维链标注进行多模态联合训练。评估阶段建议搭配PRISM-Bench的七维评测体系,利用GPT-4.1等视觉语言模型对生成结果进行细粒度对齐度与美学质量评估。针对中文应用场景,可调用双语标注开展跨语言生成能力验证。
背景与挑战
背景概述
FLUX-Reason-6M由香港中文大学、香港大学、北京航空航天大学及阿里巴巴等机构的研究团队于2025年联合发布,旨在解决开源文本生成图像模型在复杂推理能力上的不足。该数据集包含600万张高质量图像及2000万条中英文描述,通过定义想象力、实体、文本渲染、风格、情感与构图六大核心特征,并创新性地引入生成思维链技术,为模型提供结构化推理信号。其构建消耗了15,000个A100 GPU日的计算资源,显著推动了生成式人工智能在细粒度语义理解与跨模态推理方向的发展。
当前挑战
该数据集针对文本生成图像领域中的复杂推理任务,需解决多特征协同生成、长文本指令遵循及跨语言一致性等核心问题。构建过程中面临三大挑战:一是高质量多模态数据的规模化合成,需平衡生成图像的审美一致性与语义准确性;二是生成思维链标注的自动化实现,要求视觉语言模型具备深层次的场景解构与逻辑表述能力;三是多语言语料的对齐与适配,尤其在文本渲染任务中需保持原语言符号的语义完整性。
常用场景
经典使用场景
在文本到图像生成领域,FLUX-Reason-6M数据集被广泛应用于训练和验证具备复杂推理能力的生成模型。该数据集通过六维特征体系(想象力、实体、文本渲染、风格、情感和构图)和生成思维链(GCoT)机制,为模型提供了结构化推理信号。典型应用场景包括教导模型解析多模态指令、理解空间关系逻辑以及实现跨语言图像合成,显著提升了生成图像与文本描述的语义一致性。
衍生相关工作
基于该数据集衍生的PRISM-Bench已成为评估文本到图像模型的新标准,其七维度评估体系被多项研究采纳为性能基准。多项开源项目如Bagel-CoT和HiDream系列模型均采用该数据集进行推理能力训练,而生成思维链机制更启发了后续研究对多步推理范式的探索。这些工作共同推动了开放源代码模型在复杂指令遵循和跨模态推理方面的技术进展。
数据集最近研究
最新研究方向
FLUX-Reason-6M作为当前规模最大的文本到图像推理数据集,正推动生成式人工智能在复杂场景合成与多模态推理领域的前沿探索。该数据集通过引入生成思维链(GCoT)结构和六维特性框架(想象力、实体、文本渲染、风格、情感与构图),为模型提供了细粒度的推理监督信号。近期研究聚焦于利用其双语标注和大规模高质量图像-文本对,训练开源模型突破封闭系统在长文本理解、跨模态对齐和创造性生成方面的性能瓶颈。PRISM-Bench的七维度评估体系进一步揭示了模型在文本渲染和复杂指令遵循方面的薄弱环节,为下一代推理导向的T2I模型提供了明确的优化方向。这一工作不仅填补了开源社区在推理数据集领域的空白,更通过降低训练门槛加速了生成式AI技术的民主化进程。
相关研究论文
- 1FLUX-Reason-6M & PRISM-Bench: A Million-Scale Text-to-Image Reasoning Dataset and Comprehensive Benchmark香港中文大学, 香港大学, 北京航空航天大学, 阿里巴巴 · 2025年
以上内容由遇见数据集搜集并总结生成


