RPL_Q3-0.6B_U10_beta0.10rho0.00K4_sf1.00
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://huggingface.co/datasets/xudongwu/RPL_Q3-0.6B_U10_beta0.10rho0.00K4_sf1.00
下载链接
链接失效反馈官方服务:
资源简介:
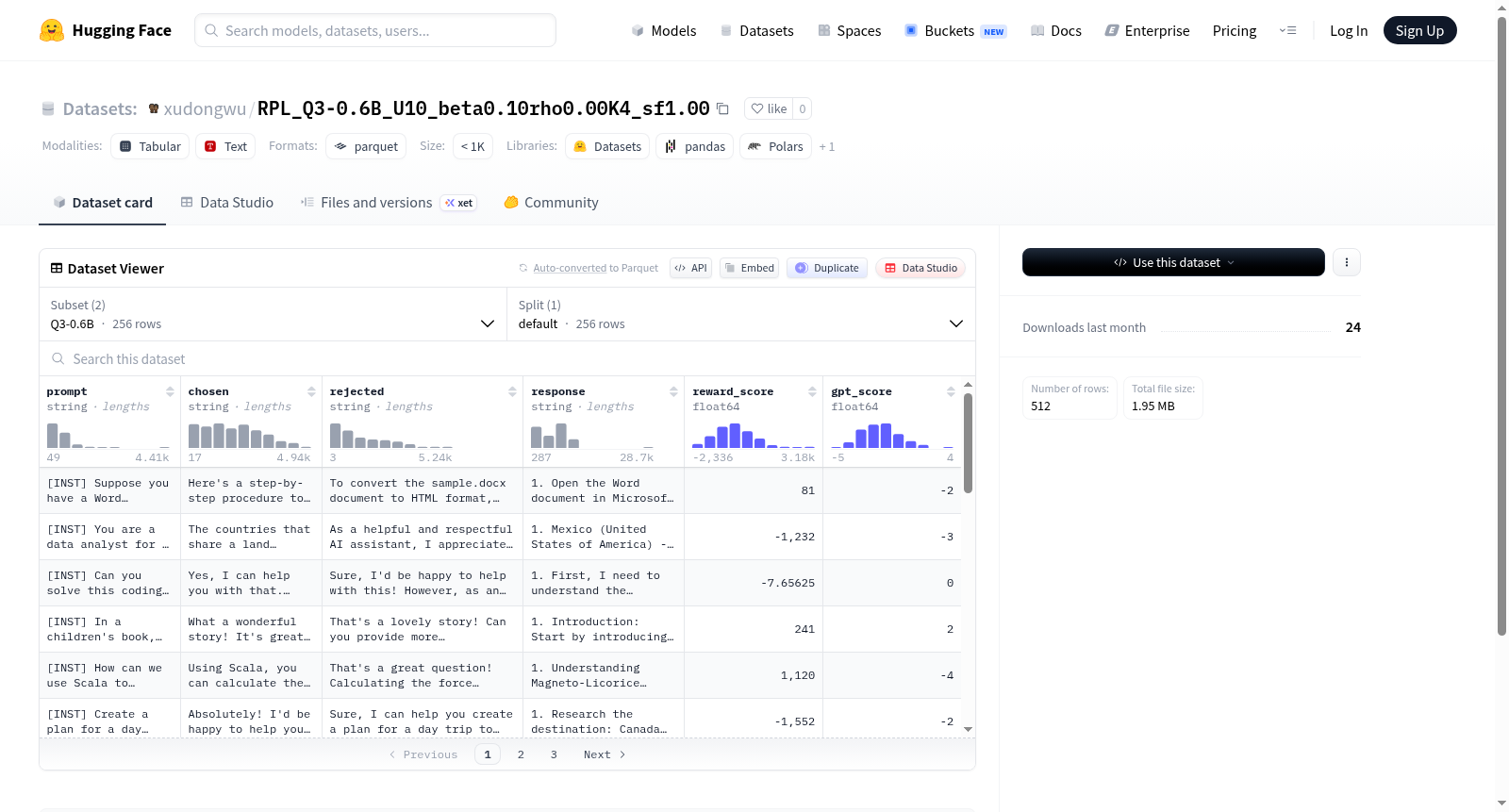
该数据集包含两种配置(Q3-0.6B和Q3-0.6B-s600),主要用于偏好学习或强化学习任务。每个配置包含256个样本,数据字段包括:提示文本(prompt)、优选回答(chosen)、劣选回答(rejected)、模型响应(response)、奖励分数(reward_score),其中Q3-0.6B额外包含GPT评分(gpt_score)。数据以字符串和浮点数格式存储,Q3-0.6B总大小2.38MB,Q3-0.6B-s600总大小2.24MB。适用于对话模型训练、响应质量评估等场景。
创建时间:
2026-05-01
原始信息汇总
根据您提供的数据集详情页面信息,以下是对该数据集的总结:
数据集概述
- 名称:RPL_Q3-0.6B_U10_beta0.10rho0.00K4_sf1.00
- 来源:Hugging Face Datasets
- 链接:https://huggingface.co/datasets/xudongwu/RPL_Q3-0.6B_U10_beta0.10rho0.00K4_sf1.00
数据集配置与结构
该数据集包含两个配置(config_name),每个配置均为单拆分(split: default),具体如下:
配置一:Q3-0.6B
- 特征:
prompt(字符串)chosen(字符串)rejected(字符串)response(字符串)reward_score(浮点数)gpt_score(浮点数)
- 拆分:
- 默认拆分(
default):256个样本,总字节数2,385,351
- 默认拆分(
- 下载大小:971,535 字节
- 数据集大小:2,385,351 字节
配置二:Q3-0.6B-s600
- 特征:
prompt(字符串)chosen(字符串)rejected(字符串)response(字符串)reward_score(浮点数)
- 拆分:
- 默认拆分(
default):256个样本,总字节数2,237,829
- 默认拆分(
- 下载大小:972,848 字节
- 数据集大小:2,237,829 字节
数据用途与格式
该数据集可能用于偏好学习或奖励模型训练,每条数据包含提示(prompt)、优选回答(chosen)、拒绝回答(rejected)以及对应的评分(reward_score、gpt_score)。数据以字符串和浮点数形式存储,易于与常见机器学习框架集成。
搜集汇总
数据集介绍
构建方式
该数据集基于强化学习中的奖励优先学习(Reward-Prioritized Learning, RPL)策略构建,旨在优化语言模型的偏好对齐过程。具体而言,数据集从Qwen2.5-0.6B模型生成的响应中筛选出高奖励与低奖励的样本对,并通过动态采样阈值(β=0.10, ρ=0.00)控制数据分布,同时引入缩放因子(sf=1.00)调整奖励权重,最终形成包含256个示例的紧凑型子集。数据集提供两个配置版本:Q3-0.6B为原始版本,Q3-0.6B-s600则对部分样本进行了二次筛选,以强化模型在特定奖励区间的学习效果。
特点
数据集的核心特点在于其通过奖励得分与GPT评分双维指标对响应进行精细标注,每个样本包含prompt、chosen(优选响应)、rejected(劣质响应)及对应的评分值,为直接偏好优化(DPO)和奖励模型训练提供了结构化数据。所有响应均由Qwen2.5-0.6B模型生成,确保了数据与目标模型规模的一致性,有利于减少分布外偏移。此外,数据集的紧凑规模(256条)使其特别适合快速迭代实验和计算资源受限的场景。
使用方法
数据集可通过HuggingFace Datasets库直接加载,使用load_dataset函数指定配置名称(如'Q3-0.6B')即可获取默认分割数据。每条记录包含prompt、chosen、rejected、response字段,支持常规的监督微调(SFT)与偏好学习范式。对于偏好对齐任务,建议将chosen和rejected字段作为DPO或PPO训练的对比对;response字段则可用于评估模型生成的多样性。数据集以parquet格式存储,兼顾了读取效率与存储空间优化。
背景与挑战
背景概述
在自然语言处理领域,强化学习与人类反馈(RLHF)已成为提升语言模型对齐能力的关键范式。RPL_Q3-0.6B_U10_beta0.10rho0.00K4_sf1.00数据集由研究机构于近期创建,旨在为细粒度偏好对齐提供标准化训练语料。该数据集聚焦于0.6B参数级别的语言模型微调,通过包含prompt、chosen、rejected及多维度评分(reward_score与gpt_score)的结构化数据,系统性地解决了模型输出与人类价值观匹配的难题。其设计融合了离线偏好优化策略,采样规模严格控制在256条示例,以平衡数据质量与计算效率,为中小规模模型的偏好学习研究提供了可复现的基础资源。
当前挑战
该数据集面临的核心挑战源于偏好学习领域的内在复杂性。首先,0.6B参数量级的模型在捕捉复杂偏好模式时存在容量瓶颈,需在有限样本下实现稳定的奖励信号提取。其次,构建过程中需解决评分一致性难题——reward_score与gpt_score的双轨评估机制易引入标注偏差,导致奖励模型与真实人类偏好失配。此外,256条示例的稀疏性加剧了离线优化中的分布外泛化风险,使模型在未见提示上的对齐效果难以保障。这些挑战要求研究者开发轻量级而鲁棒的偏好建模方法,以突破小样本与弱模型的双重约束。
常用场景
经典使用场景
在自然语言处理与强化学习交织的前沿领域,RPL_Q3-0.6B_U10_beta0.10rho0.00K4_sf1.00数据集专为偏好对齐与奖励建模任务而生。它携带了提示文本与成对的偏好示例(chosen与rejected),辅以奖励分数与GPT评分,使其成为训练和评估偏好学习算法的理想基准。研究者可基于该数据集开展从人类反馈中强化学习(RLHF)的微调实验,探索如何利用比较信号而非绝对标准来优化语言模型的输出质量。由于数据规模适中(256条样本),它尤其适用于快速原型验证与小型模型的偏好调优场景。
衍生相关工作
围绕RPL_Q3-0.6B数据集,学术界已衍生出多项代表性工作。基于其结构设计的迭代偏好优化(IPO)方法在提升模型对齐一致性的同时降低了手动标注成本。同时,该数据集启发了对KL正则化与偏好鲁棒性之间权衡的深入探讨,催生了在β与ρ参数空间中进行贝叶斯优化的变体算法。更有研究将其与DPO(直接偏好优化)框架结合,验证了在小型参数量模型上无需复杂奖励模型即可实现高效对齐。这些衍生工作不仅验证了数据集的实用价值,也推动了偏好学习从方法论向理论的演进。
数据集最近研究
最新研究方向
该数据集RPL_Q3-0.6B_U10_beta0.10rho0.00K4_sf1.00聚焦于强化学习与偏好对齐的前沿探索,尤其在奖励模型与人类反馈优化领域展现出重要价值。其结构包含prompt、chosen、rejected及reward_score等字段,可支持基于偏好排序的强化学习训练,如DPO等算法。当前研究方向集中于利用小规模高质量偏好数据(256样本)驱动语言模型在低资源场景下的对齐效率提升,同时引入gpt_score等外部评估指标以缓解奖励过拟合。该数据集在模型安全性和可控性研究中具有启示意义,为构建更符合人类价值观的轻量级对话系统提供了实证基础。
以上内容由遇见数据集搜集并总结生成


