cyankiwi/Global-MMLU-Lite-aample
收藏Hugging Face2026-05-04 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/cyankiwi/Global-MMLU-Lite-aample
下载链接
链接失效反馈官方服务:
资源简介:
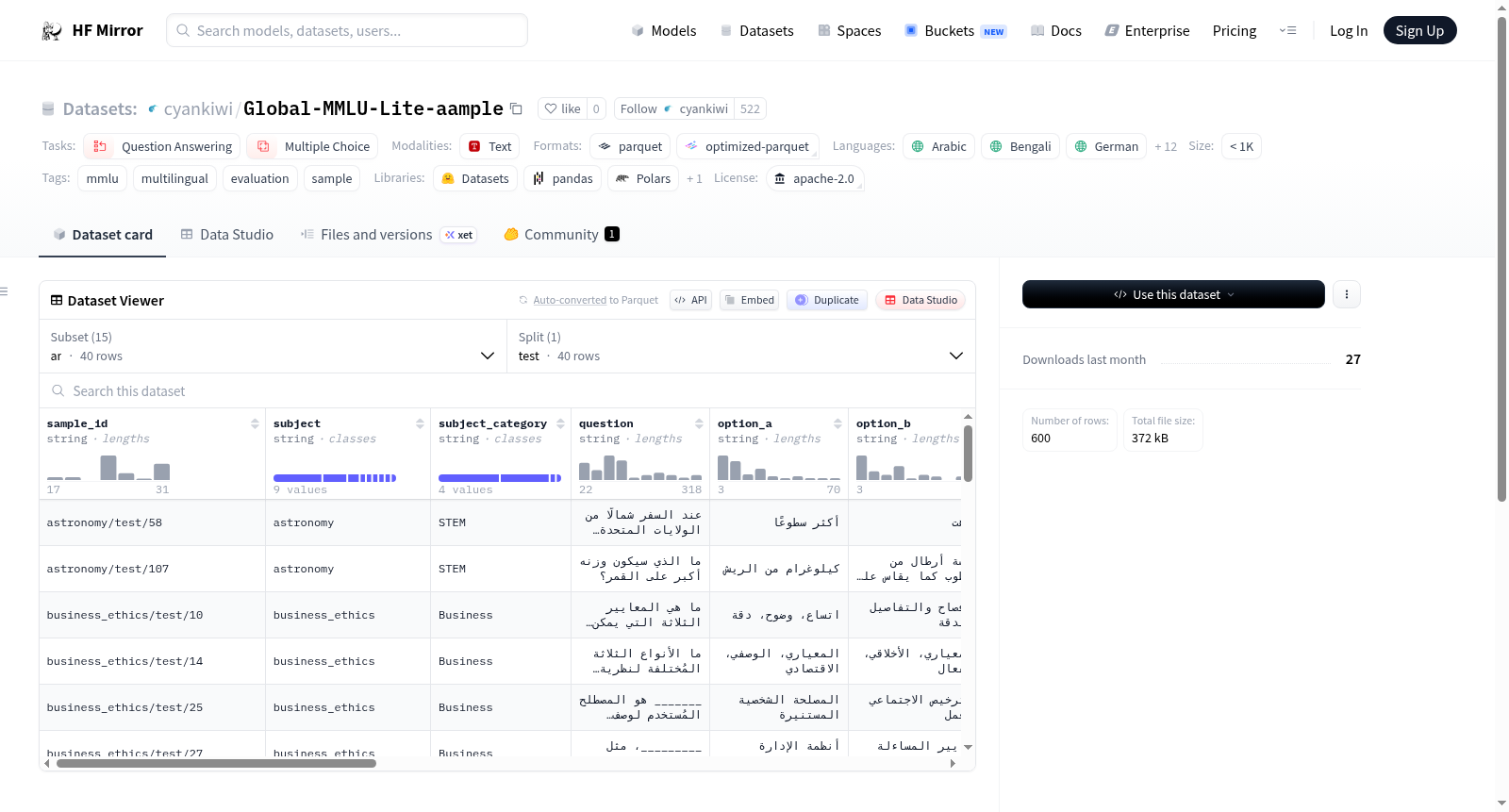
Global-MMLU-Lite是一个小型、固定大小的子集,旨在用于快速测试多语言MMLU评估流程。它包含15种语言(阿拉伯语、孟加拉语、德语、英语、西班牙语、法语、印地语、印尼语、意大利语、日语、韩语、葡萄牙语、斯瓦希里语、约鲁巴语和中文),每种语言40个示例,总共600个示例。这些示例严格不重叠,且保留了上游数据集的模式(相同的列和数据类型)。
Global-MMLU-Lite is a small, fixed-size subset intended for fast smoke-testing of multilingual MMLU evaluation pipelines. It includes 40 examples per language across 15 languages (Arabic, Bengali, German, English, Spanish, French, Hindi, Indonesian, Italian, Japanese, Korean, Portuguese, Swahili, Yoruba, and Chinese), totaling 600 examples. The examples are strictly non-overlapping and preserve the schema from the upstream dataset (same columns and dtypes).
提供机构:
cyankiwi
搜集汇总
数据集介绍
构建方式
Global-MMLU-Lite-sample作为多语言大规模多任务语言理解评估基准的精简版本,旨在为研究者提供快速验证多语言评估管道的工具。该数据集从母库CohereLabs/Global-MMLU-Lite中严格按语言划分非重叠窗口进行采样:每种语言从原始测试集与开发集合并后的600条样本池中,依语言索引顺序截取连续的40个样本,确保语言0至9完全取自测试集,语言10至14取自开发集。最终汇聚成涵盖15种语言、总计600条样本的均衡子集,其数据模式与上游数据集完全一致,保持相同的列结构与数据类型。
特点
该数据集最显著的特性在于其精巧的均衡性与高度兼容性。每种语言严格包含40个样本,覆盖阿拉伯语、孟加拉语、德语、英语、西班牙语、法语、印地语、印尼语、意大利语、日语、韩语、葡萄牙语、斯瓦希里语、约鲁巴语及中文在内的15种语言,构成跨语系的多语言评估框架。样本选取采用非重叠窗口机制,语言间无样本交集,确保评估的独立性与公平性。更重要的是,数据集完整保留了上游的全部模式特征,使得任何原本适配Global-MMLU-Lite的评估代码均可无缝迁移,无需任何适配调整。
使用方法
该数据集可通过HuggingFace Datasets库便捷加载,用户只需指定语言配置名称即可获取对应子集。每种语言作为一个独立配置项,数据文件以Parquet格式存储于对应语言目录下,支持高效读取。典型用法包括:快速验证多语言评估管道的正确性、检测数据加载与预处理流程的兼容性、或是作为开发调试阶段的轻量级测试集。由于样本量可控且语言覆盖均衡,研究者可以高效完成从单语言到多语言评估的全面功能测试,从而大幅缩短模型评估前的准备工作周期。
背景与挑战
背景概述
Global-MMLU-Lite-sample数据集是为评估多语言自然语言理解能力而构建的轻量级基准测试集,诞生于大型语言模型多语言评测需求日益凸显的背景下。该数据集由Cohere Labs研究团队于近期发布,旨在为Global-MMLU-Lite提供一套快速、可复现的烟雾测试方案。研究机构聚焦于解决多语言环境下的知识推理评估难题,通过选取阿拉伯语、孟加拉语、德语、英语、西班牙语等15种语言,每种语言40个样本,共计600个条目,构建了跨语言一致性评测框架。这一数据集继承自Global-MMLU-Lite,保留了原始架构的列结构和数据类型,确保兼容性。其影响力体现在为多语言模型开发者提供了便捷的测试管道,加速了全球语言理解研究的迭代进程,填补了多语言知识与推理评估领域中轻量级标准化测试的空白。
当前挑战
该数据集所应对的领域挑战在于多语言知识推理评估的复杂性与资源分配不均问题。不同语言在训练数据规模、语言结构复杂度及文化背景差异上的显著差异,导致单一语言评测无法反映模型真正的全球适用性,Global-MMLU-Lite-sample通过标准化采样试图缓解此偏差,但样本量稀疏性仍是核心挑战。构建过程中的技术挑战则包括确保跨语言样本的非重叠性,原始数据集按语言划分的测试集(400条)与开发集(200条)共600条池中,需严格分配语言索引区间(如第0至9种语言取自测试集,第10至14种取自开发集),而对齐不同语言的同源问题类型和难度级别亦需精细处理,以维持评测的公平性与可比较性。
常用场景
经典使用场景
Global-MMLU-Lite-sample作为Global-MMLU-Lite的精简采样版本,专为多语言大语言模型的快速评估设计,尤其适用于跨语言常识推理与知识理解能力的初步检验。该数据集涵盖阿拉伯语、孟加拉语、中文等15种语言,每种语言仅包含40个精心挑选的示例,在保证语言多样性的同时极大降低了评估计算成本。研究者可借助该样本集快速验证多语言模型在MMLU基准上的表现趋势,为后续全面评估提供可靠预判。其结构完全继承上游数据集规范,确保评估流程无缝衔接,是多语言模型开发中不可或缺的轻量级测试工具。
实际应用
在实际应用中,Global-MMLU-Lite-sample成为工业界和学术界多语言模型开发流程中的高效调试与验证工具。工程师可在模型训练的关键节点,利用该样本集快速检测模型在不同语言上的表现变化,及时发现语言特异性偏差或退化问题。它适用于跨语言问答系统的迭代优化、多语言教育智能助手的初步验证,以及面向全球用户的产品上线前的语言能力摸底测试。通过此样本集,开发团队能以极低成本获得多语言性能的初步反馈,从而加速产品迭代,提升多语言服务的可靠性与用户体验。
衍生相关工作
基于Global-MMLU-Lite-sample的设计理念,衍生了一系列专注于多语言评估轻量化与标准化的重要工作。研究者借鉴其采样策略,构建了针对特定语言族或低资源语言的压缩评估集,如Swahili-MMLU-Lite和Yoruba-MMLU-Lite。这些工作推动了多语言评估基准的民主化进程,使资源匮乏的语言也能获得快速评测方案。此外,该样本集促进了多语言模型持续学习与少样本学习场景下的评估方法研究,催生了如跨语言微调样本递增策略等创新框架,进一步丰富了多语言NLP领域的方法论体系。
以上内容由遇见数据集搜集并总结生成


