e-mordovia-articles-2024
收藏Hugging Face2025-03-29 更新2025-03-30 收录
下载链接:
https://huggingface.co/datasets/slone/e-mordovia-articles-2024
下载链接
链接失效反馈官方服务:
资源简介:
e-mordovia-articles-2024是一个包含俄语、Erzya语和Moksha语的新闻文章平行语料库,收集自官方网站https://www.e-mordovia.ru。文章通过计算相似度进行配对,并经过母语者验证。数据集包含未对齐的句子和的对齐质量较差的句子,适合用于机器翻译模型的训练。
创建时间:
2025-03-28
搜集汇总
数据集介绍
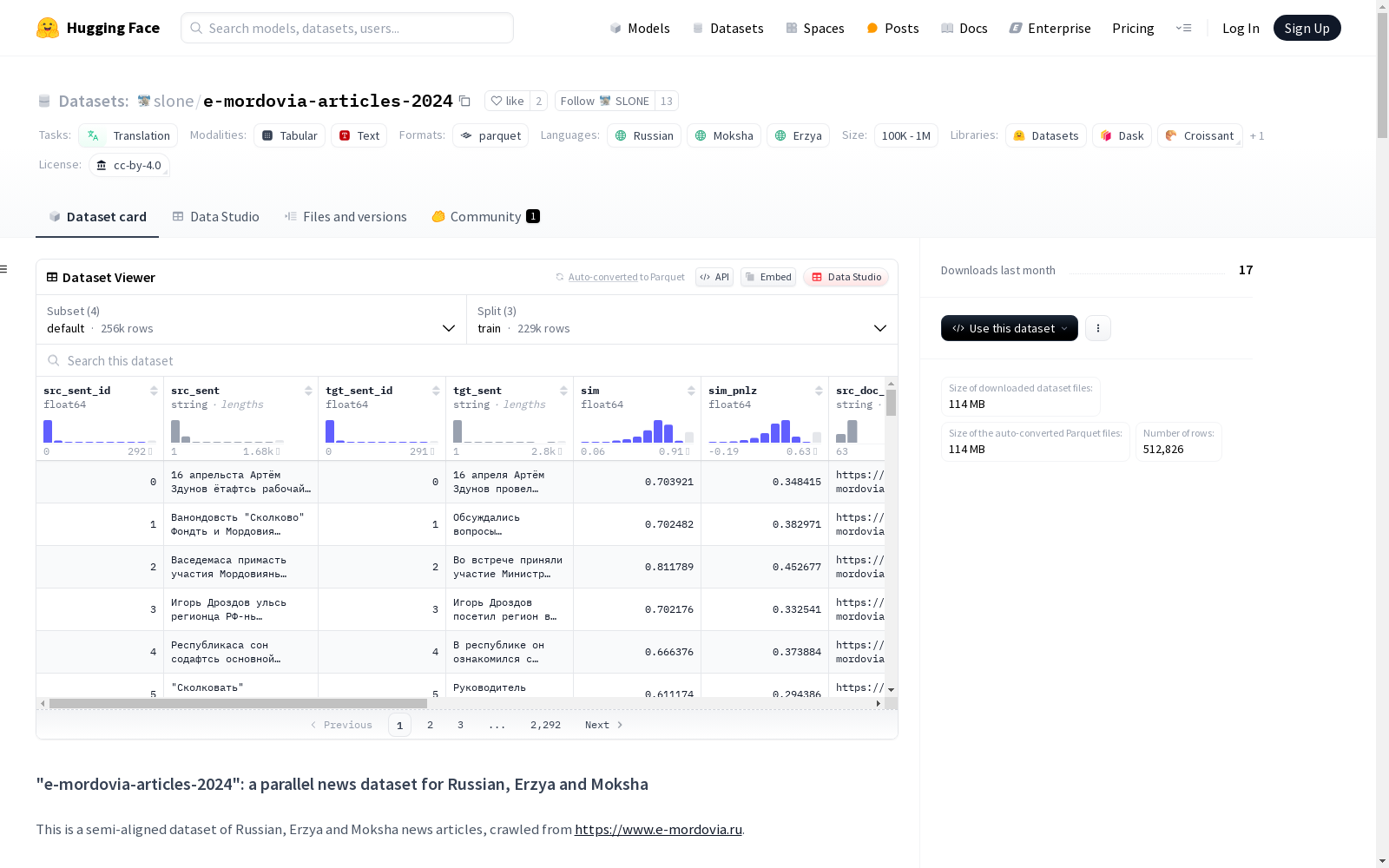
构建方式
该数据集通过半自动对齐算法构建,首先从俄罗斯莫尔多瓦共和国政府门户网站爬取俄语、埃尔齐亚语和莫克沙语新闻文章。采用多阶段相似度计算策略,筛选相似度高于0.6且发布时间差小于30天的文章对,并经过母语者人工校验。句子级对齐采用razdel分句工具与定制化LaBSE双语编码器,通过计算句子余弦相似度与字符长度比构建平行语料。数据划分依据源语言文章发布时间,2024年2月后文章作为验证集,5月后文章作为测试集,确保时序分布的合理性。
特点
数据集涵盖俄语、埃尔齐亚语和莫克沙语三种官方语言的平行文本,包含10万至100万量级的句子对。独特之处在于其聚焦乌拉尔语系濒危语言资源建设,所有文本均采用西里尔字母书写。数据实例包含对齐句子对与未对齐单句,每对数据附带相似度评分、文档链接及哈希值等元数据,支持质量过滤。由于新闻内容的时效特性,数据时间跨度从2016年延续至2024年,呈现动态语言演变特征。
使用方法
该数据集专为机器翻译模型训练设计,建议使用sim字段阈值过滤低质量对齐句对。处理时需注意去除基于src_sent和tgt_sent的重复条目,文档相似度docs_sim可作为辅助筛选指标。数据按语言对划分为myv-rus、mdf-rus和myv-mdf三个子集,各含标准训练集、验证集和测试集。使用前应充分考量源网站可能存在的报道倾向性,建议优先应用于语言结构学习而非事实性知识获取。
背景与挑战
背景概述
e-mordovia-articles-2024数据集由Artem Chapaev团队于2024年构建,旨在提升埃尔齐亚语(Erzya)和莫克沙语(Moksha)的机器翻译质量。该数据集采集自俄罗斯莫尔多瓦共和国政府官方网站e-mordovia.ru的新闻文章,涵盖2016年至2024年间发布的俄语、埃尔齐亚语和莫克沙语半对齐文本。作为乌拉尔语系中濒危的莫尔多瓦分支语言,埃尔齐亚语和莫克沙语的数字资源极为稀缺,该数据集的建立为低资源语言处理领域提供了重要研究素材。通过自动化句子对齐算法与人工验证相结合的方式,该数据集为跨语言信息处理、语言保存等研究开辟了新途径。
当前挑战
该数据集面临双重挑战:在领域问题层面,低资源语言机器翻译存在数据稀疏性难题,且乌拉尔语系与斯拉夫语系间的形态学差异加剧了跨语言建模难度;在构建过程中,原始新闻的非平行性导致内容偏差,自动对齐算法对语言变体的敏感度不足,约40%句子未能有效匹配。此外,政府新闻源的意识形态倾向可能引入潜在偏见,需要设计特定过滤机制。多语言混杂的文档结构也增加了句子级对齐的复杂度,现有相似度指标对黏着语的语言特性捕捉尚不完善。
常用场景
经典使用场景
在乌拉尔语系研究中,e-mordovia-articles-2024数据集为俄语、埃尔齐亚语和莫克沙语之间的机器翻译任务提供了珍贵的平行语料。该数据集通过半自动对齐算法构建的新闻句子对,成为训练神经机器翻译模型的理想素材,尤其适用于低资源语言场景下的跨语言转换研究。
衍生相关工作
基于该数据集的前身e-mordovia-articles-2023,研究者已开发出专用于埃尔齐亚语的LaBSE嵌入模型。当前版本进一步催生了莫克沙语编码器的优化工作,并推动建立乌拉尔语系多语言评估基准,为后续的跨语言预训练模型提供关键数据支撑。
数据集最近研究
最新研究方向
随着低资源语言保护意识的增强,e-mordovia-articles-2024数据集为莫克沙语和埃尔齐亚语这类濒危乌拉尔语系语言的机器翻译研究提供了重要资源。当前研究聚焦于多语言神经机器翻译模型的优化,特别是针对俄语与两种少数民族语言间的低资源场景。最新进展体现在利用跨语言预训练技术缓解数据稀疏问题,通过LaBSE等句向量编码器提升句子对齐质量。该数据集独特的半对齐特性促使学术界探索噪声鲁棒性训练方法,同时其政治新闻语料特性也引发了对翻译模型中意识形态偏差检测的讨论。在语言技术领域,该数据集正推动着濒危语言数字化保护的实践,为构建包容性语言技术基础设施提供了典型案例。
以上内容由遇见数据集搜集并总结生成


