NJU-LINK/WebCompass
收藏Hugging Face2026-05-01 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/NJU-LINK/WebCompass
下载链接
链接失效反馈官方服务:
资源简介:
WebCompass是一个统一的多模态基准测试集,旨在评估大型语言模型(LLMs)在生成、编辑和修复功能性网页方面的能力。该数据集涵盖三种输入模态(文本设计文档、参考截图和视频演示)和三种任务家族(生成、编辑和修复)。生成任务包括从文本设计文档、参考截图和视频演示生成网页;编辑任务涉及向现有单页或多页网站添加新功能;修复任务则是修复损坏的网页以匹配目标截图。数据集结构包括多个配置和分割,每个配置对应不同的任务类型和输入模态。数据集还提供了详细的文件结构、数据格式和评估维度,支持多模态任务的全面评估。
WebCompass is a unified multimodal benchmark for evaluating LLMs ability to generate, edit, and repair functional web pages. It spans three input modalities — text design documents, reference screenshots, and video demonstrations — and three task families — generation, editing, and repair. The generation tasks involve creating web pages from scratch based on text design documents, reference screenshots, or video demonstrations. The editing tasks require adding new features to existing single- or multi-page sites. The repair tasks involve fixing broken pages to match target screenshots. The dataset includes multiple configurations and splits, each corresponding to different task types and input modalities. It also provides detailed file structures, data formats, and evaluation dimensions to support comprehensive assessment of multimodal tasks.
提供机构:
NJU-LINK
搜集汇总
数据集介绍
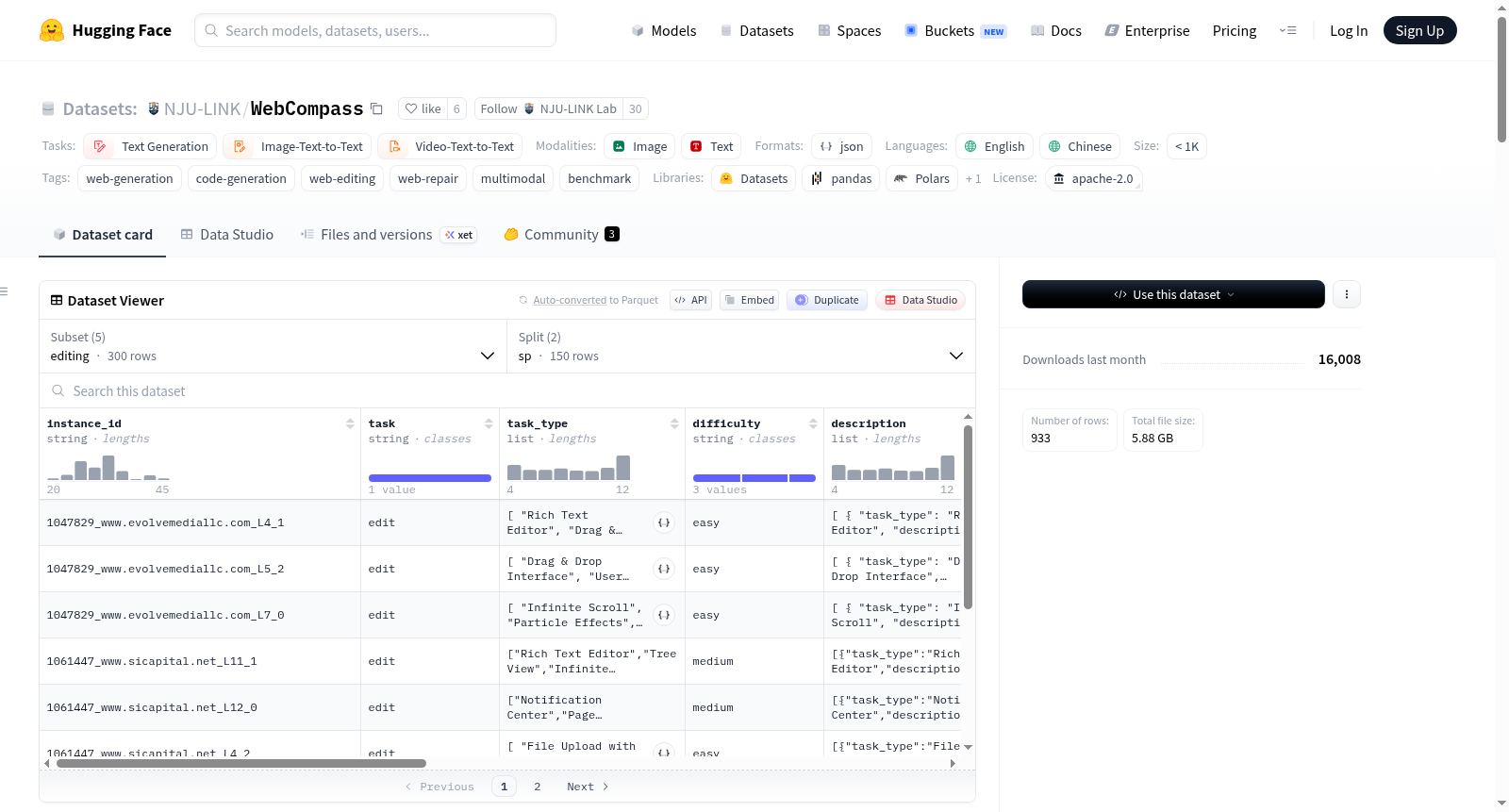
构建方式
WebCompass是一个统一的多模态基准数据集,旨在评估大语言模型在功能性网页生成、编辑与修复任务上的能力。该数据集通过精心设计的任务体系构建,涵盖文本设计文档、参考截图与视频演示三种输入模态,对应生成、编辑与修复三类核心任务。生成任务包含文本、图像与视频三种子配置,编辑与修复任务则进一步区分为单页面与多页面两种难度等级。数据以JSON Lines格式存储,并附带二进制资源文件,确保评估时对源代码、视觉资源与目标截图的完整引用。
使用方法
用户可通过HuggingFace Datasets库便捷加载不同任务配置。例如,使用load_dataset函数指定'text-generation'、'image-generation'或'editing'等配置名及相应的数据分片,即可获取对应的JSONL数据。对于编辑与修复任务,二进制资源文件(如截图与字体)需通过snapshot_download从HuggingFace Hub下载,并按照指定目录结构组织,以便评估器正确读取。GitHub仓库附带了现成的辅助脚本,可自动重建本地文件树,显著降低使用门槛。
背景与挑战
背景概述
WebCompass是由南京大学LINK实验室于2024年创建的多模态基准数据集,旨在系统性评估大语言模型在功能性网页生成、编辑与修复任务上的能力。该数据集覆盖文本设计文档、参考截图与视频演示三种输入模态,并划分出生成、编辑与修复三大任务族,填补了现有基准在网页交互式生成与细粒度修复评估方面的空白。通过引入运行性、规格实现与设计质量等多维度评分体系,WebCompass为衡量模型能否生成可运行、符合规范且视觉精准的网页提供了统一标准,对推动自动化网页开发与多模态理解领域的研究具有重要影响。
当前挑战
WebCompass所解决的领域挑战在于,现有大语言模型虽在代码生成任务上表现优异,但在生成可直接运行的、符合复杂视觉与交互规范的网页方面仍存在显著短板。构建过程中,团队需应对多模态数据对齐难题,即确保文本指令、截图或视频所表达的网页意图与最终生成的代码高度一致。此外,为评估编辑与修复任务,需要构建包含单页与多页结构的测试用例并人工标注预期输出,这要求大量高质量的前端开发资源与精细的评分标准设计,从而保证基准的可靠性与公平性。
常用场景
经典使用场景
WebCompass是一个统一的多模态基准数据集,旨在系统评估大语言模型在网页生成、编辑与修复任务中的能力。该数据集涵盖文本设计文档、参考截图与视频演示三种输入模态,并对应生成、编辑与修复三类核心任务。经典使用场景包括:给定一份详尽的功能规格说明,要求模型从零生成一个功能完整的网页;或者基于参考截图或操作视频,使模型理解用户意图并生成对应页面。此外,编辑任务要求模型为已有的单页或多页网站增添新功能,而修复任务则需模型将损坏的页面修正为与目标截图一致的状态。这种设计使得WebCompass能够全面检验模型对结构化网页代码、多模态信息融合及细粒度指令的理解与执行能力。
解决学术问题
WebCompass数据集解决了当前大语言模型研究中一个显著被忽视的问题:如何将网页的生成、编辑与修复能力纳入统一的、多模态的评估框架。现有基准大多聚焦于自然语言或代码生成,缺乏对功能完整网页(Functional Web Page)全生命周期任务的系统性度量。WebCompass通过引入三种输入模态和三类任务,为研究社区提供了一个可复现、可比较的评测平台,从而推动了以下学术问题的探索:模型是否能理解并生成包含交互逻辑和视觉设计的真实网页;模型在编辑已有代码库时能否保持结构一致性与功能完整性;以及模型在视觉对齐的修复任务中能否实现精准的像素级还原。该数据集填补了多模态网页智能测评的空白,为后续研究奠定了标准化评估基础。
实际应用
在实际应用层面,WebCompass数据集所定义的任务场景与当前软件工程和前端开发领域的自动化需求高度契合。例如,产品经理或设计师可将文本功能说明或设计稿截图输入模型,由模型自动生成原型页面,大幅缩短UI/UX设计迭代周期。编辑任务可辅助开发人员在现有项目中快速集成新组件或交互特性,减少手工编码的繁琐重复。修复任务则可用于自动化回归测试:当页面出现渲染异常或功能失效时,模型可依据预期截图主动定位并修复缺陷。此外,多模态能力使得低代码甚至无代码开发平台能够借助自然语言、图像或视频的混合描述生成网页,从而降低编程门槛,赋能非技术用户参与网站构建与维护。
数据集最近研究
最新研究方向
在当前大语言模型与多模态生成技术蓬勃发展的浪潮中,WebCompass数据集的问世为网页自动生成、编辑与修复领域树立了一面崭新的基准旗帜。该基准突破性地融合了文本设计文档、参考截图与视频演示三种输入模态,并系统性地划分了生成、编辑及修复三大任务族,精准回应了业界对于功能性网页端到端智能构建的迫切需求。前沿研究方向正沿着利用该基准深度评估并提升模型在复杂交互逻辑复现、跨模态视觉一致性保持以及缺陷页面自动诊断与修补等尖点能力上展开。伴随诸如自动化网页设计辅助工具、低代码开发平台等热点事件的兴起,WebCompass不仅为衡量大模型在真实网页开发场景中的落地效能提供了严苛标尺,更有望催化下一代具备高级抽象理解与精准执行能力的多模态代理的诞生,其深远意义在于重新定义了人机协作下网页生产的效率与质量边界。
以上内容由遇见数据集搜集并总结生成


