anhaltai/bvl-qa-corpus-2024
收藏Hugging Face2024-06-25 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/anhaltai/bvl-qa-corpus-2024
下载链接
链接失效反馈官方服务:
资源简介:
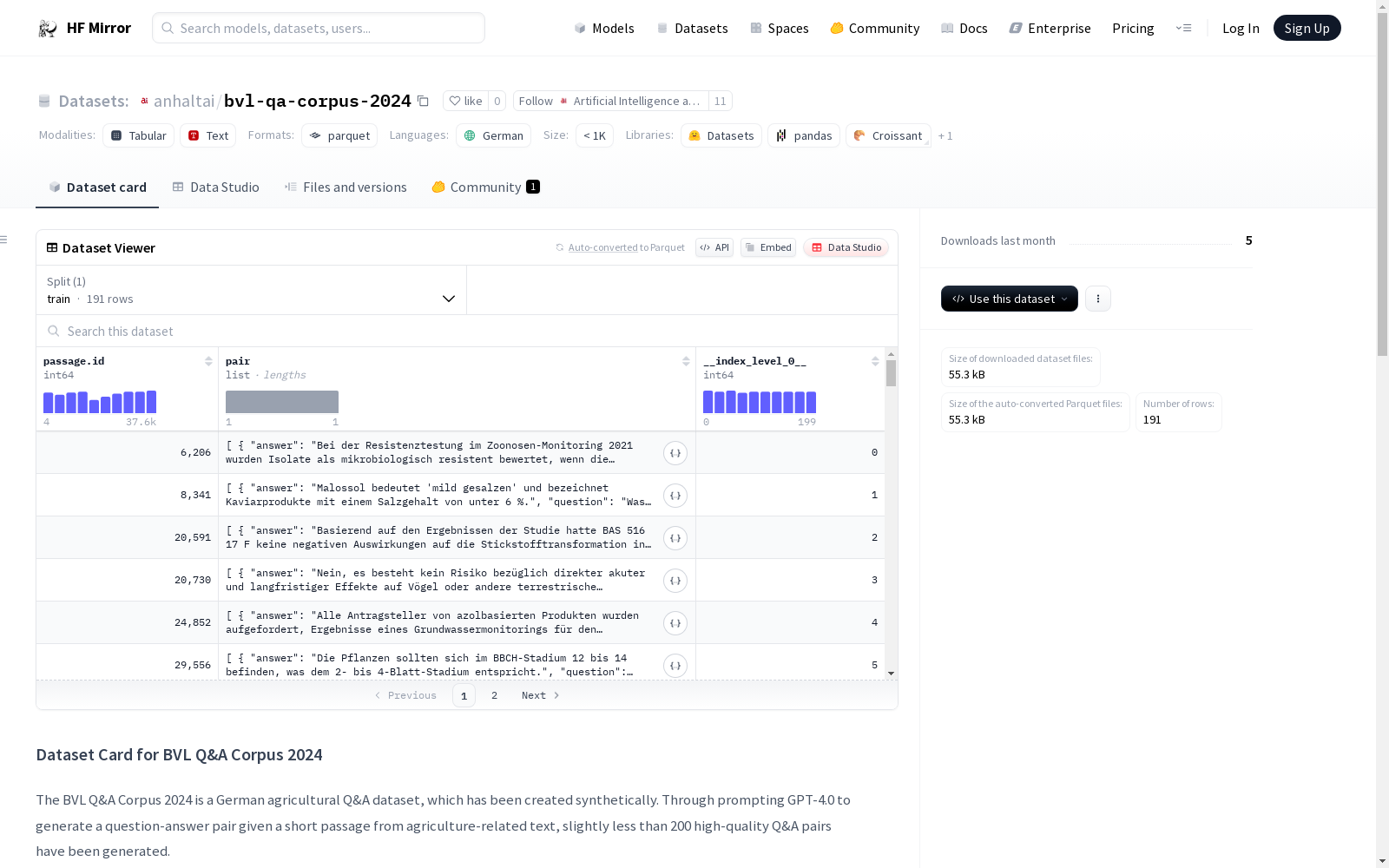
BVL Q&A Corpus 2024是一个德语农业问答数据集,通过GPT-4.0生成问题和答案对,基于从德国联邦消费者保护和食品安全局(BVL)主页抓取的文本。数据集包含约200个高质量的问答对,涵盖了食品/饲料分析、植物保护、兽医学和基因工程等主题。数据集由AnhaltAI策划,主要用于非商业研究和教育用途。数据集结构包括三个字段:问题、答案和段落ID。数据来源是从BVL的PDF文件中随机选取的超过41,000个段落。
BVL Q&A Corpus 2024是一个德语农业问答数据集,通过GPT-4.0生成问题和答案对,基于从德国联邦消费者保护和食品安全局(BVL)主页抓取的文本。数据集包含约200个高质量的问答对,涵盖了食品/饲料分析、植物保护、兽医学和基因工程等主题。数据集由AnhaltAI策划,主要用于非商业研究和教育用途。数据集结构包括三个字段:问题、答案和段落ID。数据来源是从BVL的PDF文件中随机选取的超过41,000个段落。
提供机构:
anhaltai
原始信息汇总
BVL Q&A Corpus 2024 数据集概述
数据集描述
- 名称: BVL Q&A Corpus 2024
- 语言: 德语
- 大小: 少于1K条
- 创建方式: 通过GPT-4.0生成,基于农业相关文本的短文生成问题-答案对
- 条目数量: 约200条高质量问答对
- 来源: 德国联邦消费者保护和食品安全办公室(BVL)的网页抓取数据
- 主题范围: 食品/饲料分析、植物保护、兽医医学、基因工程等
- 创建者: AnhaltAI
- 许可: 非商业用途
数据集结构
- 字段:
question: 问题answer: 答案passage.id: 短文ID
数据集创建
- 源数据:
- 数据来源: 从BVL的约5000个PDF文件中随机选择的41k条短文
- 数据处理: 未提供详细信息
- 个人信息:
- 数据可能包含公开的地址、唯一可识别的名称或别名,未进行匿名化处理
使用说明
- 用途: 自由用于非商业研究或教育
- 许可限制: 请参考BVL imprint了解允许的使用方式
引用
- BibTeX: 即将提供
搜集汇总
数据集介绍
构建方式
BVL Q&A Corpus 2024数据集的构建,源于对德国联邦消费者保护和食品安全局(BVL)官网的网页抓取,时间定位于2024年3月。该数据集的创建采用了提示GPT-4.0模型,根据农业相关文本的短段落生成问答对,从而合成了略少于200对高质量的问题与答案。
特点
本数据集以德语为语言,专注于农业领域的问答,涵盖了从食品/饲料分析、植物保护、兽医到基因工程等多个主题。其特点在于数据的合成性,即通过先进模型生成,保证了问答对的质量和相关性。同时,数据集遵循非商业使用许可,适用于学术研究或教育领域。
使用方法
使用BVL Q&A Corpus 2024数据集时,用户可以自由地将其应用于非商业性质的研究或教育活动。数据集的结构包括三个字段:问题、答案以及与之对应的段落ID,这为研究提供了便捷的数据访问和引用方式。用户在使用时,应遵守BVL的版权声明,确保合法合规。
背景与挑战
背景概述
BVL Q&A Corpus 2024数据集,是在安哈尔特大学的一个本科毕业项目中创建的德语农业问答数据集。该数据集通过从德国联邦消费者保护和食品安全局(BVL)网站抓取的文本中,利用GPT-4.0生成约200对高质量的问答对。数据源涵盖食品/饲料分析、植物保护、兽医医学到基因工程等多个主题,旨在为自然语言处理领域的研究提供支持,尤其是针对德语问答系统的开发与优化。
当前挑战
该数据集在构建过程中遇到的挑战主要包括:首先,如何确保从BVL网站抓取的文本质量和相关性;其次,利用GPT-4.0生成问答对时,如何保证生成的问答对在内容上的准确性和多样性;最后,数据集中可能包含的公开敏感信息如何处理,以及如何在使用数据集时遵循非商业使用的许可协议。此外,在所解决的领域问题方面,如何有效地将此数据集应用于提升德语农业问答系统的性能,以及如何评估和量化所取得的进展,也是当前面临的挑战。
常用场景
经典使用场景
在自然语言处理领域,尤其是德语问答系统的研究中,BVL Q&A Corpus 2024数据集以其高质量的问答对,成为训练和评估模型的经典资源。该数据集通过模拟生成,为研究者提供了近200对关于农业领域的问题与答案,从而使得模型能够在特定的专业领域内进行有效的信息检索和问题解答。
衍生相关工作
基于BVL Q&A Corpus 2024数据集,研究者们已经开展了一系列相关工作,包括但不限于构建更为复杂的问答模型、探索领域自适应的方法,以及将该数据集应用于跨领域的语言模型评估等,这些都进一步扩展了数据集的应用范围和影响力。
数据集最近研究
最新研究方向
BVL Q&A Corpus 2024数据集,作为一项针对德国农业领域的问题与回答的合成数据集,其最新研究方向聚焦于通过GPT-4.0生成的近200对高质量问答对。该数据集的构建,旨在服务于自然语言处理领域,特别是在德语问答系统的开发与优化上。其研究不仅涉及食品安全、植物保护、兽医医学等领域,亦拓展至转基因工程等前沿话题。该数据集的问世,对于推动智能问答系统在农业信息获取与处理中的应用,具有显著影响和重要意义,为相关领域的研究提供了新的资源与视角。
以上内容由遇见数据集搜集并总结生成


