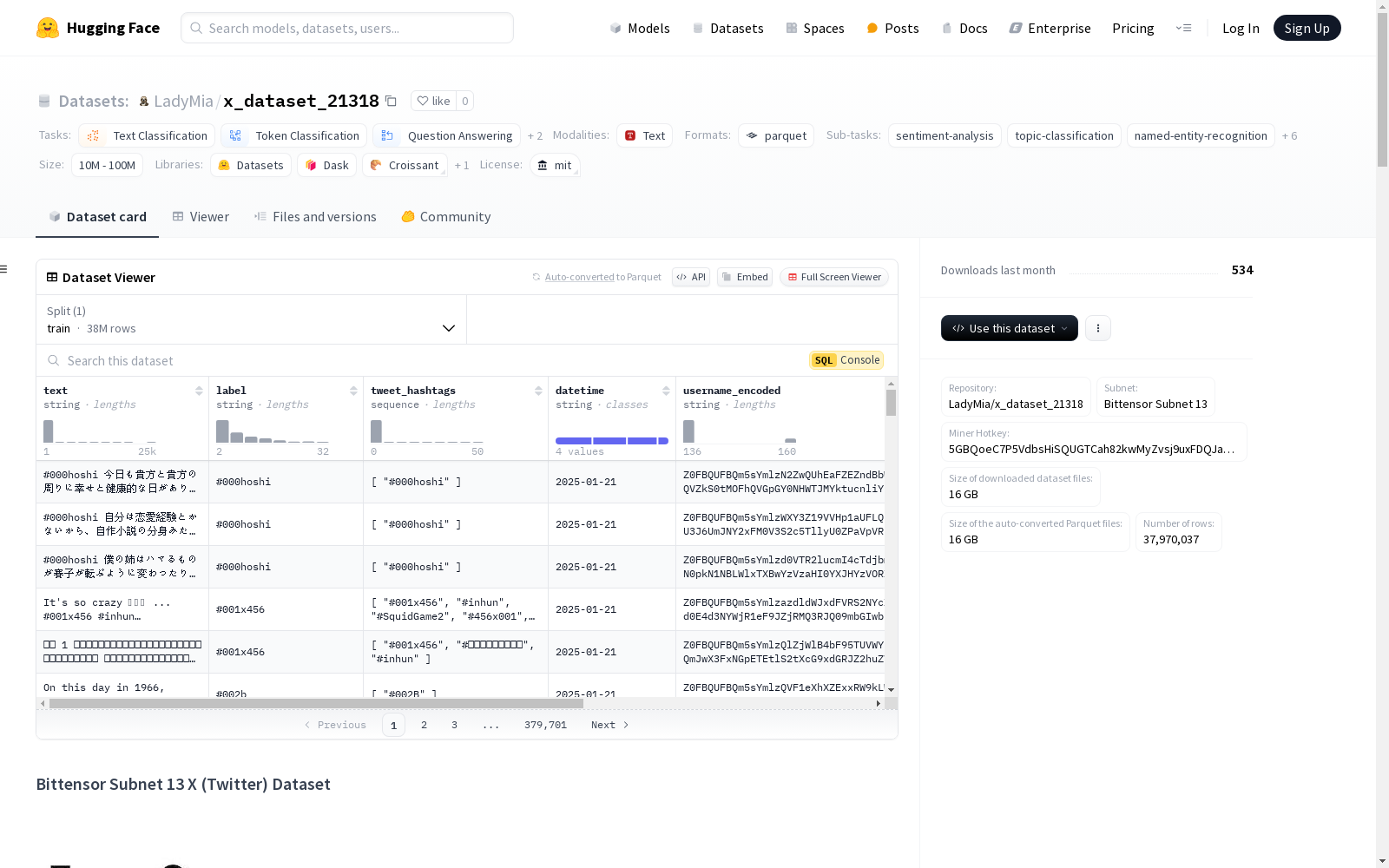
x_dataset_21318
收藏Hugging Face2025-01-30 更新2025-02-10 收录
下载链接:
https://huggingface.co/datasets/LadyMia/x_dataset_21318
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是Bittensor Subnet 13去中心化网络的一部分,包含来自X(前身为Twitter)的预处理数据。数据由网络矿工持续更新,提供实时的推文流,适用于各种分析和机器学习任务。数据集支持多种任务,如情感分析、趋势检测、内容分析和用户行为建模等。数据集中主要包含推文的文本内容、标签、使用的标签、发布时间、编码后的用户名和URL等信息。数据集是多语言的,但主要是英语。数据集的创建遵循X的条款和服务使用指南,所有用户名和URL都经过编码以保护用户隐私。数据集的使用需要注意可能存在的偏见和限制,如数据质量、噪声、时间偏差等。数据集采用MIT许可证发布,并提供了引用信息。
创建时间:
2025-01-27
原始信息汇总
Bittensor Subnet 13 X (Twitter) Dataset
数据集描述
- 数据集名称: Bittensor Subnet 13 X (Twitter) Dataset
- 存储库: LadyMia/x_dataset_21318
- 子网: Bittensor Subnet 13
- 数据类型: 预处理后的Twitter数据
- 更新方式: 实时更新
- 数据来源: 公共Twitter推文
- 许可证: MIT
支持的任务
- 文本分类
- 令牌分类
- 问题回答
- 摘要
- 文本生成
- 情感分析
- 主题分类
- 命名实体识别
- 语言建模
- 文本评分
- 多类分类
- 多标签分类
- 提取式问答
- 新闻文章摘要
数据结构
- 数据实例: 每个实例代表一条推文
- 数据字段:
text(string): 推文内容label(string): 推文情感或主题分类tweet_hashtags(list): 推文中的标签列表datetime(string): 推文发布日期username_encoded(string): 编码后的用户名url_encoded(string): 编码后的URL
数据切分
- 数据集持续更新,无固定切分,用户应根据需求和时间戳创建自己的切分
数据创建
- 数据来源:遵循Twitter平台服务条款和API使用指南的公共推文
- 个人和敏感信息:用户名和URL已编码,保护用户隐私
使用数据的注意事项
- 社会影响和偏见:Twitter数据可能存在人口统计和内容偏见
- 限制:数据质量可能因去中心化收集和预处理而异,可能包含噪声、垃圾邮件或无关内容
数据统计
- 总实例数: 37,970,037
- 日期范围: 2025-01-21 至 2025-02-05
- 最新更新: 2025-02-10
数据分布
- 带标签的推文:54.73%
- 不带标签的推文:45.27%
前10大标签
| 排名 | 主题 | 总计数 | 百分比 |
|---|---|---|---|
| 1 | NULL | 17,187,571 | 45.27% |
| 2 | #riyadh | 375,993 | 0.99% |
| 3 | #zelena | 246,690 | 0.65% |
| 4 | #tiktok | 197,258 | 0.52% |
| 5 | #bbb25 | 138,438 | 0.36% |
| 6 | #jhope_at_galadespiècesjaunes | 121,700 | 0.32% |
| 7 | #ad | 116,000 | 0.31% |
| 8 | #royalrumble | 75,800 | 0.20% |
| 9 | #grammys | 75,040 | 0.20% |
| 10 | #bbmzansi | 66,894 | 0.18% |
更新历史
| 日期 | 新实例数 | 总实例数 |
|---|---|---|
| 2025-01-27 | 3,256,771 | 3,256,771 |
| 2025-01-30 | 8,250,381 | 11,507,152 |
| 2025-02-03 | 8,536,792 | 20,043,944 |
| 2025-02-06 | 7,440,251 | 27,484,195 |
| 2025-02-10 | 10,485,842 | 37,970,037 |
搜集汇总
数据集介绍
构建方式
x_dataset_21318数据集是Bittensor Subnet 13去中心化网络的一部分,采集自X(前Twitter)的预处理数据。数据通过网络矿工持续更新,为各种分析和机器学习任务提供实时推文流。数据集的构建严格遵循X平台的服务条款和API使用指南,确保了数据的合法性和时效性。
特点
本数据集具有多语言特性,以英语为主,但因其去中心化的创建方式,也可能包含其他语言。数据集支持多种任务类别,如文本分类、标记分类、问答、摘要在内的多种机器学习任务。数据集不断更新,无固定划分,用户可根据需求和时间戳自行创建数据划分。为保护用户隐私,所有用户名和URL均经过编码处理。
使用方法
在使用该数据集时,用户需自行创建数据划分,并根据具体的研究或业务需求灵活运用数据。数据集适用于情感分析、趋势检测、内容分析、用户行为建模等多种场景。同时,用户应意识到数据可能存在的偏差和局限性,并在使用时充分考虑社交影响和潜在偏见。
背景与挑战
背景概述
x_dataset_21318数据集,作为Bittensor Subnet 13网络的一部分,是一个不断更新的、包含来自X(前Twitter)预处理数据的集合。该数据集由网络矿工持续更新,为各种分析和机器学习任务提供实时推文流。其创建旨在服务于去中心化网络,反映出社交媒体动态的多样性,并促进了相关领域的研究与应用。该数据集的构建始于2025年,由LadyMia维护,主要针对文本分类、命名实体识别、情感分析等任务,支持多语言处理,但以英语为主。该数据集在学术界和工业界产生了广泛影响,为社交媒体内容分析、用户行为建模等领域的研究提供了宝贵的资源。
当前挑战
x_dataset_21318数据集在构建和应用过程中面临的挑战包括:确保数据质量的一致性,因为数据是去中心化收集和预处理的;处理数据中的噪声、垃圾信息和无关内容;识别并处理可能存在的时态偏见;以及遵守X平台的使用条款和服务条款。此外,数据集的实时更新特性要求用户在创建数据划分时自行考虑时间戳,以保证研究的有效性。在利用该数据集时,还需关注潜在的社交媒体数据偏差问题,如人口统计和内容偏见,这些偏差可能会影响研究结果的普遍性和准确性。
常用场景
经典使用场景
在自然语言处理领域,x_dataset_21318数据集以其多语言特性和多样化的任务类别,成为研究与实践的热门资源。经典的使用场景包括情感分析、话题分类、命名实体识别等,研究人员可通过该数据集深入探索社交媒体内容的多样性和复杂性。
解决学术问题
该数据集解决了学术研究中关于社交媒体数据的多语言处理、实时数据流分析和动态内容分类等问题,为研究社交媒体趋势、用户行为和内容分发提供了重要支撑,对理解网络社交动态具有重要意义。
衍生相关工作
基于该数据集,衍生出了一系列经典工作,如情绪分析模型的构建、社交媒体影响力评估体系的开发以及网络舆论引导策略的研究,为社交媒体数据的深入挖掘和应用提供了丰富的案例和方法论。
以上内容由遇见数据集搜集并总结生成


