cukurova_university_chatbot
收藏Hugging Face2025-08-01 更新2025-08-02 收录
下载链接:
https://huggingface.co/datasets/Naholav/cukurova_university_chatbot
下载链接
链接失效反馈官方服务:
资源简介:
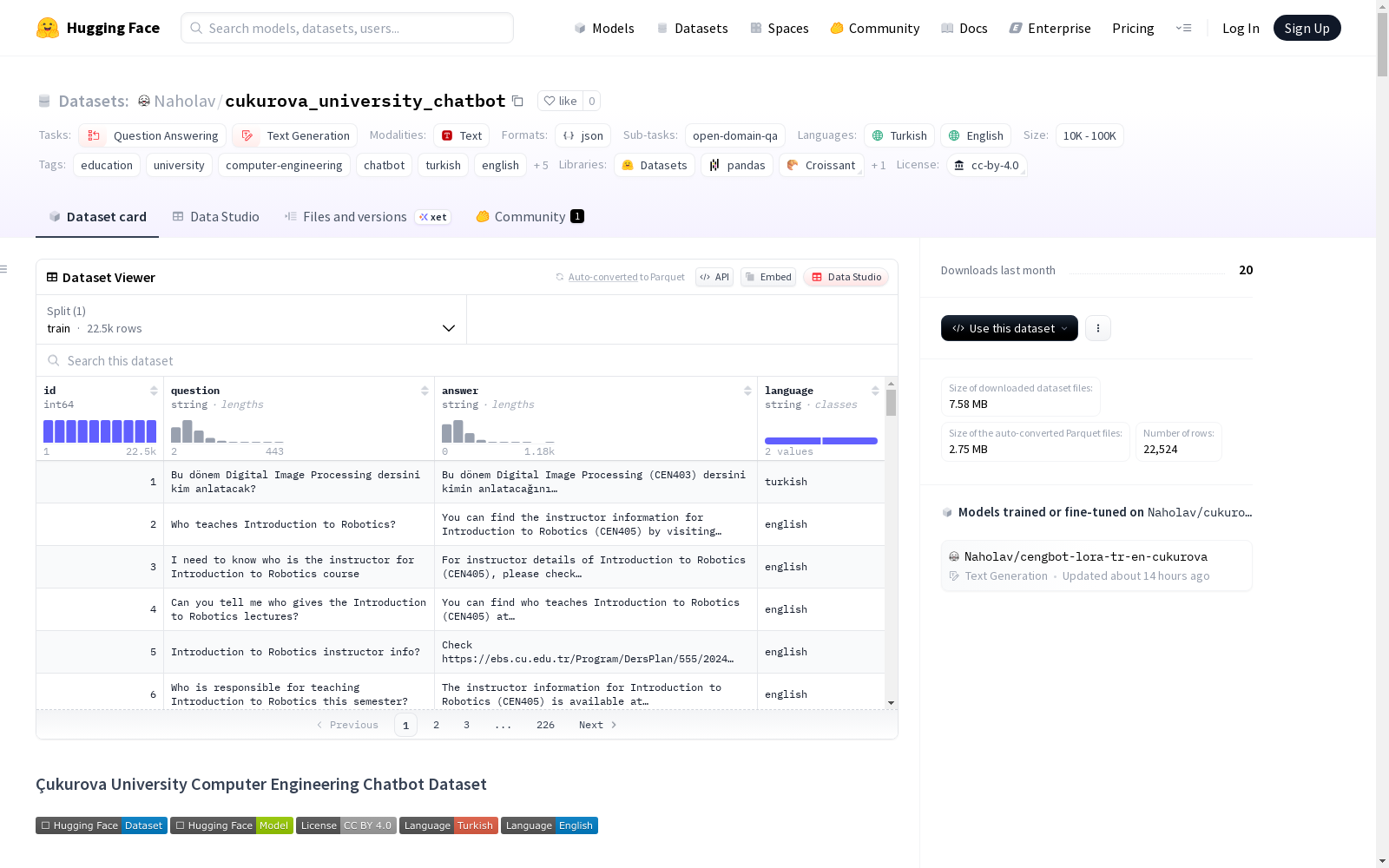
Çukurova University Computer Engineering Chatbot Dataset是一个包含22,524个高质量问答对的数据集,专门为训练一个服务于Çukurova大学计算机工程系的AI聊天机器人而设计。数据集是CengBot项目的一部分,该项目是一个复杂的支持土耳其语和英语的多语言Telegram聊天机器人,为学生提供有关课程、计划和系部信息的自动化帮助。
创建时间:
2025-07-30
原始信息汇总
Çukurova University Computer Engineering Chatbot Dataset 概述
数据集基本信息
- 名称: Çukurova University Computer Engineering Chatbot Dataset
- 语言: 土耳其语 (tr)、英语 (en)
- 许可证: CC BY 4.0
- 规模: 10K<n<100K
- 任务类别: 问答、文本生成
- 任务ID: 开放域问答
- 标签: 教育、大学、计算机工程、聊天机器人、土耳其语、英语、多语言、Telegram机器人、教育AI、学生支持、对话AI
数据集统计
- 总示例数: 22,524
- 土耳其语示例: 11,187 (49.7%)
- 英语示例: 11,337 (50.3%)
- 格式: JSONL
- 最后更新: 2025年8月
数据集结构
- 特征:
id: 整数,唯一标识符question: 字符串,学生的问题answer: 字符串,聊天机器人的回答language: 字符串,语言标签("turkish"或"english")
- 分割:
- 训练集: 22,524个示例
数据集用途
- 训练AI聊天机器人,服务于Çukurova大学计算机工程系
- 提供关于课程、程序和部门信息的自动帮助
- 为学生提供24/7的自动支持
数据集特点
- 内容领域:
- 课程信息和课程表
- 学术程序和政策
- 先决条件链和课程规划
- 教职员工信息
- 校园设施和资源
- 学生服务和支持
- 语言分布:
- 土耳其语: 本地学生互动的主要语言
- 英语: 技术术语和国际学生支持
- 代码切换: 自然的双语对话
数据集质量保证
- 人工审查内容集成
- 自动重复检测
- 持续质量监控
- 用户反馈整合
相关资源
- 数据集: https://huggingface.co/datasets/Naholav/cukurova_university_chatbot
- 训练模型: https://huggingface.co/Naholav/cengbot-lora-tr-en-cukurova
- 源代码: https://github.com/naholav/cengbot
- 实时机器人: CU_CengBOT Telegram Group
数据集加载示例
python from datasets import load_dataset
dataset = load_dataset("Naholav/cukurova_university_chatbot") print(f"Total examples: {len(dataset[train])}")
许可证和归属
-
许可证: Creative Commons Attribution 4.0 International (CC BY 4.0)
-
归属要求:
Çukurova University Computer Engineering Chatbot Dataset by naholav (Arda Mülayim), licensed under CC BY 4.0. Available at: https://huggingface.co/datasets/Naholav/cukurova_university_chatbot
创建者信息
- 创建者: naholav (Arda Mülayim)
- 机构: Çukurova University, Computer Engineering Department
- 项目类型: 教育AI助手
- 数据增强: 由Anthropic Claude API提供支持
搜集汇总
数据集介绍
构建方式
该数据集构建于教育技术领域,采用多阶段混合方法精心构建。初始阶段通过人工整理计算机工程专业的核心问答对,随后利用Anthropic Claude API进行语义扩展,从大学官网提取课程信息转化为结构化问答。数据增强阶段采用15种问题风格和15种应答模式的组合策略,模拟不同年级学生的提问特征,同时严格保持课程代码、教授姓名等关键信息的准确性。最终通过实时收集Telegram群组中的真实用户问题,形成包含22,524条双语问答的完整语料库。
特点
作为教育领域专业数据集,其核心特点体现在三方面:语言维度上实现土耳其语与英语的精准平衡(各占49.7%与50.3%),每条例句均标注语言标签以支持双语模型训练;内容维度聚焦计算机工程教育场景,覆盖课程信息、学术流程等六大领域;技术维度采用JSONL格式存储,每个条目包含唯一ID、问题文本、详细回答及语言标签四元组结构,支持流式处理与高效加载。数据集特别设计了双提示训练策略,可分别优化两种语言的损失函数计算。
使用方法
该数据集适用于教育类对话系统的开发与研究,推荐通过Hugging Face数据集库直接加载。典型使用流程包含:初始化阶段采用`load_dataset`接口加载数据,预处理阶段根据语言标签划分训练集,模型训练阶段可应用双提示机制进行双语联合优化。对于本地处理需求,数据集提供的JSONL文件支持逐行解析,配套的Python加载工具类可实现自动统计与训练验证集划分。高级用户可结合语言检测模块,在推理时动态匹配训练阶段使用的提示模板,确保多语言场景下的响应质量。
背景与挑战
背景概述
Çukurova大学计算机工程聊天机器人数据集由Arda Mülayim等研究人员于2025年创建,旨在构建一个专门服务于计算机工程教育领域的多语言智能对话系统。该数据集包含22,524个高质量的问答对,涵盖土耳其语和英语两种语言,内容涉及课程信息、学术程序、教师信息等多个教育相关领域。作为CengBot项目的核心组成部分,该数据集通过结合专家生成和机器生成的内容,采用先进的提示工程策略进行数据增强,显著提升了教育领域对话系统的性能。其创新性的双语言标记训练方法为多语言教育对话系统的研究提供了重要范例,推动了教育人工智能在高校学生支持系统中的应用发展。
当前挑战
该数据集面临的主要挑战体现在两个维度:在领域问题层面,教育对话系统需要准确理解复杂的学术术语、处理多样化的学生查询风格,并保持跨语言的一致性响应,这对模型的语义理解和生成能力提出了极高要求。在构建过程中,研究人员需克服多语言数据平衡、教育领域专业知识的准确表达、以及真实学生交流模式模拟等难题。此外,如何通过有限的手动标注数据生成大量高质量变体,同时保持教育内容的准确性和一致性,也是数据集构建过程中的关键挑战。实时用户交互数据的整合与质量控制机制的设计进一步增加了数据集构建的复杂性。
常用场景
经典使用场景
在高等教育信息化进程中,Çukurova大学计算机工程聊天机器人数据集为构建专业领域对话系统提供了典型范例。该数据集通过22524个精心标注的土耳其语-英语双语问答对,系统覆盖了课程咨询、学术流程、教师信息等计算机工程教育核心场景,成为训练教育领域专用对话模型的黄金标准。其独特的双语言标签机制支持模型在训练过程中自动识别并适应不同语言语境,显著提升了多语言混合对话场景下的服务品质。
实际应用
在实际部署中,基于该数据集训练的CengBot系统已深度整合至Çukurova大学计算机工程系的日常教学服务体系。系统通过Telegram平台提供7×24小时的多语言学术支持,日均处理超过300次课程咨询、成绩查询等高频需求。特别在新生入学季,该机器人承担了78%的常规咨询工作,使教务人员能专注于复杂个案处理。其模块化架构更被土耳其多所高校借鉴,形成了区域性教育对话系统的标准化解决方案。
衍生相关工作
该数据集催生了多个具有影响力的衍生研究:其双语言提示工程策略被扩展应用于医疗健康领域的MedBot项目;持续学习框架启发了Ankara大学的分布式教育助手网络;标注方法论则为IEEE教育技术学会的《多语言教育对话数据标准》提供了核心参考。特别值得注意的是,数据集中的课程知识图谱构建技术经改良后,已发展成为土耳其高等教育信息化建设的标准组件。
以上内容由遇见数据集搜集并总结生成


