FOMO-MRI/FOMO45K
收藏Hugging Face2026-05-05 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/FOMO-MRI/FOMO45K
下载链接
链接失效反馈官方服务:
资源简介:
FOMO45K是一个大规模的大脑MRI扫描数据集,包含临床和研究级别的扫描。数据集包括多种MRI序列,如T1、MPRAGE、T2、T2*、FLAIR、SWI、T1c、PD、DWI、ADC等。数据集由9,490名受试者、11,967次会话和46,149次扫描组成。数据以NIfTI格式提供,并经过标准化和预处理,包括颅骨剥离、RAS重新定向和共配准。数据集来源于多个公共资源,如BraTS-GEN、MSD-BrainTumor、IXI等。数据集还包括元数据文件,如participants.tsv、mapping.tsv和mri_info.tsv,提供了受试者的人口统计、临床信息和MRI采集信息。
FOMO45K is a large-scale dataset of brain MRI scans, including both clinical and research-grade scans. The dataset includes a wide range of sequences, including T1, MPRAGE, T2, T2*, FLAIR, SWI, T1c, PD, DWI, ADC, and more. The dataset consists of 9,490 subjects, 11,967 sessions, and 46,149 scans. All data is provided as NIfTI-files and has been standardized and preprocessed (including skull stripped, RAS reoriented, co-registered). The dataset has been collected from public sources such as BraTS-GEN, MSD-BrainTumor, IXI, etc. It includes metadata files like participants.tsv, mapping.tsv, and mri_info.tsv, which provide demographic, clinical, and MRI acquisition information.
提供机构:
FOMO-MRI
搜集汇总
数据集介绍
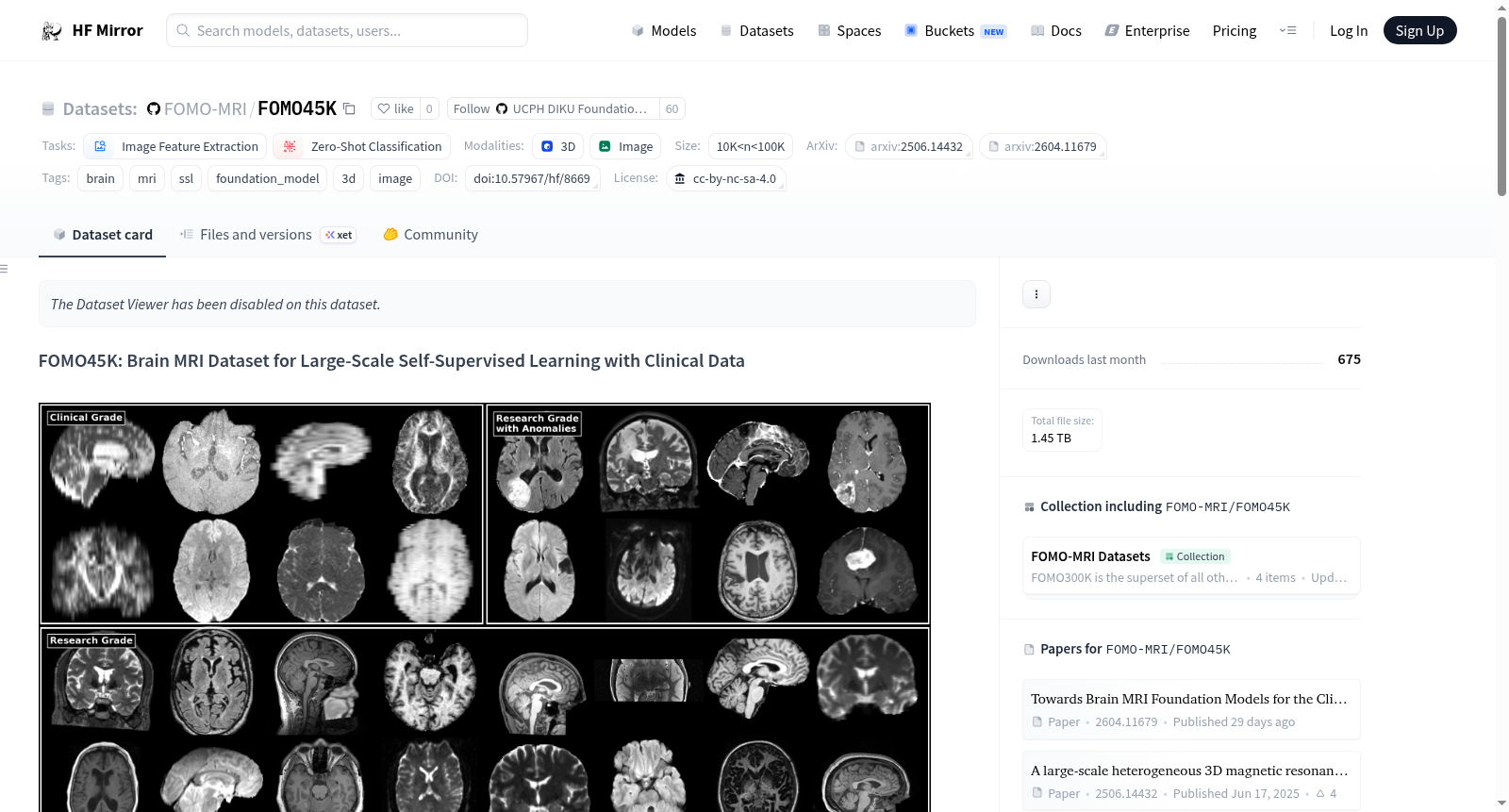
构建方式
FOMO45K数据集汇聚了来自BraTS-GEN、IXI、NKI等十余个公开数据源中的脑部MRI扫描,共计涵盖9,490名受试者、11,967次扫描会话以及46,149个扫描实例。所有原始数据均经过标准化预处理流程,包括去颅骨、重定向至RAS坐标空间以及图像配准,最终以NIfTI格式存储于按来源命名的子文件夹中。该数据集是更大规模FOMO300K集合的一个子集,专为开放获取而设计,无需登录或申请即可使用。
特点
FOMO45K的核心特色在于其高度的异质性与临床相关性,包含了T1、MPRAGE、T2、FLAIR、SWI、DWI、ADC等多种成像序列,能够充分反映真实临床场景中MRI数据的多样性。数据集提供了详尽的伴随元数据,包括受试者人口统计学与临床信息(如年龄、性别、利手、疾病分组)、扫描参数以及原始来源映射表,极大地方便了多模态分析与下游任务的开展。此外,所有数据均遵循CC-BY-NC-SA许可协议,兼顾了学术共享与版权合规。
使用方法
使用FOMO45K时,用户可直接从HuggingFace仓库下载NIfTI格式的图像文件,并利用提供的participants.tsv、mapping.tsv和mri_info.tsv等元数据表格进行数据筛选与组织。建议研究人员在自监督学习或特征提取任务中,将不同来源的扫描按序列类型或受试者分组进行划分,避免跨数据集组合以免引入重复样本。若需进一步了解预处理细节或验证结果,可参考随附的论文预印本,并根据要求正确引用相关文献。
背景与挑战
背景概述
脑部磁共振成像(MRI)作为神经科学研究与临床诊断的核心工具,其数据驱动的方法近年来因深度学习技术的突破而迎来变革。然而,大多数公开的脑MRI数据集规模有限、模态单一,且多来自研究级扫描,难以支撑大规模自监督学习模型的训练需求。FOMO45K数据集应运而生,由Stefano Cerri、Asbjørn Munk等研究人员联合丹麦等多国机构于2025年构建,并作为MICCAI 2025“FOMO25基础模型挑战赛”的核心数据资源。该数据集汇集了来自12个公开数据源的约45K张脑MRI扫描,涵盖T1、T2、FLAIR、SWI、DWI等多种临床与研究序列,横跨9,490名受试者及11,967个扫描会话。通过系统化的预处理与开放许可(CC-BY-NC-SA)分发,FOMO45K填补了大规模、异构、临床级脑MRI数据集的空白,为自监督学习、基础模型预训练及跨序列迁移研究提供了坚实基石,对推进神经影像学中的AI方法发展具有里程碑意义。
当前挑战
该数据集着力应对两大核心挑战。首先,在领域问题层面,传统脑MRI数据集多局限于单一序列(如T1)或研究级图像,导致自监督学习模型在真实临床场景下泛化能力不足;FOMO45K通过整合多种临床常用序列并覆盖正常与病理群体,致力于突破模态与人群异质性对模型鲁棒性的限制,推动脑影像基础模型的发展。其次,在构建过程中,面临跨数据源(如BraTS-GEN、IXI、NKI等)的格式统一、质量校准及隐私合规难题。具体地,需对来自不同机构、采集于不同扫描参数的原始NIfTI文件进行标准化头颅剥离、RAS重定向及共配准预处理,确保数据一致性;同时需平衡开放性(CC-BY-NC-SA)与部分数据使用协议(DUA)的约束,最终通过子集划分(如FOMO45K与FOMO260K)兼顾规模与可获取性,这一多源异构数据的整合与治理挑战极具代表性。
常用场景
经典使用场景
FOMO45K数据集汇聚了来自多个公开来源的约4.5万例脑部MRI扫描,涵盖T1、T2、FLAIR、DWI等多种序列,并经过配准、颅骨剥离等标准化预处理。其经典使用场景在于为大规模自监督学习提供高质量的预处理三维医学影像数据,常用于预训练基础模型,例如用于脑肿瘤分割、脑区划分或异常检测等下游任务的骨干网络初始化。研究者可利用该数据集的多样性与规模,在不依赖大量人工标注的条件下,学习鲁棒的脑部影像特征表征。
衍生相关工作
FOMO45K衍生出了多项代表性工作。作为FOMO-MRI数据集集合的一员,它支撑了MICCAI 2025的FOMO25基础模型挑战赛,参赛团队基于该数据开发并比较了多种自监督预训练策略。相关论文提出了大规模异构脑部MRI的自监督学习框架,验证了数据规模与多样性对预训练质量的提升作用。此外,该数据集还催生了面向三维医学影像的对比学习与掩码重建方法,并作为基准数据集用于评估零样本分类和特征提取等任务,推动了脑部MRI基础模型研究的标准化进程。
数据集最近研究
最新研究方向
FOMO45K作为一个包含约4.5万例脑部MRI扫描的大规模异质性三维磁共振影像数据集,近期在医学影像人工智能领域掀起了研究热潮。该数据集不仅整合了来自BraTS-GEN、IXI、NKI等多个公开来源的临床与研究级数据,涵盖了T1、T2、FLAIR、SWI、DWI等十余种序列,还经历了标准化预处理流程,为自监督学习与基础模型训练提供了前所未有的数据基础。值得注意的是,FOMO45K作为FOMO60K的子集,直接支撑了MICCAI 2025上举办的FOMO25基础模型挑战赛,这一赛事推动了脑MRI基础模型的基准测试与可重复性研究。其开放获取的CC-BY-NC-SA许可协议,结合丰富的元数据(包括人口统计学、临床诊断及采集参数),使得研究者能够在零样本分类、特征提取等前沿方向上验证模型泛化能力,进而加速了从影像生物标志物发现到临床决策支持工具转化的进程。
以上内容由遇见数据集搜集并总结生成


