ckadirt/auramix_1km
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ckadirt/auramix_1km
下载链接
链接失效反馈官方服务:
资源简介:
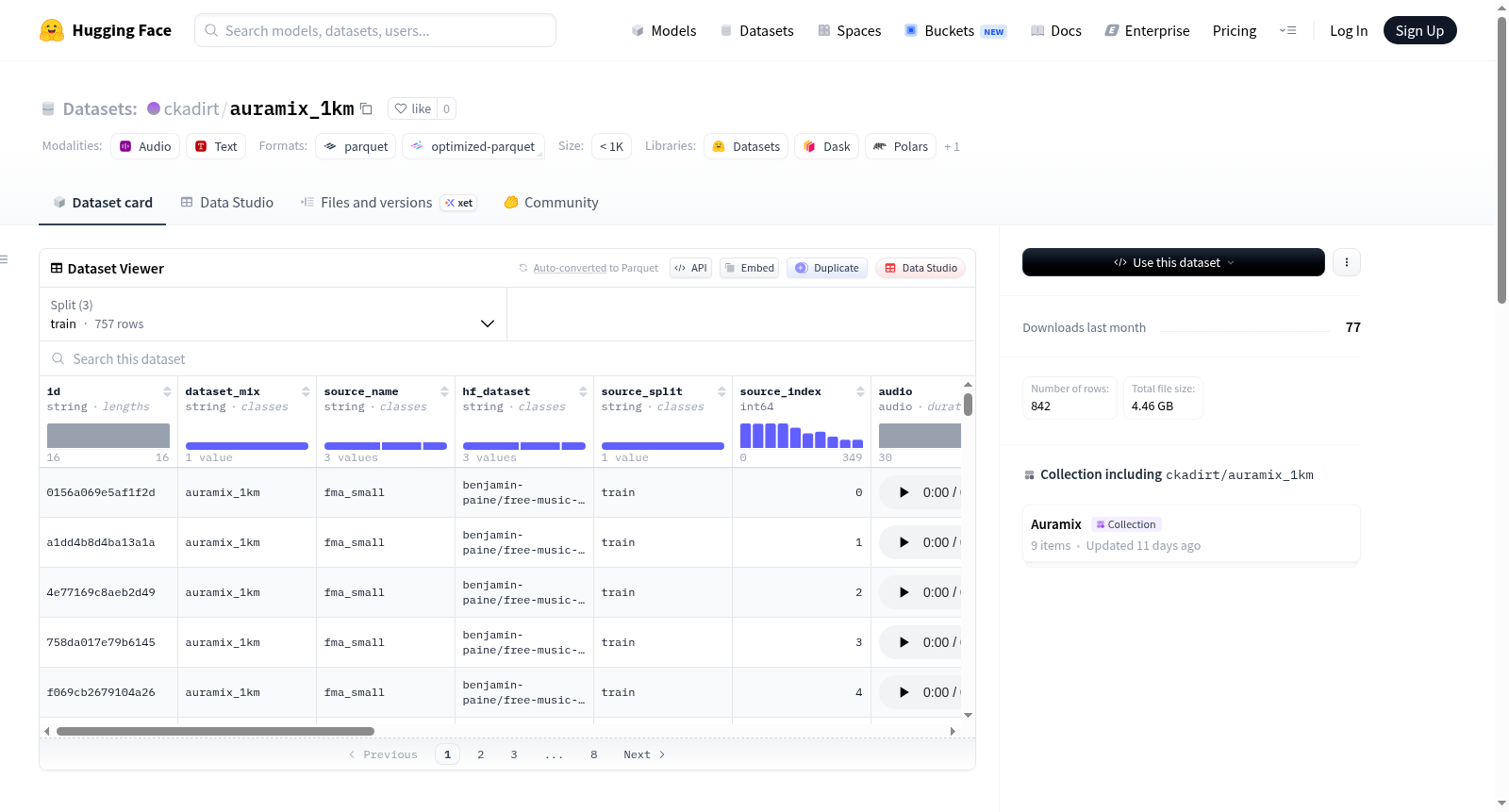
AuraMix是一个小型精选音频重建/评估混合数据集,由多个Hugging Face音频源生成。数据集包含842个WAV文件,总大小约2.08GB,采样率为44100Hz,每个剪辑时长为30秒,且为单声道。数据来源包括四个不同的Hugging Face数据集:fma_small、fma_commercial_full、music_genres_small和ai_vs_human_music。数据集的字段包括音频特征、原始相对路径、源名称、Hugging Face数据集仓库、源分割、源索引、采样率、持续时间等。数据集是通过从源数据集中采样固定长度的剪辑并写入PCM_16 WAV文件生成的。
AuraMix is a small curated audio reconstruction/evaluation mix generated from multiple Hugging Face audio sources. The dataset contains 842 WAV files, with a total size of approximately 2.08 GB, a sample rate of 44100 Hz, each clip duration of 30.0 seconds, and is mono. The data sources include four different Hugging Face datasets: fma_small, fma_commercial_full, music_genres_small, and ai_vs_human_music. The fields of the dataset include audio features, original relative path, source name, Hugging Face dataset repository, source split, source index, sample rate, duration, etc. The dataset was generated by sampling fixed-length clips from the source datasets and writing PCM_16 WAV files.
提供机构:
ckadirt
搜集汇总
数据集介绍
构建方式
AuraMix_1km数据集由多个来自Hugging Face平台的音频源精心混合而成,旨在服务于音频重建与评估任务。其构建过程涉及从四个不同的开源音频数据集中进行采样,包括Free Music Archive的小型和商用全频版本、音乐流派小样本集以及人工智能与人类音乐对比数据集。具体操作上,从每个源数据集中随机截取固定时长为30秒的音频片段,并将其统一转换为单声道、采样率为44100 Hz的PCM_16位WAV格式文件,最终形成包含842条音频剪辑的精选集合。
特点
该数据集的核心特点在于其多源异构性与高精度的元数据标注。每条样本不仅包含嵌入WAV字节的音频特征,还附带了原始相对路径、来源数据集名称、数据划分、索引位置以及截取起止时间等详尽信息。这种设计使得研究者能够精确追溯每个片段的原始来源,便于进行跨数据集的性能对比分析。此外,数据集规模适中(约2.08 GB),兼顾了实验效率与数据多样性,特别适合用于音频重建模型的快速验证与评估。
使用方法
使用AuraMix_1km数据集时,可直接通过Hugging Face的Datasets库加载。数据集预设了训练、验证和测试三个数据划分,分别对应路径'train-*'、'validation-*'和'test-*'下的parquet文件。用户可通过指定配置名'default'自动获取所有样本,并利用'audio'字段直接访问解码后的音频数组。对于需要原始元数据的任务,可通过'metadata_json'字段提取JSON编码的附加信息。建议在加载时设置流式模式以节省内存,适用于音频重建质量评估、源分离等研究场景。
背景与挑战
背景概述
AuraMix_1km数据集由研究机构CKADIRT于近期构建,旨在为音频重建与评估任务提供一个小型但精心策划的混合音频资源。该数据集融合了来自四个公开音频数据源的842条时长30秒、采样率44100Hz的单声道WAV片段,覆盖了自由音乐档案、音乐流派分类及人机音乐识别等多样化的音频内容。其核心研究问题在于如何通过整合不同来源的高质量音频,构建一个标准化的评估基准,以支持音频信号处理、音乐信息检索及生成式音频模型性能的客观衡量。尽管规模有限,AuraMix_1km通过结构化元数据字段(如源名称、裁剪起始点)为可重复的音频处理流程奠定了基础,对推动音频领域的小样本学习与细粒度评估研究具有参考价值。
当前挑战
AuraMix_1km数据集面临的核心挑战在于其构建过程中音源异质性的有效整合。首先,来自不同数据集的音频在编码格式、动态范围及背景噪声水平上存在差异,需通过统一重采样、裁剪及转码为PCM_16 WAV格式来保证一致性,这一过程可能引入信息损失或非线性能量变化。其次,数据集规模仅为842条,难以覆盖广泛音频场景,限制了其在通用音频重建任务中的代表性与泛化能力。此外,混合来源中的版权属性(如商业音乐片段)可能引发合规性风险,需谨慎管理元数据溯源以确保合法使用。最后,固定30秒时长裁剪策略无法适配音频事件的时间尺度多样性,可能导致关键结构片段被截断或冗余静音片段累积,从而影响后续模型训练与评估的可靠性。
常用场景
经典使用场景
auramix_1km是一个精心策划的小型音频数据集,专门用于音频重建与评估任务。该数据集汇聚了来自多个Hugging Face音频源的842个30秒时长、44.1kHz采样率的单声道WAV片段,涵盖FMA小型数据集、FMA商业完整版、音乐流派数据集以及AI与人类音乐对比数据集等多元来源。在音频质量评估与重建研究中,研究人员常利用此数据集的统一时长与格式特性,作为基准测试平台,系统性地比较不同音频编码、压缩或去噪算法的性能优劣,通过对比原始片段与重建版本的感知质量,推动音频处理技术的精细化发展。
解决学术问题
该数据集有效解决了音频重建与评估研究中长期存在的两大核心难题:缺乏标准化、多源混合的测试基准,以及音视频片段时长、采样率不一致导致的实验可比性下降问题。auramix_1km通过提供统一格式、固定时长与标注完备的音频样本集合,使得研究者能够专注于算法本身的改进,而非耗费精力于数据预处理工作。其多元化的音乐来源结构,为评估算法在古典、流行、电子等不同音乐风格下的泛化能力提供了坚实依据,极大促进了音频编解码器客观评价指标(如PESQ、STOI)与主观听感之间的相关性研究,为构建更可靠的音频质量评估体系奠定了数据基础。
衍生相关工作
基于auramix_1km数据集,已催生出多项具有影响力的后续研究工作。部分团队利用其多源混合特性,开发了基于深度学习的主观音频质量映射模型,通过训练神经网络学习客观指标与人类评分之间的非线性关系,从而更精准地预测感知音质。另有研究者以其为训练数据,构建了跨风格音频修复模型,利用数据集内不同音乐流派的丰富变化,提升模型对缺失频段重建的泛化能力。此外,该数据集还被用于验证新的音频水印算法在多种音乐类型中的隐蔽性与鲁棒性,这些衍生工作共同彰显了auramix_1km作为基础数据平台在音频信号处理领域的价值与潜力。
以上内容由遇见数据集搜集并总结生成


