pinzhenchen/alpaca-cleaned-ru
收藏Hugging Face2024-03-06 更新2024-06-22 收录
下载链接:
https://hf-mirror.com/datasets/pinzhenchen/alpaca-cleaned-ru
下载链接
链接失效反馈官方服务:
资源简介:
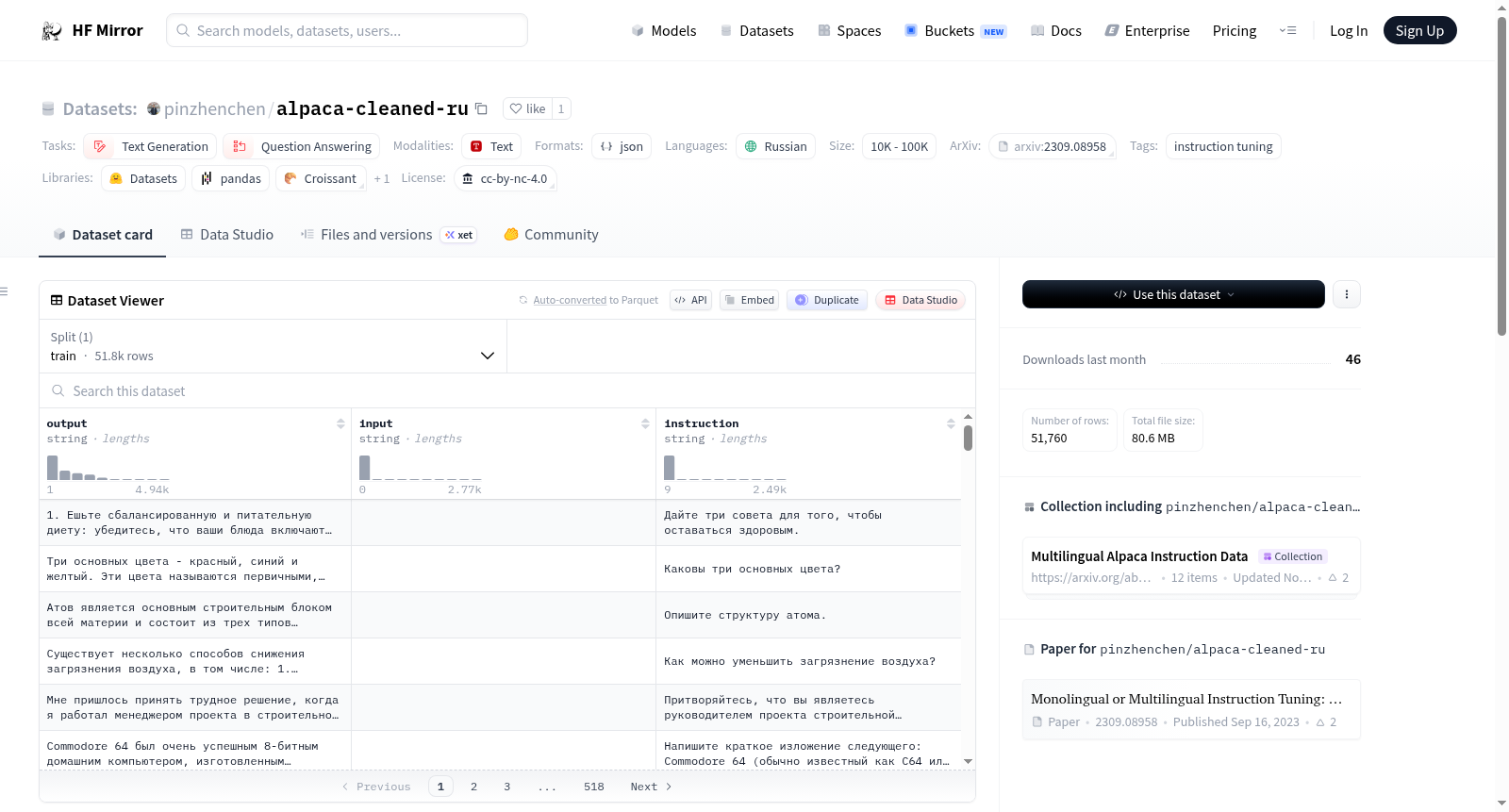
该HF数据仓库包含用于单语与多语指令调优研究的俄语Alpaca数据集。数据集是从yahma/alpaca-cleaned机器翻译成俄语的,主要用于俄语的指令调优,包含约52K个实例,每个实例包含指令、输出和可选的输入。已知问题包括机器翻译过程可能损坏了包含代码、跨语言任务、语法错误纠正任务等的数据。
该HF数据仓库包含用于单语与多语指令调优研究的俄语Alpaca数据集。数据集是从yahma/alpaca-cleaned机器翻译成俄语的,主要用于俄语的指令调优,包含约52K个实例,每个实例包含指令、输出和可选的输入。已知问题包括机器翻译过程可能损坏了包含代码、跨语言任务、语法错误纠正任务等的数据。
提供机构:
pinzhenchen
原始信息汇总
数据集描述
该数据集是用于研究单语与多语指令调优的俄罗斯Alpaca数据集。
创建
- 该数据集是通过机器翻译从yahma/alpaca-cleaned翻译成俄语的。
使用
- 该数据集旨在用于俄语指令调优。
- 数据集包含约52K个实例,格式为JSON。
- 每个实例包含一个指令、一个输出和一个可选的输入。示例如下: json { "instruction": "Каковы три основных цвета?", "input": "", "output": "Три основных цвета - красный, синий и желтый. Эти цвета называются первичными, потому что они не могут быть созданы путем смешивания других цветов, и все другие цвета могут быть сделаны путем объединения их в различных пропорциях. В присадочной цветовой системе, используемой для освещения, первичные цвета - красные, зеленые и синие (RGB)." }
已知问题
- 机器翻译过程可能损坏包含代码、跨语言任务、语法错误纠正任务等的数据。
引用
@inproceedings{chen-etal-2024-monolingual, title="Monolingual or multilingual instruction tuning: Which makes a better {Alpaca}", author="Pinzhen Chen and Shaoxiong Ji and Nikolay Bogoychev and Andrey Kutuzov and Barry Haddow and Kenneth Heafield", year="2024", booktitle = "Findings of the Association for Computational Linguistics: EACL 2024", }
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,高质量的指令调优数据集对于提升模型性能至关重要。该数据集通过机器翻译技术,从英文原版Alpaca-cleaned数据集转化而来,专门针对俄语指令调优任务构建。构建过程中,原始数据中的每条指令、输入及输出内容均被系统性地翻译为俄语,形成了约5.2万条结构化实例,为俄语自然语言生成与问答研究提供了重要资源。
特点
作为俄语指令调优领域的专项数据集,其核心特点在于语言纯正性与任务针对性。数据集严格遵循指令-输入-输出的三元组格式,每条实例均以俄语呈现,确保了语言的一致性。然而,机器翻译过程可能对包含代码、跨语言任务或语法纠错等内容造成一定影响,这在使用时需予以留意。该数据集为探究单语与多语指令调优的对比研究提供了关键数据支撑。
使用方法
该数据集主要应用于俄语指令调优任务,以推动俄语大语言模型的发展。研究人员可直接加载其JSON格式数据,每条数据包含指令、可选输入及预期输出三个字段。通过将这些结构化实例用于模型训练,能够有效提升模型对俄语指令的理解与生成能力。使用前建议仔细审查数据,特别是涉及代码或特殊任务的内容,以确保训练质量。
背景与挑战
背景概述
随着大规模语言模型在自然语言处理领域的广泛应用,指令微调技术成为提升模型遵循人类指令能力的关键途径。由Pinzhen Chen等人于2024年创建的pinzhenchen/alpaca-cleaned-ru数据集,源于对单语与多语指令微调效果的比较研究,其核心研究问题聚焦于探索俄语指令数据对模型性能的优化作用。该数据集基于yahma/alpaca-cleaned通过机器翻译构建,包含约5.2万条俄语指令-输出对,旨在为俄语自然语言生成任务提供高质量微调资源,推动了跨语言指令跟随模型的发展,对俄语人工智能应用具有显著影响力。
当前挑战
该数据集致力于解决俄语指令跟随任务中的挑战,即如何使语言模型准确理解并执行多样化的俄语人类指令,这涉及对复杂语义和语境的处理。在构建过程中,机器翻译方法引入了数据质量隐患,例如代码片段、跨语言任务及语法纠错等内容可能在翻译过程中受损,导致数据噪声或语义失真,从而影响微调效果。此外,确保翻译后指令的流畅性与任务一致性,也是构建高质量俄语指令数据集的核心难点。
常用场景
经典使用场景
在自然语言处理领域,指令微调已成为提升模型遵循人类指令能力的关键技术。pinzhenchen/alpaca-cleaned-ru数据集作为俄语指令微调资源,其经典使用场景集中于训练俄语大语言模型,使模型能够理解和执行以俄语表述的多样化任务指令,涵盖问答、文本生成等核心功能。通过该数据集,研究者能够构建针对俄语环境的智能对话系统,有效促进模型在俄语语境下的泛化与适应性能。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作,特别是其在单语与多语指令微调比较实验中的核心作用。相关论文《Monolingual or multilingual instruction tuning: Which makes a better Alpaca》系统评估了不同语言策略对模型性能的影响,为后续跨语言指令优化提供了实证基础。这些工作不仅推动了Alpaca模型系列的演进,还激励了更多针对特定语言的指令数据集构建与微调方法创新。
数据集最近研究
最新研究方向
在自然语言处理领域,多语言指令调优已成为推动模型泛化能力的关键前沿。pinzhenchen/alpaca-cleaned-ru数据集作为俄语指令调优资源,其研究聚焦于比较单语与多语指令调优策略对模型性能的影响。近期热点围绕低资源语言的高效适配展开,该数据集通过机器翻译生成,为探索跨语言知识迁移提供了实验基础,尤其在提升模型对俄语复杂语法结构的理解方面具有显著意义。相关研究揭示了单语调优在特定语言任务上的潜在优势,促进了多语言模型优化方法的创新,对推动全球化AI应用部署产生了积极影响。
以上内容由遇见数据集搜集并总结生成


