MultiTalkPT
收藏Hugging Face2026-05-06 更新2026-05-07 收录
下载链接:
https://huggingface.co/datasets/MultiTalk/MultiTalkPT
下载链接
链接失效反馈官方服务:
资源简介:
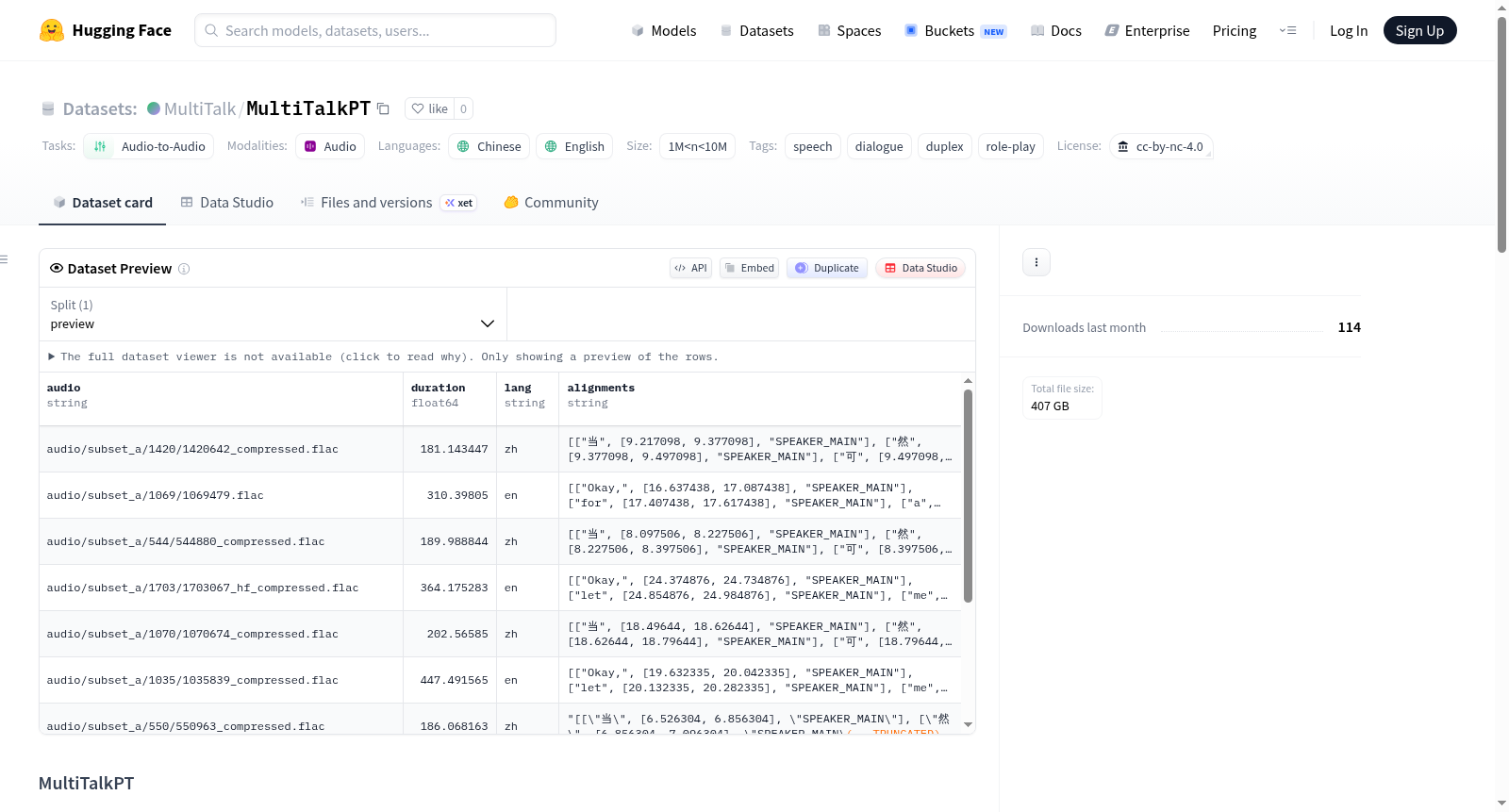
MultiTalkPT是一个用于全双工口语对话模型预训练的语料库,支持中文和英文两种语言。该数据集属于音频到音频任务类别,专注于语音、对话、双工通信和角色扮演场景。数据集规模在100万到1000万条记录之间。主要包含两种数据文件:1) data_{zh,en}.jsonl文件,每条记录包含对话音频的相对路径、说话人提示音频路径、对话时长(秒)和系统/角色提示信息;2) transcripts目录下的parquet文件,提供词级转录信息,包括音频路径匹配ID、片段时长、原始对话说话人数量、说话人-声道映射、说话人声音路径、词对齐信息(包含词、时间区间和说话人标签)以及训练相关信息(系统提示和声音提示等)。数据集适用于语音对话系统开发、角色扮演对话模型训练等自然语言处理和语音处理任务。
MultiTalkPT is a corpus for full-duplex spoken dialogue model pre-training, supporting both Chinese and English languages. The dataset belongs to the audio-to-audio task category, focusing on speech, dialogue, duplex communication, and role-playing scenarios. The dataset size ranges between 1 million to 10 million records. It mainly contains two types of data files: 1) data_{zh,en}.jsonl files, each record containing the relative path of the dialogue audio, speaker prompt audio path, dialogue duration (in seconds), and system/role prompt information; 2) parquet files under the transcripts directory, providing word-level transcription information, including audio path matching ID, segment duration, original dialogue speaker count, speaker-channel mapping, speaker voice path, word alignment information (including words, time intervals, and speaker labels), and training-related information (system prompts and voice prompts, etc.). The dataset is suitable for speech dialogue system development, role-playing dialogue model training, and other natural language processing and speech processing tasks.
创建时间:
2026-05-05
原始信息汇总
根据您提供的数据集详情页面信息,以下是关于 MultiTalkPT 数据集的总结:
数据集概述
MultiTalkPT 是一个用于全双工口语对话模型的预训练语料库,支持中文和英文两种语言。
数据集规模
- 样本数量:1M < n < 10M(百万级)
- 许可证:CC-BY-NC-4.0(知识共享-非商业性使用 4.0 国际)
任务与标签
- 任务类型:音频到音频(audio-to-audio)
- 标签:语音(speech)、对话(dialogue)、双工(duplex)、角色扮演(role-play)
数据文件与结构
1. 对话清单文件(data_zh.jsonl / data_en.jsonl)
每行一个 JSON 记录,包含以下字段:
| 字段名 | 类型 | 描述 |
|---|---|---|
path |
string | 对话音频的相对路径 |
voice |
string | 说话人提示音频的相对路径 |
duration |
float | 对话时长(秒) |
system |
string | 角色设定或系统提示 |
2. 转写文件(transcripts/*.parquet)
Parquet 格式,包含以下列:
| 列名 | 类型 | 描述 |
|---|---|---|
audio_path |
string | 与 data_*.jsonl 中的 path 对应 |
id |
string | 片段 ID |
duration |
float | 对话时长 |
num_channels |
int32 | 原始对话中的说话人数量 |
speaker_to_channel |
string | JSON 格式的 {说话人: 通道索引} 映射 |
voice |
string | JSON 格式的 {说话人: 相对语音路径} |
alignments |
string | JSON 格式的扁平列表 [[单词, [开始时间, 结束时间], 说话人标签], …] |
training |
string | JSON 格式的 {system_prompt, voice_prompt (相对路径), …} |
预览数据
数据集提供 100 行的预览样本,可通过 preview 配置加载。预览数据包含音频路径、时长、语言和对齐信息。
快速加载方式
支持通过 datasets 库直接加载,或使用 huggingface_hub 下载原始 JSONL 和 Parquet 文件。
搜集汇总
数据集介绍
构建方式
MultiTalkPT数据集专为全双工语音对话模型的预训练而构建,涵盖中文与英文两种语言。其核心架构由两部分组成:数据清单文件(data_zh.jsonl与data_en.jsonl)和转录注释文件(transcripts/*.parquet)。数据清单以JSONL格式逐行记录每条对话音频的路径、说话人提示音频路径、对话时长及系统角色设定。转录注释则采用分片Parquet格式存储,包含音频路径、片段标识、通道数、说话人与通道的映射关系、说话人语音路径、词级对齐信息(含词语、起止时间及说话人标签),以及训练所需的系统提示与语音提示配置。通过这种分层设计,数据集将原始音频、元数据与细粒度注释有机结合,为模型提供结构化、多模态的预训练信号。
特点
该数据集的核心特点在于其全双工对话建模支持与丰富的角色扮演设计。每个对话片段均保留原始的多通道音频,真实反映多人同时发言的交互场景,区别于传统的单通道或交替式对话数据。数据集中包含明确的说话人与通道索引对应关系,以及每个说话人的独立语音提示片段,便于模型学习特定音色与风格的一致性表达。此外,每条数据均附带系统级的角色提示(persona/system prompt),为上下文驱动的角色扮演任务提供了天然的训练素材。预置的词级时间对齐注释进一步支撑了语音与文本的联合建模,使得模型在生成过程中能够精准控制语义内容与韵律节奏的同步。
使用方法
使用者可通过HuggingFace Datasets库加载数据集预览样本,或直接下载完整的JSONL清单与Parquet转录文件以进行灵活的数据迭代。加载预览时,调用load_dataset并指定'preview'配置即可获取包含路径与对齐信息的文本字段。若要处理完整数据,推荐使用hf_hub_download获取数据清单文件,再通过逐行解析JSONL实现音频路径与元数据的访问。对于细粒度的词级注释,可利用Parquet分片文件的流式加载(streaming=True)高效索引大规模数据,结合soundfile库读取对应音频片段。开发者可依据对齐字段中的说话人标签与时间戳,为每个角色提取独立的语音流,配合语音提示合成全双工对话序列,用于训练端到端的语音对话模型。
背景与挑战
背景概述
随着全双工口语对话系统的兴起,传统基于文本或单声道语音的训练数据已难以满足模型对自然交互韵律、重叠语音及多说话人动态管理的学习需求。MultiTalkPT数据集由MultiTalk团队于近期发布,旨在构建一个大规模、高质量的全双工对话预训练语料库,其核心研究问题在于如何通过结构化多通道音频与精细化的对齐标注,使模型能够同时感知说话人角色、语音重叠时段及交互时序。该数据集包含中英双语、超过百万条对话片段,并提供了说话人提示音、系统角色提示及词级对齐时间戳,为语音对话模型从感知到生成的统一预训练奠定了坚实基础,对语音交互领域的发展具有重要推动作用。
当前挑战
MultiTalkPT所解决的领域问题在于,现有语音数据集多采用交替式单声道录制,无法反映真实对话中的同时说话、打断与回音等全双工特性,导致模型在应对重叠语音与动态角色切换时表现欠佳。在构建过程中,团队需克服多源语音采集的一致性难题,确保不同录音环境下的音质与音量平衡;同时,从原始多通道音频中精准提取说话人角色映射、词级对齐时间戳及重叠语音区间,对语音活动检测与声纹识别技术提出了极高要求。此外,如何设计兼顾中英双语特点的标注规范,并保证百万级数据规模下标注的准确性与一致性,也是构建该数据集面临的重大挑战。
常用场景
经典使用场景
MultiTalkPT作为全双工口语对话模型的预训练语料库,其核心使用场景聚焦于构建能够实现自然轮流说话、实时打断与恢复的多模态对话系统。借助其中文和英文双语言大规模对话音频数据,研究者可训练模型在嘈杂环境下精准捕捉说话人身份、语轮切换点及情感韵律变化,从而模拟人类日常交流中同时听与说的动态交互模式。该数据集尤其适用于开发具备角色扮演能力的虚拟助手、智能客服及社交机器人,其设计精良的说话人标注与对齐信息为端到端语音对话模型提供了高质量监督信号。
衍生相关工作
MultiTalkPT衍生了一系列具有影响力的研究工作,例如基于其对齐标注的全双工对话预训练框架FullDuplexBERT,以及利用说话人声道映射实现的动态语轮预测模型DialTurnGPT。在语音生成领域,研究者构建了面向角色扮演的多说话人语音合成系统RoleVoice,显著提升了合成语音的交互自然度。此外,该数据集催生了关于重叠语音检测与优化的专项挑战任务,并推动了开源工具包FullDuplexKit的诞生,为学术界提供了一个完整的全双工对话模型训练与评估平台,促进了该方向的持续创新与发展。
数据集最近研究
最新研究方向
全双工口语对话模型的预训练语料构建是当前语音交互领域的前沿方向。MultiTalkPT作为首个大规模中英双语全双工对话预训练数据集,其发布恰逢大语言模型向多模态、实时交互演进的关键时期。该数据集通过精细化的角色标注、音轨分离与逐词时间对齐技术,为模型学习同时听与说的全双工能力提供了标准化训练基准。这一突破性资源将推动语音助手从单轮问答模式向类人自然对话范式跃迁,尤其在智能客服、虚拟角色扮演等场景具有深远应用价值。该数据集的开源填补了全双工对话预训练语料的空白,引领语音AI向更自然、低延迟的交互形态演进。
以上内容由遇见数据集搜集并总结生成


