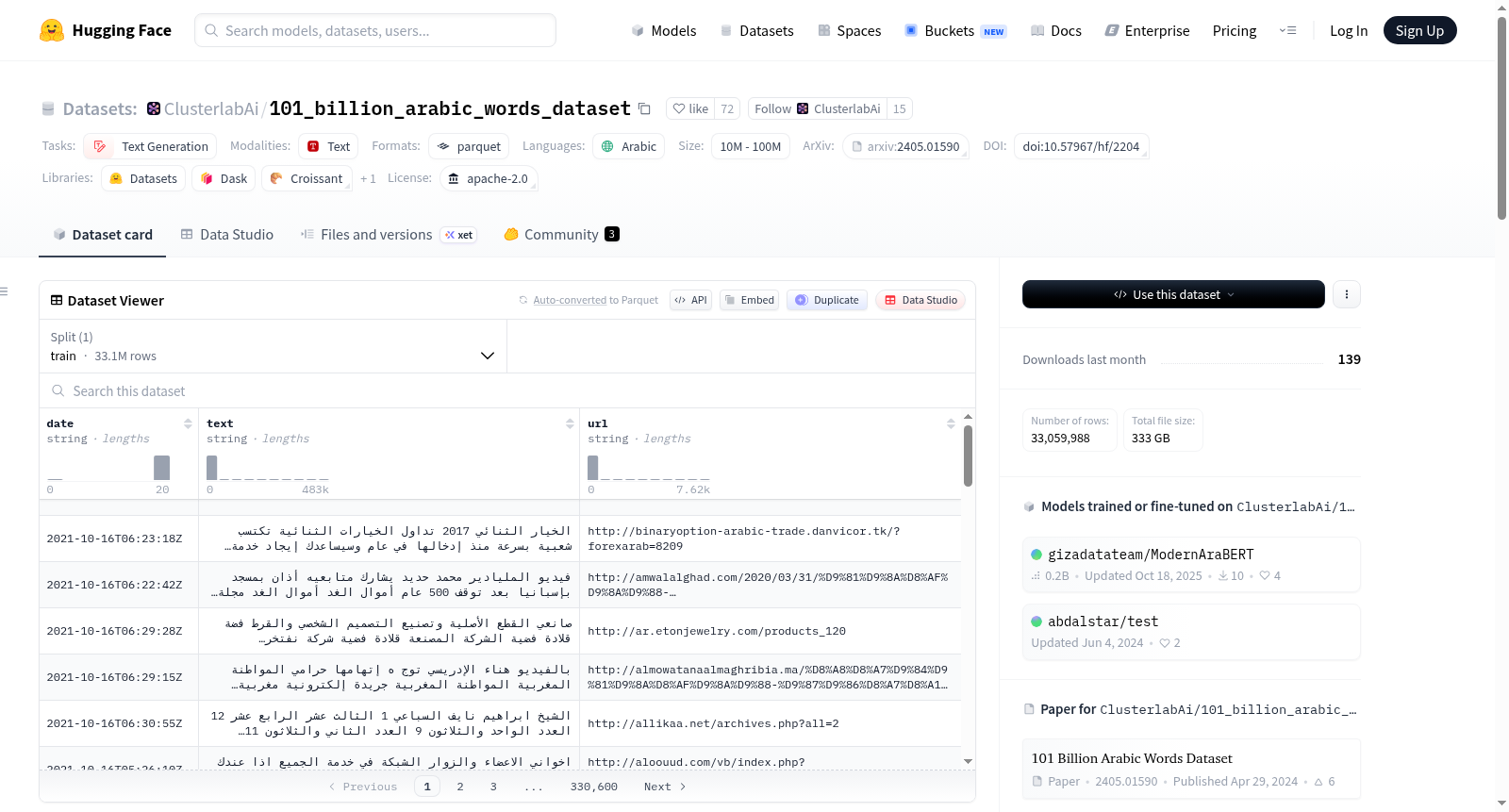
101 Billion Arabic Words Dataset
收藏arXiv2024-04-29 更新2024-06-21 收录
下载链接:
https://huggingface.co/datasets/ClusterlabAi/101_billion_arabic_words_dataset
下载链接
链接失效反馈官方服务:
资源简介:
101 Billion Arabic Words Dataset是由Clusterlab团队创建的,旨在解决阿拉伯世界数据稀缺问题,并推动阿拉伯语言模型的开发。该数据集包含超过1010亿个阿拉伯语单词,是从Common Crawl的WET文件中提取的,经过严格的清洗和去重处理。数据集的创建过程涉及从2021年9月至2022年7月的时间跨度内,从Common Crawl中提取阿拉伯语内容,并使用Rust进行数据处理。该数据集主要用于支持阿拉伯语言模型的训练和优化,以促进阿拉伯语在自然语言处理技术中的应用。
The 101 Billion Arabic Words Dataset was developed by the Clusterlab team to address the issue of data scarcity in the Arab world and advance the development of Arabic large language models. Containing over 101 billion Arabic words, this dataset is extracted from the WET files of Common Crawl and has undergone rigorous cleaning and deduplication processing. The creation of the dataset spanned from September 2021 to July 2022, during which Arabic content was extracted from Common Crawl and processed using Rust. This dataset is primarily used to support the training and optimization of Arabic large language models, so as to promote the application of the Arabic language in natural language processing (NLP) technologies.
提供机构:
Clusterlab团队
创建时间:
2024-04-29
搜集汇总
数据集介绍
构建方式
在阿拉伯语自然语言处理领域,数据稀缺长期制约着语言模型的真实性发展。为应对这一挑战,本研究从Common Crawl WET文件中系统提取了2021年9月至2022年7月期间的网络文本,初始规模达0.8PB。通过Rust语言实现的高效管道,团队专门筛选阿拉伯语网站内容,并采用JSONL格式进行结构化存储。数据清洗阶段融合了多层次处理策略:基于预定义关键词与rustrict库的URL过滤机制有效剔除了低质量与成人内容;利用哈希算法实现URL级去重;借助Tnkeeh工具完成HTML标签清理、Unicode规范化及去空格处理;进一步应用MinHash算法在文档与段落层面进行语义去重。最终通过分布式计算框架与GPU加速,将原始数据精炼为包含1010亿词汇的纯净语料库。
使用方法
研究者可通过HuggingFace平台直接访问该数据集,其标准化格式便于集成至主流机器学习框架。在预训练场景中,该语料可作为核心训练数据用于从头构建阿拉伯语大语言模型,或通过领域适应技术增强现有模型的阿拉伯语能力。对于微调任务,数据集的纯净特性使其适合作为指令微调、阅读理解及文本生成等下游任务的基准数据。使用建议遵循Apache 2.0许可协议,并鼓励结合CAMeL工具包等阿拉伯语专用工具进行进一步文本处理。在部署前,用户可依据自身计算资源,参考论文中的分布式处理方案优化数据加载流程,以充分发挥大规模语料的价值。
背景与挑战
背景概述
随着大规模语言模型在自然语言处理领域的崛起,英语语料库的丰富性推动了该语言的模型性能达到全球领先水平,而阿拉伯语作为拥有超过四亿使用者的重要语言,其数字资源却长期面临稀缺与质量不均的挑战。2024年,Clusterlab团队发布了《101 Billion Arabic Words Dataset》,这一数据集旨在通过从Common Crawl中大规模提取、清洗与去重,构建一个纯正的阿拉伯语语料库,以支持开发真正反映阿拉伯语言文化特性的大语言模型。该数据集的创建不仅回应了阿拉伯语在计算语言学中的边缘化问题,也为推动语言技术的多元发展与文化公平性提供了关键资源。
当前挑战
在构建《101 Billion Arabic Words Dataset》过程中,研究团队面临双重挑战。首先,在领域问题层面,阿拉伯语大语言模型常因依赖翻译自英语的语料而产生文化偏差,导致生成内容缺乏语言真实性与文化细微差异,这要求数据集必须包含原生、高质量的阿拉伯语文本以支撑模型的准确训练。其次,在构建过程中,从Common Crawl的海量网络数据中筛选阿拉伯语内容涉及复杂的噪声过滤,包括移除HTML标签、特殊Unicode字符、成人内容及重复URL,同时需通过MinHash等技术实现文档与段落级去重,并利用分布式计算优化处理效率,确保数据集的纯净度与可扩展性。
常用场景
经典使用场景
在阿拉伯语自然语言处理领域,大规模高质量语料库的匮乏长期制约着语言模型的深度发展。101 Billion Arabic Words Dataset作为迄今规模最大的阿拉伯语数据集,其经典应用场景在于为阿拉伯语大语言模型的预训练提供核心语料支撑。该数据集通过从Common Crawl中系统提取并精细清洗的纯阿拉伯语文本,能够有效训练出具备原生语言理解能力的基座模型,为后续的指令微调、多模态融合等高级任务奠定坚实的语言学基础。
解决学术问题
该数据集直接回应了阿拉伯语NLP研究中长期存在的两大核心挑战:数据稀缺性与文化真实性偏差。传统方法依赖英语翻译语料导致模型输出缺乏语言地道性与文化契合度,而本数据集通过提供超千亿词级的原生阿拉伯语文本,为构建真正理解阿拉伯语复杂形态变化、方言变体及文化语境的语言模型提供了可能。其意义在于打破了英语中心主义的技术垄断,推动了计算语言学领域的语言公平与多样性发展。
实际应用
在实际应用层面,该数据集能够赋能多个关键领域:在智能客服系统中提升阿拉伯语对话生成的准确性与文化适应性;在教育科技领域支持个性化阿拉伯语学习工具的研发;在内容创作行业辅助生成符合当地价值观的媒体文本。更重要的是,它为阿拉伯地区政府部门、金融机构等提供了构建本土化AI解决方案的数据基础设施,有效降低了对国际化模型的依赖,保障了数字主权与文化安全。
数据集最近研究
最新研究方向
在阿拉伯语自然语言处理领域,随着大规模语言模型的兴起,阿拉伯语数据稀缺问题成为制约本领域发展的关键瓶颈。当前研究前沿聚焦于构建大规模、高质量且文化真实的阿拉伯语数据集,以支持原生阿拉伯语大模型的训练。101 Billion Arabic Words Dataset的发布标志着这一方向的重要突破,其通过从Common Crawl中提取并精细清洗阿拉伯语网页内容,提供了迄今规模最大的纯阿拉伯语语料库。该数据集直接应对了现有阿拉伯语模型依赖翻译数据导致的偏见问题,为开发语言和文化层面均具真实性的阿拉伯语模型奠定了数据基础。相关研究热点包括利用此类数据集进行端到端的阿拉伯语大模型预训练、探索方言与文化细微差别的建模,以及推动阿拉伯语NLP技术在数字平台中的公平性与包容性。这一进展不仅促进了阿拉伯语语言技术的本土化创新,也为全球多语言NLP的均衡发展提供了重要借鉴。
相关研究论文
- 1101 Billion Arabic Words DatasetClusterlab团队 · 2024年
以上内容由遇见数据集搜集并总结生成


