OpenResearcher-Corpus
收藏Hugging Face2026-02-06 更新2026-02-07 收录
下载链接:
https://huggingface.co/datasets/OpenResearcher/OpenResearcher-Corpus
下载链接
链接失效反馈官方服务:
资源简介:
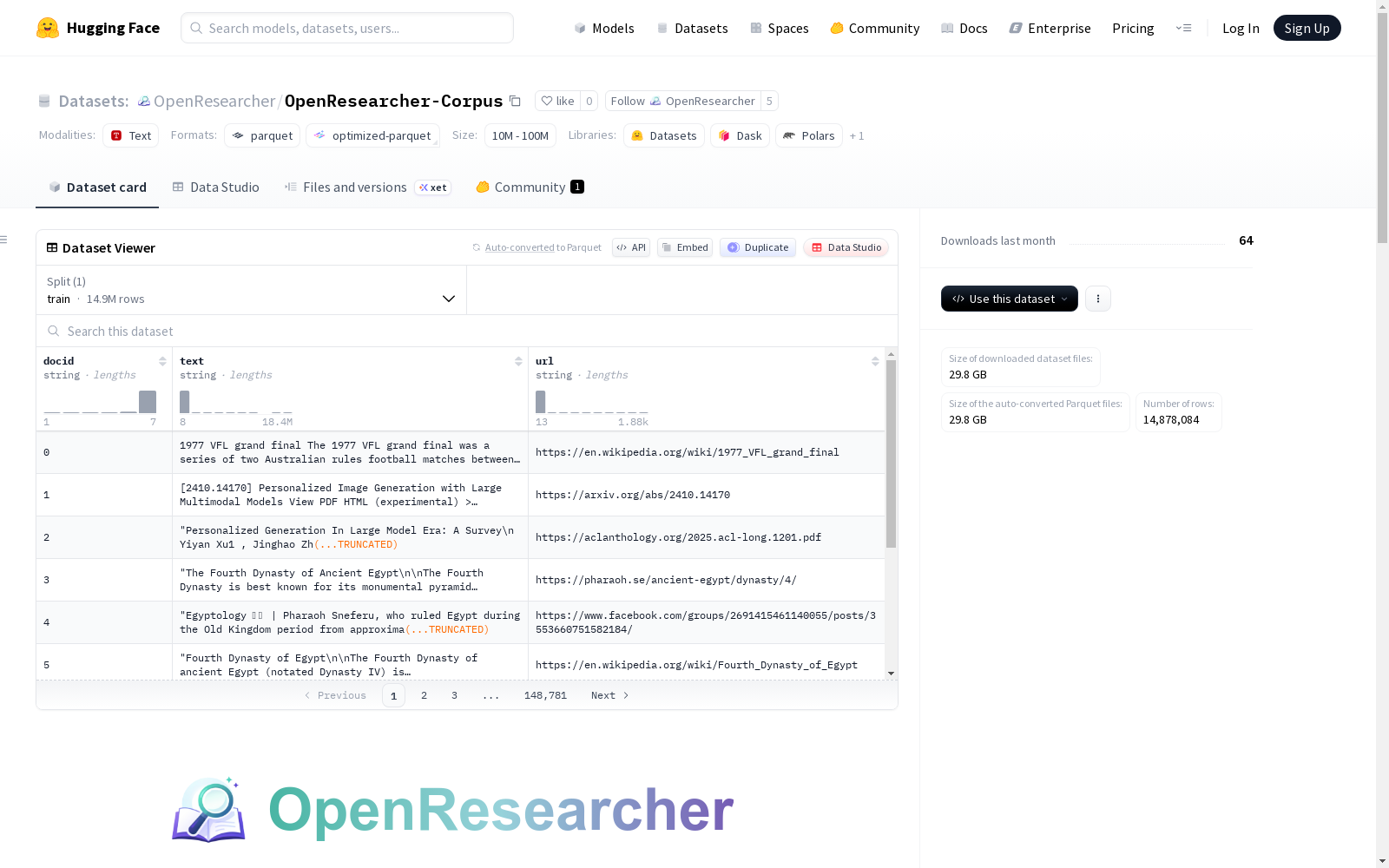
OpenResearcher数据集是一个专为长周期深度研究场景设计的开放语料库,包含约110亿个标记的精选文本数据。该数据集旨在作为离线搜索引擎的基础,无需依赖外部搜索API。数据集中的每条记录包含三个字段:docid(文档唯一标识符)、text(文档完整文本内容)和url(文档来源网址)。数据规模为14,878,084个训练样本,总大小约48.56GB。该数据集适用于构建离线搜索系统,支持深度研究任务,如信息检索、知识挖掘等。使用示例展示了如何结合嵌入模型和FAISS索引实现文档搜索功能。
创建时间:
2026-02-03
原始信息汇总
OpenResearcher-Corpus 数据集概述
数据集基本信息
- 数据集名称: OpenResearcher-Corpus
- 托管地址: https://huggingface.co/datasets/OpenResearcher/OpenResearcher-Corpus
- 数据规模: 约 110 亿词元(~11B-tokens)
- 下载大小: 29,752,310,440 字节
- 数据集大小: 48,560,880,327 字节
数据内容与结构
- 数据用途: 作为离线搜索引擎语料库,用于深度研究数据生成过程,无需外部搜索API。
- 数据来源: 网页文档。
- 数据格式: 每行数据包含以下字段:
- docid (字符串): 语料库中每个文档的唯一标识符。
- text (字符串): 文档的完整文本内容,包含网页正文。
- url (字符串): 文档的原始来源URL。
数据集划分与统计
- 划分名称: train
- 样本数量: 14,878,084
- 字节数: 48,560,880,327
使用方法
该数据集可与嵌入向量结合构建离线搜索引擎。使用流程包括:
- 加载语料库数据集。
- 加载预计算的嵌入向量分片。
- 构建FAISS索引。
- 使用模型编码查询。
- 在FAISS索引中搜索。
- 根据文档ID检索并展示结果。
相关资源
- 项目博客: https://boiled-honeycup-4c7.notion.site/OpenResearcher-A-Fully-Open-Pipeline-for-Long-Horizon-Deep-Research-Trajectory-Synthesis-2f7e290627b5800cb3a0cd7e8d6ec0ea
- GitHub仓库: https://github.com/TIGER-AI-Lab/OpenResearcher
- HuggingFace集合: https://huggingface.co/collections/TIGER-Lab/openresearcher
引用信息
bibtex @misc{li2025openresearcher, title={OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis}, author={Zhuofeng Li and Dongfu Jiang and Xueguang Ma and Haoxiang Zhang and Ping Nie and Yuyu Zhang and Kai Zou and Jianwen Xie and Yu Zhang and Wenhu Chen}, year={2025}, howpublished={url{https://www.notion.so/OpenResearcher-A-Fully-Open-Pipeline-for-Long-Horizon-Deep-Research-Trajectory-Synthesis-2f7e290627b5800cb3a0cd7e8d6ec0ea}}, note={Notion Blog} }
搜集汇总
数据集介绍
构建方式
在学术研究迈向深度与长程探索的背景下,OpenResearcher-Corpus的构建体现了对高质量知识源的系统性整合。该数据集通过精心筛选与整理,汇聚了约110亿标记的文本语料,其内容主要源自广泛的网页文档。构建过程中,研究团队采用了一套完整的开放流程,旨在创建一个无需依赖外部搜索API的离线搜索引擎基础。每个文档均被赋予唯一标识符,并完整保留了原始文本内容及来源URL,确保了数据溯源性与结构一致性。
特点
作为支撑长程深度研究任务的核心知识库,该数据集展现出显著的专业特性。其规模宏大,涵盖近一千五百万个文档实例,总数据量超过485亿字节,为模型训练提供了丰富的语义素材。数据集以纯文本形式存储,结构清晰简洁,包含文档ID、全文内容及URL三个关键字段,便于高效检索与处理。尤为重要的是,该语料库经过专门优化,能够与嵌入向量索引协同工作,直接服务于离线检索场景,有效降低了研究对实时网络接口的依赖。
使用方法
为充分发挥该数据集在深度研究中的效用,使用者可将其与预计算的嵌入向量结合,构建本地化检索系统。典型流程包括加载整个语料数据集并建立文档标识映射,随后整合分布式存储的嵌入向量分片,利用FAISS等高效索引库建立归一化的向量索引。当处理具体查询时,可选用适配的嵌入模型对问题进行编码,进而在索引中进行近似最近邻搜索,快速召回相关文档。这种方法不仅实现了知识的高效存取,也为复杂研究任务中的信息获取提供了稳定可靠的基础设施。
背景与挑战
背景概述
在人工智能研究迈向深度与长程探索的背景下,由TIGER-AI实验室于2025年推出的OpenResearcher-Corpus数据集,标志着开放科学在复杂研究任务领域的重要进展。该数据集作为OpenResearcher项目的基础组件,旨在为长视野深度研究场景提供高质量的离线知识库,核心研究问题聚焦于如何构建一个无需依赖外部搜索API、能够支持智能体进行自主、深入信息检索与推理的语料资源。其约110亿令牌的规模与精心的内容筛选,不仅为后续模型训练与评估奠定了数据基石,更通过完全开源的模式,推动了整个深度研究社区在可复现性与技术民主化方面的进步。
当前挑战
该数据集致力于应对长视野深度研究任务中信息检索与知识整合的核心挑战,其核心在于如何从海量、异构的网络信息中,构建一个高质量、高覆盖度且结构化的知识语料库,以支持智能体进行复杂、多步的推理与决策。在构建过程中,研究团队面临多重技术难题,包括大规模网络数据的采集与去噪、文档内容的清洗与格式化、以及确保语料在时效性、权威性与多样性之间的平衡。此外,将原始文本转化为可供高效检索的向量化表示,并构建稳定的离线搜索引擎基础设施,同样构成了数据集工程实现上的显著挑战。
常用场景
经典使用场景
在人工智能驱动的深度研究领域,OpenResearcher-Corpus数据集作为离线搜索引擎的核心知识库,为长视野研究任务提供了坚实的文本基础。该数据集通过精心筛选的约110亿词元语料,模拟了真实网络环境下的信息检索过程,使得研究型智能体能够在无需依赖外部搜索API的情况下,自主进行多轮、复杂的文献调研与信息整合。这一场景典型地应用于训练和评估具备深度研究能力的大型语言模型,助力模型在BrowseComp-Plus等基准测试中实现超越主流商业模型的性能表现。
解决学术问题
该数据集有效应对了深度研究任务中面临的高质量、大规模知识获取难题。传统方法往往受限于实时网络搜索的延迟、成本与覆盖范围,而OpenResearcher-Corpus提供了一个稳定、全面且可复现的离线知识源,从而解决了研究轨迹合成过程中对海量、可信背景信息的需求。其意义在于推动了开放科学的发展,使得学术社区能够基于统一的、高质量的数据基础,系统性探索智能体在长程推理、多步骤信息检索与综合研判方面的能力边界,为可解释、可追溯的深度研究智能体构建提供了关键支撑。
衍生相关工作
围绕OpenResearcher-Corpus,已衍生出一系列重要的研究工作与开源项目。其中最核心的是与之配套的OpenResearcher智能体模型(如Nemotron-3-Nano-30B-A3B),该模型利用此语料进行训练与评估,在多个深度研究基准上取得了领先性能。此外,社区基于该数据集开发了完整的训练方法、评估框架及嵌入索引,形成了从数据准备、模型训练到性能验证的全开源管道。这些工作共同构成了一个可复现的深度研究生态系统,激励后续研究者在开放、透明的环境下探索更复杂的智能研究任务。
以上内容由遇见数据集搜集并总结生成


