bingbangboom/cleaned-asr-transcripts-hinglish
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/bingbangboom/cleaned-asr-transcripts-hinglish
下载链接
链接失效反馈官方服务:
资源简介:
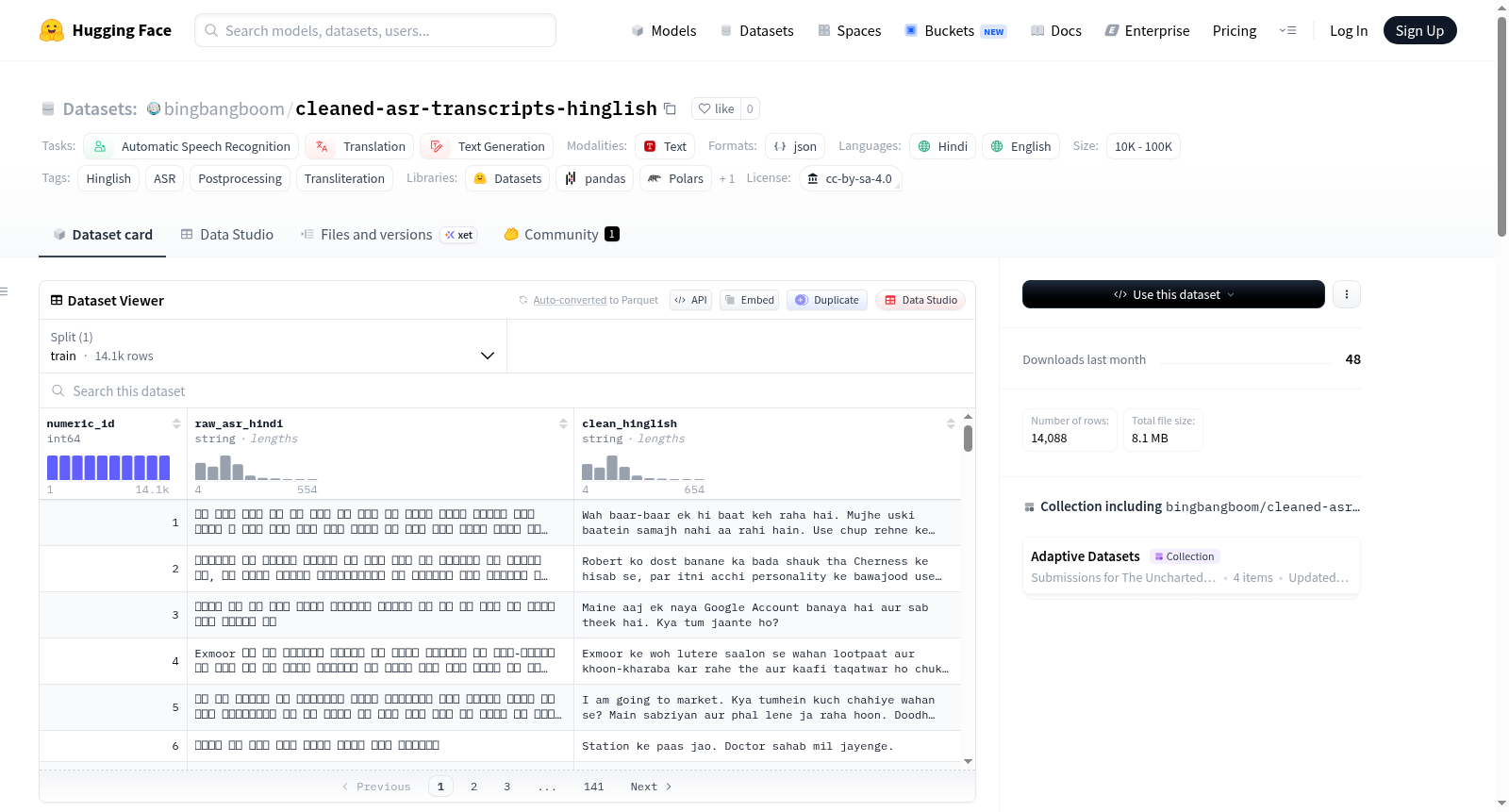
`bingbangboom/cleaned-asr-transcripts-hinglish` 是一个平行语料库,包含14k+对原始-合成印地语ASR(自动语音识别)转录及其干净、正确标点和转写的印地英语(罗马化印地语)对应文本。该数据集专门设计用于ASR后处理、转写模型和微调大型语言模型(LLMs)以理解和生成高质量的、会话式的印地英语。印地英语是印地语和英语的混合语言,是南亚数亿人在互联网和日常交流中的主要语言。数据集还包含了172种不同的ASR错误类型,覆盖了语音、拼写、分段、同音词、形态句法、不流畅和会话、代码转换、格式和标点、方言和语域以及模型幻觉等多个类别。每个实例都是一个包含三个字段的JSON对象:numeric_id、raw_asr_hindi和clean_hinglish。
`bingbangboom/cleaned-asr-transcripts-hinglish` is a parallel corpus containing **14k+** pairs of raw-synthetic Hindi ASR (Automatic Speech Recognition) transcripts mapped to their clean, properly punctuated, and transliterated Hinglish (Romanized Hindi) counterparts. This dataset is specifically designed for ASR post-processing, transliteration models, and fine-tuning Large Language Models (LLMs) to understand and generate high-quality, conversational Hinglish. Hinglish (a portmanteau of Hindi and English) is the dominant conversational language on the internet and in daily communication for hundreds of millions of people in South Asia. The dataset also includes **172 distinct ASR error types** mapped across several major linguistic, orthographic, and formatting categories. Each instance in the dataset is formatted as a JSON object with three fields: `numeric_id`, `raw_asr_hindi`, and `clean_hinglish`.
提供机构:
bingbangboom
搜集汇总
数据集介绍
构建方式
该数据集以合成方式构建,旨在映射原始印地语ASR转录文本到经过清洗、标点校正并转写为罗马化印地语(Hinglish)的干净版本。构建过程中,系统性地模拟了172种不同的ASR错误类型,涵盖语音声学、正字法、切分、同音词、形态句法、不流畅与对话、代码切换、标点格式、方言口音及模型幻觉等多个维度。约3000个样本源自tiny-aya-translate/hinglish-casual语料库,用以奠定对话基础。最终形成超过14,000对平行语料,每对包含原始印地语文本与对应的罗马化清洗文本。
特点
该数据集的核心特点在于其针对Hinglish语言的专门化设计,Hinglish作为南亚地区数百万人日常沟通的主流混合语言,在传统ASR系统中长期被忽视。数据集不仅纠正了ASR输出中常见的Devanagari脚本偏见,还系统覆盖了从语音混淆到代码切换的丰富错误类型,使模型能够生成流畅自然的罗马化印地语。此外,数据集的规模超过14,000对,并采用CC BY-SA 4.0许可,便于学术与工业界广泛使用。
使用方法
数据集适用于ASR后处理、转写模型训练及大语言模型的微调。用户可通过HuggingFace的datasets库轻松加载数据,每个实例包含唯一标识符numeric_id、原始Devanagari转录raw_asr_hindi以及清洗后的罗马化文本clean_hinglish。可用于构建将错误百出的ASR输出转化为高质量Hinglish文本的流水线,或作为平行语料增强模型的跨语言理解与生成能力。数据格式为JSON,便于集成到各类深度学习框架中。
背景与挑战
背景概述
在当代自然语言处理与语音识别领域,印地语-英语混合语(Hinglish)作为南亚地区数亿网民日常交流的主导语言,其重要性日益凸显。然而,传统自动语音识别(ASR)系统过度偏向输出天城体梵文(Devanagari)的正式印地语,与用户实际使用的罗马化混合语存在显著割裂。为弥合这一鸿沟,该数据集于2024年由研究人员基于Adaptive Data发起的Uncharted Data Challenge创建,核心研究问题聚焦于如何将原始ASR转录文本转化为流畅、自然的罗马化Hinglish。通过提供14,000余对平行语料,该数据集对ASR后处理、音译模型及大语言模型微调产生了重要影响,成为连接正式语音识别与真实口语表达的关键桥梁。
当前挑战
该数据集旨在解决的核心领域挑战是ASR系统对Hinglish的严重表征不足,传统模型无法捕捉用户实际使用的混合语风格、非正式拼写及语码转换现象。构建过程中面临的核心挑战在于系统性地模拟172种ASR错误类型,涵盖语音混淆、拼写变异、分词错误、同音词混淆、形态句法不一致、会话不流利现象、语码转换偏差、标点格式冲突以及方言影响等复杂维度。此外,还需确保合成生成的错误样本既具代表性又能真实反映现实场景,同时平衡不同错误类型的分布,并保证清洗后的Hinglish文本在语法正确性与自然度之间取得恰当平衡。
常用场景
经典使用场景
在自动语音识别(ASR)后处理任务中,该数据集被经典地用于将原始、充满错误的印地语天城文ASR转录文本,转化为语法正确、标点完善且使用罗马字母书写的流利印地英语(Hinglish)。其核心应用场景包括训练序列到序列模型,以纠正ASR系统常见的171种错误类型,如音位混淆、词缀分割错误、代码切换不一致及模型幻觉等,从而提升最终转录文本的自然度和可读性。
衍生相关工作
该数据集衍生出了多项相关经典工作,包括基于Transformer架构的ASR文本后处理模型、专门用于印地英语音译的神经机器翻译系统,以及针对代码混合语言的预训练语言模型微调方案。研究者还利用其错误类型标注体系开发了更鲁棒的语音识别评估框架,推动了低资源语言清洁数据生成技术的进步,并启发了类似方言到标准语转换数据集的构建。
数据集最近研究
最新研究方向
该数据集聚焦于南亚地区广泛使用的印英混合语(Hinglish)自动语音识别后处理与音译任务,通过构建14k+对原始印地语ASR转录与净化Hinglish文本的平行语料,系统性模拟了172种ASR错误类型(包括音韵混淆、脚本转换、形态句法错误及模型幻觉等),旨在弥合传统ASR系统偏向天城文书写的正式印地语与用户实际使用罗马化混合语之间的鸿沟。这一方向与当前多语言、低资源场景下语音接口的实用化趋势深度契合,尤其服务于社交媒体、电商搜索及语音助手等真实对话场景,对推动南亚互联网语言包容性、优化大语言模型在混合语态下的生成质量具有显著意义。
以上内容由遇见数据集搜集并总结生成


