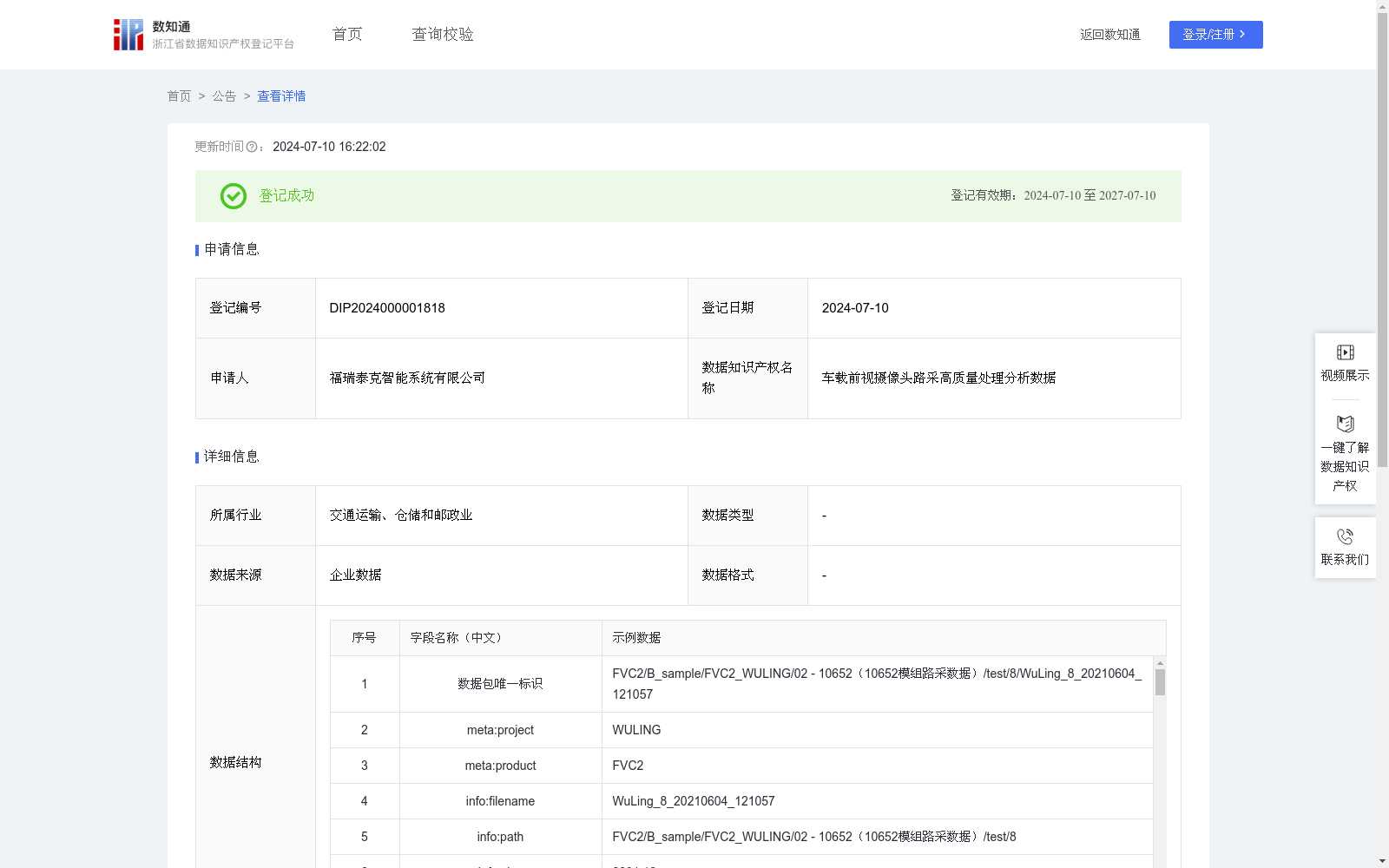
车载前视摄像头路采高质量处理分析数据
收藏浙江省数据知识产权登记平台2024-07-10 更新2024-07-11 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/37414
下载链接
链接失效反馈官方服务:
资源简介:
本数据适用于对智能辅助驾驶中车载前视摄像头路采图像数据进行清洗,打标签,帮助辅助驾驶算法模型更准确地学习和理解不同场景、对象和情境,以提高算法模型的准确性,同时在面对新的、未见过的情况时也能做出准确的预测和决策。并且清洗和打标后的数据对智能辅助驾驶开发者进行后端算法模型验证、训练、迭代提升有着指导性的作用。通过前视摄像头采集路面图像,在清洗和打标之前对图像进行预处理包括去噪、增强对比度等,使用目标检测算法来识别图像中的不同对象或目标;对图像进行分割,将图像中不同区域或对象标记和区分;识别出图像中目标或区域并标注,例如:从车底盘信号中获取每一时刻的速度、加速度、角速度信息后,通过平均、求方差等方式获得对应指标,同时结合时间长度计算其在一定速度范围内的占比;从底盘信号中获取来自于前视摄像头中各功能的触发信号,以判断是否存在功能触发以及对应的时间,基于深度学习的感知结果获取该连续帧片段感知检测的目标结果以及其ID。通过连续帧针对不同时刻的目标与自车的相对位置关系、相对朝向角关系和运动变化趋势等判断是否有车辆从邻道切入(cut-in)或者从前方切出到其他车道(cut-out),并通过深度学习感知结果判断其目标类型,通过其运动轨迹判断其来源方向以及其切入切出时的距离;基于深度学习感知算法结果统计每一时刻监测到的目标障碍物数量,统计无目标的时长占比;基于深度学习场景识别模型从图像中推理出当前场景属于白天/黑夜以及天气、道路状况;在进行标注后需要对数据进行清洗包括去除错误标注、噪声数据或者不准确的标记
This dataset is intended for cleaning and annotating road-collected image data from the in-vehicle forward-looking camera in intelligent advanced driver-assistance systems (ADAS). It helps ADAS algorithm models learn and comprehend diverse scenarios, objects and contexts more accurately, thereby enhancing the model’s accuracy and enabling it to make precise predictions and decisions even when facing novel, unseen situations. Moreover, the cleaned and annotated data offers guidance for ADAS developers to verify, train and iteratively optimize their backend algorithm models. Road images are collected via the forward-looking camera. Preprocessing steps prior to cleaning and annotation include denoising, contrast enhancement and other operations. Object detection algorithms are utilized to identify various objects or targets in the images; image segmentation is performed to mark and differentiate different regions or objects within the images. Targets or regions in the images are then identified and annotated. For example: After acquiring real-time speed, acceleration and angular velocity information from the vehicle chassis signals, corresponding metrics are derived via methods such as averaging and variance calculation, and the proportion of time within a specific speed range is calculated combined with the signal duration. Trigger signals of various functions from the forward-looking camera are extracted from the chassis signals to determine whether a function trigger has occurred and its corresponding timestamp. The detection results and IDs of targets in the consecutive frame segment are obtained based on deep learning-based perception outputs. By analyzing the relative position, relative heading angle and motion trend of targets relative to the ego vehicle at different moments using consecutive frames, we can determine whether a vehicle cuts in from an adjacent lane or cuts out from the current lane into other lanes. The target type is judged via deep learning perception results, and its source direction and the distance at the moment of cut-in/cut-out are inferred from its motion trajectory. The number of detected obstacle targets at each moment is counted based on the outputs of deep learning perception algorithms, and the proportion of time with no targets detected is also calculated. The deep learning-based scene recognition model is used to infer whether the current scenario is daytime or nighttime, as well as the weather and road conditions from the images. After annotation, data cleaning is required, which includes removing incorrectly annotated samples, noisy data or inaccurate labels.
提供机构:
福瑞泰克智能系统有限公司
创建时间:
2024-06-19
搜集汇总
数据集介绍
特点
该数据集为车载前视摄像头采集的路面图像数据,适用于智能辅助驾驶算法的开发,包含52478条数据,更新频次为按需更新。数据经过预处理、目标检测、图像分割和标注等步骤,旨在提高算法模型的准确性和预测能力。
以上内容由遇见数据集搜集并总结生成


