oxford-iiit-pet
收藏Hugging Face2024-11-03 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/StarQuestLab/oxford-iiit-pet
下载链接
链接失效反馈官方服务:
资源简介:
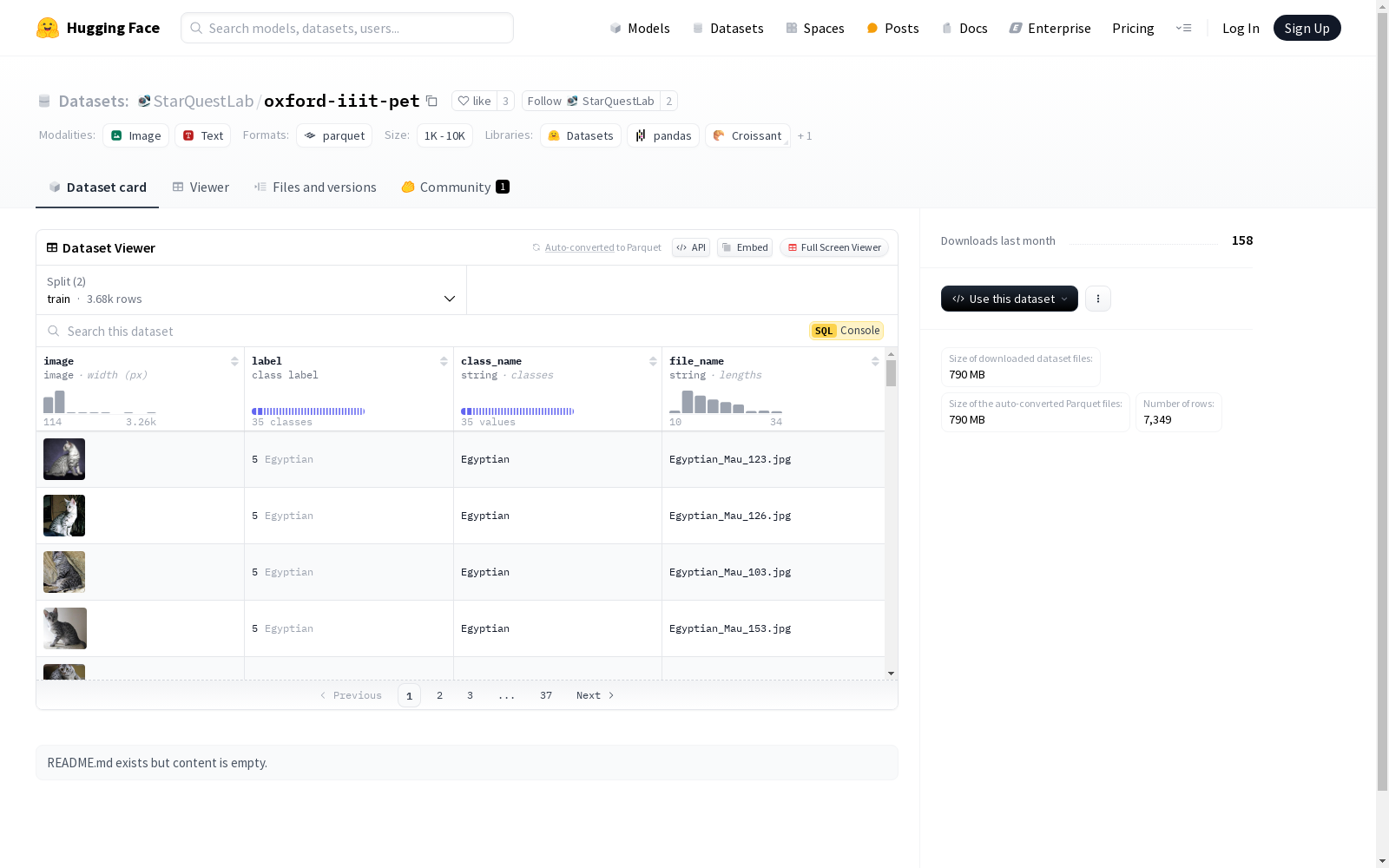
该数据集包含3680个训练样本和3669个验证样本,每个样本包含一张图像、一个分类标签、一个类别名称和一个文件名。标签涵盖35个不同的猫和狗品种,如Abyssinian、Bengal、Basset等。
This dataset contains 3,680 training samples and 3,669 validation samples. Each sample includes an image, a classification label, a class name, and a filename. The labels cover 35 distinct cat and dog breeds, such as Abyssinian, Bengal, Basset, etc.
创建时间:
2024-11-03
原始信息汇总
数据集概述
数据集信息
- 特征:
- image: 图像数据
- label: 类别标签
- class_label:
- names:
- 0: Abyssinian
- 1: Bengal
- 2: Birman
- 3: Bombay
- 4: British
- 5: Egyptian
- 6: Maine
- 7: Persian
- 8: Ragdoll
- 9: Russian
- 10: Siamese
- 11: Sphynx
- 12: american
- 13: basset
- 14: beagle
- 15: boxer
- 16: chihuahua
- 17: english
- 18: german
- 19: great
- 20: havanese
- 21: japanese
- 22: keeshond
- 23: leonberger
- 24: miniature
- 25: newfoundland
- 26: pomeranian
- 27: pug
- 28: saint
- 29: samoyed
- 30: scottish
- 31: shiba
- 32: staffordshire
- 33: wheaten
- 34: yorkshire
- names:
- class_label:
- class_name: 类别名称
- file_name: 文件名
数据集划分
- train:
- num_bytes: 351239006.08
- num_examples: 3680
- validation:
- num_bytes: 355644522.935
- num_examples: 3669
数据集大小
- download_size: 790121062
- dataset_size: 706883529.015
配置
- config_name: default
- data_files:
- train: data/train-*
- validation: data/validation-*
- data_files:
搜集汇总
数据集介绍
构建方式
oxford-iiit-pet数据集的构建基于对宠物图像的系统性收集与标注。该数据集包含了多种猫和狗的品种,每张图像均经过精确的品种分类和命名。数据集的构建过程注重多样性和代表性,涵盖了37个不同的品种,确保了数据的广泛适用性和研究价值。通过严格的标注流程,每张图像均附有品种标签和文件名,便于后续的机器学习任务。
特点
oxford-iiit-pet数据集以其丰富的品种多样性和高质量的图像标注而著称。数据集包含37个猫和狗的品种,每个品种均有大量样本,确保了数据的均衡性和代表性。图像的分辨率高,细节丰富,适合用于深度学习模型的训练与验证。此外,数据集提供了详细的品种名称和类别标签,便于研究人员进行精确的分类任务。
使用方法
oxford-iiit-pet数据集广泛应用于图像分类和品种识别的研究中。研究人员可以通过加载数据集中的图像和标签,构建和训练深度学习模型。数据集分为训练集和验证集,便于模型的训练与评估。使用该数据集时,建议先进行数据预处理,如图像归一化和增强,以提高模型的性能。通过该数据集,研究人员可以探索不同品种的特征,提升分类算法的准确性和鲁棒性。
背景与挑战
背景概述
Oxford-IIIT Pet数据集由牛津大学视觉几何组(Visual Geometry Group)与印度理工学院(Indian Institute of Technology)合作创建,旨在为计算机视觉领域提供高质量的宠物图像分类基准。该数据集发布于2012年,涵盖了37个不同类别的猫和狗,共计7349张图像。每张图像均标注了详细的类别信息,包括品种名称和图像文件名。该数据集的推出为图像分类、目标检测和细粒度识别等任务提供了重要的实验平台,推动了相关算法的研究与优化。
当前挑战
Oxford-IIIT Pet数据集在解决细粒度图像分类问题时面临诸多挑战。首先,不同品种的猫和狗在外观上具有高度相似性,尤其是同一物种的不同品种,这增加了分类模型的难度。其次,数据集中部分类别的样本数量较少,可能导致模型在训练过程中出现过拟合现象。此外,构建该数据集时,研究人员需确保图像的质量和标注的准确性,这对数据采集和标注工作提出了较高的要求。这些挑战促使研究者开发更加鲁棒和高效的算法,以应对细粒度分类任务中的复杂性问题。
常用场景
经典使用场景
Oxford-IIIT Pet数据集广泛应用于计算机视觉领域,特别是在图像分类和对象识别任务中。该数据集包含了37个不同品种的猫和狗的高质量图像,为研究人员提供了一个标准化的基准,用于评估和比较各种图像分类算法的性能。通过该数据集,研究者能够深入探索深度学习模型在复杂图像识别任务中的表现。
衍生相关工作
基于Oxford-IIIT Pet数据集,许多经典的研究工作得以展开。例如,研究者开发了多种深度学习模型,如卷积神经网络(CNN)和迁移学习模型,以提升图像分类的准确率。此外,该数据集还催生了一系列关于数据增强和模型优化的研究,进一步推动了计算机视觉领域的发展。
数据集最近研究
最新研究方向
在计算机视觉领域,oxford-iiit-pet数据集作为宠物图像分类的基准数据集,近年来在深度学习模型的训练与评估中发挥了重要作用。随着卷积神经网络(CNN)和Transformer架构的不断演进,研究者们致力于提升模型在复杂背景下的宠物识别精度。特别是在细粒度分类任务中,如何有效区分外观相似的宠物品种成为研究热点。近期,基于自监督学习和对比学习的方法在该数据集上取得了显著进展,这些方法通过利用未标注数据增强模型泛化能力,减少了对大规模标注数据的依赖。此外,多模态学习结合图像与文本信息,进一步提升了分类性能。oxford-iiit-pet数据集的应用不仅推动了宠物识别技术的发展,也为医疗影像、自动驾驶等领域的细粒度分类问题提供了重要参考。
以上内容由遇见数据集搜集并总结生成


