CT-EBM-SP
收藏Hugging Face2026-02-06 更新2026-02-07 收录
下载链接:
https://huggingface.co/datasets/IIC/CT-EBM-SP
下载链接
链接失效反馈官方服务:
资源简介:
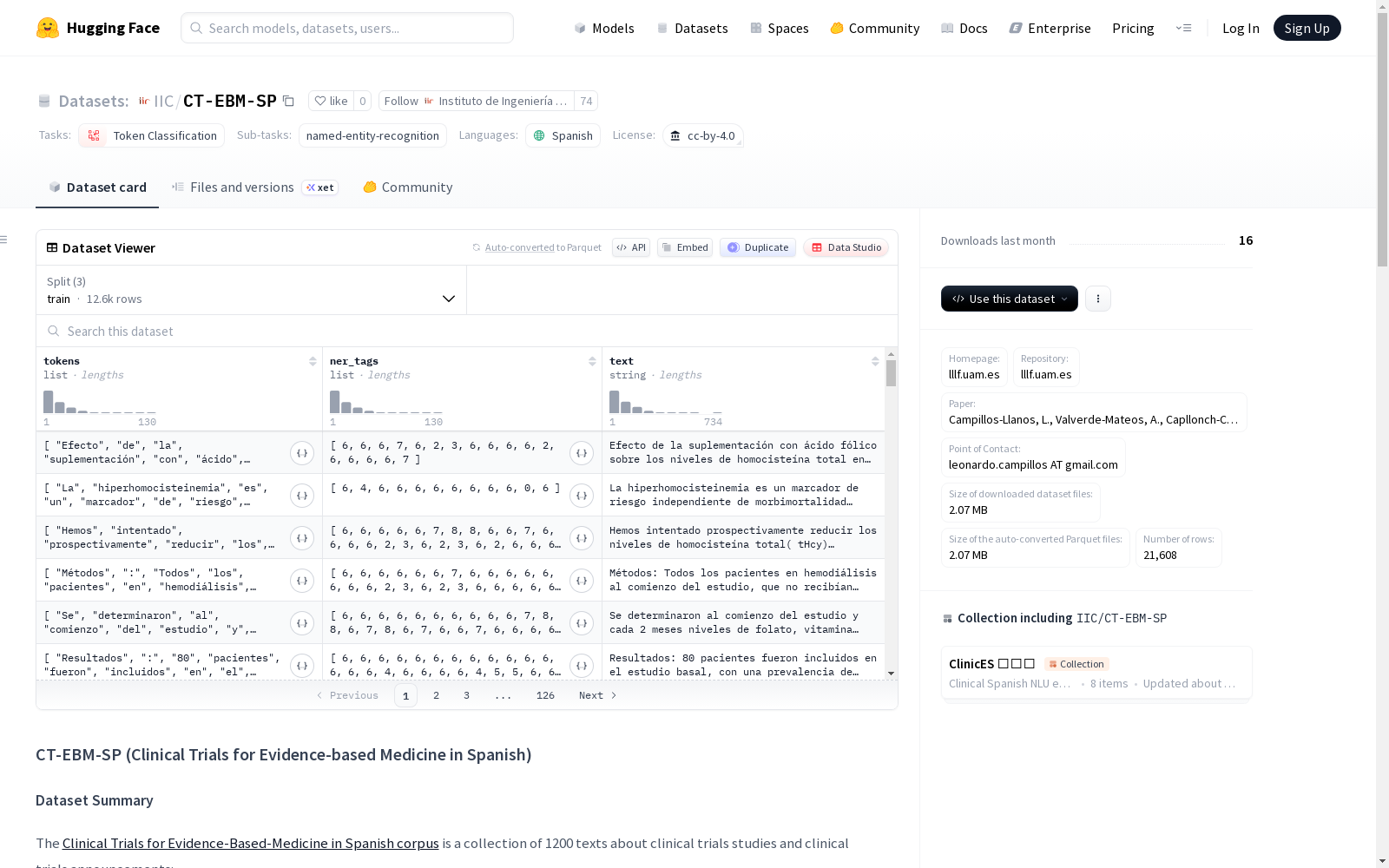
CT-EBM-SP(西班牙语循证医学临床试验)数据集是一个专门用于医学命名实体识别任务的西班牙语语料库。该数据集包含1200篇临床研究相关的文本,其中500篇为来自PubMed或SciELO的期刊摘要,700篇为来自欧洲临床试验注册中心和西班牙临床试验库的临床试验公告。数据集共包含292,173个标记和46,699个医学实体,这些实体根据统一医学语言系统(UMLS)分为四类:解剖结构(ANAT)、化学物质(CHEM)、病理状况(DISO)以及治疗和诊断程序(PROC)。数据集分为训练集(175,203个标记,28,101个实体)、开发集(58,670个标记,9,629个实体)和测试集(58,300个标记,8,969个实体)。该数据集采用CC-BY 4.0许可协议,主要用于医学信息处理研究,但需注意其仍在开发中,不应用于无人工监督的医疗决策。
提供机构:
Instituto de Ingeniería del Conocimiento
创建时间:
2026-02-06
原始信息汇总
CT-EBM-SP 数据集概述
数据集基本信息
- 数据集名称: CT-EBM-SP (Clinical Trials for Evidence-based Medicine in Spanish)
- 主页: http://www.lllf.uam.es/ESP/nlpmedterm_en.html
- 仓库地址: http://www.lllf.uam.es/ESP/nlpdata/wp2/CT-EBM-SP.zip
- 论文: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A., & Moreno-Sandoval, A. (2021). A clinical trials corpus annotated with UMLS entities to enhance the access to evidence-based medicine. BMC medical informatics and decision making, 21(1), 1-19
- 联系方式: leonardo.campillos AT gmail.com
- 许可证: cc-by-4.0
数据集摘要
该数据集是一个包含1200篇西班牙语临床研究试验文本的语料库,具体包括:
- 500篇来自遵循知识共享许可协议期刊的摘要,例如PubMed或SciELO。
- 700篇来自欧洲临床试验注册库和西班牙临床试验库的临床试验公告。
支持的任务与语言
- 主要任务: 医学命名实体识别
- 语言: 西班牙语
- 多语言性: 单语
数据集结构
数据特征
数据集中每个实例包含以下字段:
tokens: 字符串列表,表示文本的令牌序列。ner_tags: 类别标签列表,使用BIO标注方案,对应以下实体类型:0: B-ANAT (解剖结构)1: I-ANAT2: B-CHEM (化学物质)3: I-CHEM4: B-DISO (病理状况)5: I-DISO6: O (非实体)7: B-PROC (医疗程序)8: I-PROC
text: 字符串,原始文本。
数据规模与划分
- 总令牌数: 292,173
- 总实体数: 46,699
- ANAT (解剖结构): 6,728 个实体
- CHEM (化学物质): 9,224 个实体
- DISO (病理状况): 13,067 个实体
- PROC (医疗程序): 17,680 个实体
数据集划分为三个部分:
- 训练集
- 实例数: 12,554
- 令牌数: 175,203
- 实体数: 28,101
- 文件大小: 4,852,178 字节
- 验证集
- 实例数: 4,549
- 令牌数: 58,670
- 实体数: 9,629
- 文件大小: 1,625,992 字节
- 测试集
- 实例数: 4,505
- 令牌数: 58,300
- 实体数: 8,969
- 文件大小: 1,610,038 字节
- 总数据集大小: 8,088,208 字节
- 下载大小: 2,072,447 字节
数据来源
- 来自遵循知识共享许可协议的期刊摘要,可在PubMed或SciELO获取。
- 来自欧洲临床试验注册库和西班牙临床试验库的临床试验公告。
标注信息
- 标注者:
- Leonardo Campillos-Llanos, 计算语言学家
- Adrián Capllonch-Carrión, 医学博士
- Ana Valverde-Mateos, 医学词典编纂者
- 标注标准: 统一医学语言系统(UMLS)语义组。
使用注意事项
- 该数据集仍在开发中,需要改进。
- 不得在没有人工协助和监督的情况下将其用于医疗决策。
- 该资源旨在用于通用目的,可能存在偏见或其他不良偏差。
- 模型所有者或创建者不对第三方使用此数据集产生的任何结果负责。
引用信息
如果使用本数据集,请引用以下论文:
@article{campillosetal-midm2021, title = {A clinical trials corpus annotated with UMLS© entities to enhance the access to Evidence-Based Medicine}, author = {Campillos-Llanos, Leonardo and Valverde-Mateos, Ana and Capllonch-Carri{o}n, Adri{a}n and Moreno-Sandoval, Antonio}, journal = {BMC Medical Informatics and Decision Making}, volume={21}, number={1}, pages={1--19}, year={2021}, publisher={BioMed Central} }
搜集汇总
数据集介绍
构建方式
在医学信息抽取领域,构建高质量标注数据集是推动自然语言处理技术应用的关键。CT-EBM-SP数据集通过系统化流程构建,其源数据来源于两个主要渠道:一是来自PubMed或SciELO等开放获取平台的500篇临床实验期刊摘要,二是从欧洲临床试验注册库及西班牙临床试验库中提取的700项临床试验公告。这些文本经过专业团队的人工标注,标注者包括计算语言学家、医学博士及医学词典编纂专家,他们依据统一医学语言系统的语义组标准,对解剖结构、化学物质、病理状况及医疗过程四类实体进行了精细标注,确保了标注的一致性与权威性。
特点
该数据集在医学文本处理中展现出显著特点,其标注体系基于统一医学语言系统,涵盖了解剖、化学、疾病与医疗过程四大语义类别,共计标注了超过四万六千个实体。数据集规模适中,包含约29万词元,并按照训练集、验证集与测试集进行了合理划分,为模型训练与评估提供了可靠基础。作为西班牙语临床文本资源,它填补了非英语医学自然语言处理数据的空白,支持命名实体识别等任务,且以开放许可发布,促进了跨语言医学信息提取研究的发展。
使用方法
在医学自然语言处理应用中,CT-EBM-SP数据集主要用于训练和评估命名实体识别模型。研究者可加载数据集的训练、验证与测试分割,利用其标注的实体类别进行模型训练,以提升对西班牙语临床文本中关键医学实体的自动识别能力。使用时应遵循数据集的免责声明,避免将其直接用于医疗决策,而应作为辅助研究工具。通过引用相关学术论文,用户可确保研究的可追溯性与学术规范性,推动证据医学领域的多语言技术进展。
背景与挑战
背景概述
在生物医学信息学领域,西班牙语临床文本的命名实体识别是推动循证医学发展的关键环节。CT-EBM-SP数据集由Campillos-Llanos等人于2021年创建,依托西班牙高等科学研究理事会等机构合作完成。该数据集聚焦于从临床试验摘要与公告中抽取医学实体,涵盖解剖结构、化学物质、病理状态及医疗程序四大语义类别,并采用统一医学语言系统进行标准化标注。其构建旨在弥补西班牙语医学语料资源的匮乏,为自然语言处理模型在临床决策支持系统中的开发提供高质量标注数据,显著提升了跨语言医学信息抽取的研究深度与应用广度。
当前挑战
该数据集致力于解决西班牙语临床文本命名实体识别任务中的多重挑战:医学实体本身具有高度的领域特异性与术语变体复杂性,例如同义词、缩写及嵌套结构的频繁出现,增加了准确边界划分与类型判别的难度。在构建过程中,标注工作面临专业壁垒,需依赖医学专家与语言学家协同完成,以确保术语与UMLS标准的一致性;同时源数据来自异构平台,如PubMed与欧洲临床试验注册库,文本风格与结构的差异对数据清洗与归一化提出了严峻考验。此外,数据规模相对有限及潜在的语言偏差亦制约了模型的泛化能力与临床部署的可靠性。
常用场景
经典使用场景
在医学自然语言处理领域,西班牙语临床文本的实体识别任务长期面临资源匮乏的挑战。CT-EBM-SP数据集通过提供标注精细的临床试验文本,为研究者构建和评估命名实体识别模型奠定了坚实基础。该数据集涵盖解剖结构、化学物质、病理状况及医疗程序等关键实体类别,支持模型从西班牙语临床文献中自动提取结构化医学信息,显著提升了信息抽取的准确性与效率。
解决学术问题
该数据集有效解决了医学信息学中跨语言资源不平衡的学术难题,为西班牙语临床文本的自动化处理提供了标准化标注体系。通过引入UMLS语义组标注,它促进了医学实体归一化与语义关联研究,助力证据医学的知识发现。其构建缓解了非英语医学文本分析工具缺乏的困境,推动了多语言医学自然语言处理技术的发展,为临床决策支持系统的跨语言适配提供了关键数据支撑。
衍生相关工作
围绕CT-EBM-SP数据集,学术界已衍生出一系列经典研究工作。例如,基于该数据集的实体识别模型比较研究,探索了不同神经网络架构在西班牙语临床文本上的性能表现。同时,该数据集常被用作跨语言医学实体识别迁移学习的基准数据,促进了多语言医学语言模型的开发。相关成果进一步推动了西班牙语医学文本挖掘工具的标准化与开源化,形成了持续扩展的医学语言资源生态。
以上内容由遇见数据集搜集并总结生成


