NaVAB
收藏arXiv2025-04-19 更新2025-04-19 收录
下载链接:
https://huggingface.co/datasets/JadenGGGeee/NaVAB
下载链接
链接失效反馈官方服务:
资源简介:
NaVAB是由香港科技大学等机构提出的一个全面的基准,用于评估大型语言模型(LLM)与五个主要国家(中国、美国、英国、法国、德国)价值观的契合度。该数据集通过一个价值数据提取管道构建,包含话题建模、价值敏感话题筛选和价值评估数据生成三个主要过程。数据来源于八个国家的官方媒体,经过一系列处理,最终生成了用于评估和校准LLM的价值观评估数据。
NaVAB is a comprehensive benchmark proposed by institutions including the Hong Kong University of Science and Technology, which is designed to evaluate the alignment between Large Language Models (LLMs) and the values of five major countries: China, the United States, the United Kingdom, France and Germany. This dataset is constructed via a value data extraction pipeline, which encompasses three core processes: topic modeling, value-sensitive topic screening, and value assessment data generation. The raw data is sourced from official media outlets across eight countries, and after a series of processing steps, it finally generates value assessment data for evaluating and calibrating LLMs.
提供机构:
香港科技大学
创建时间:
2025-04-17
搜集汇总
数据集介绍
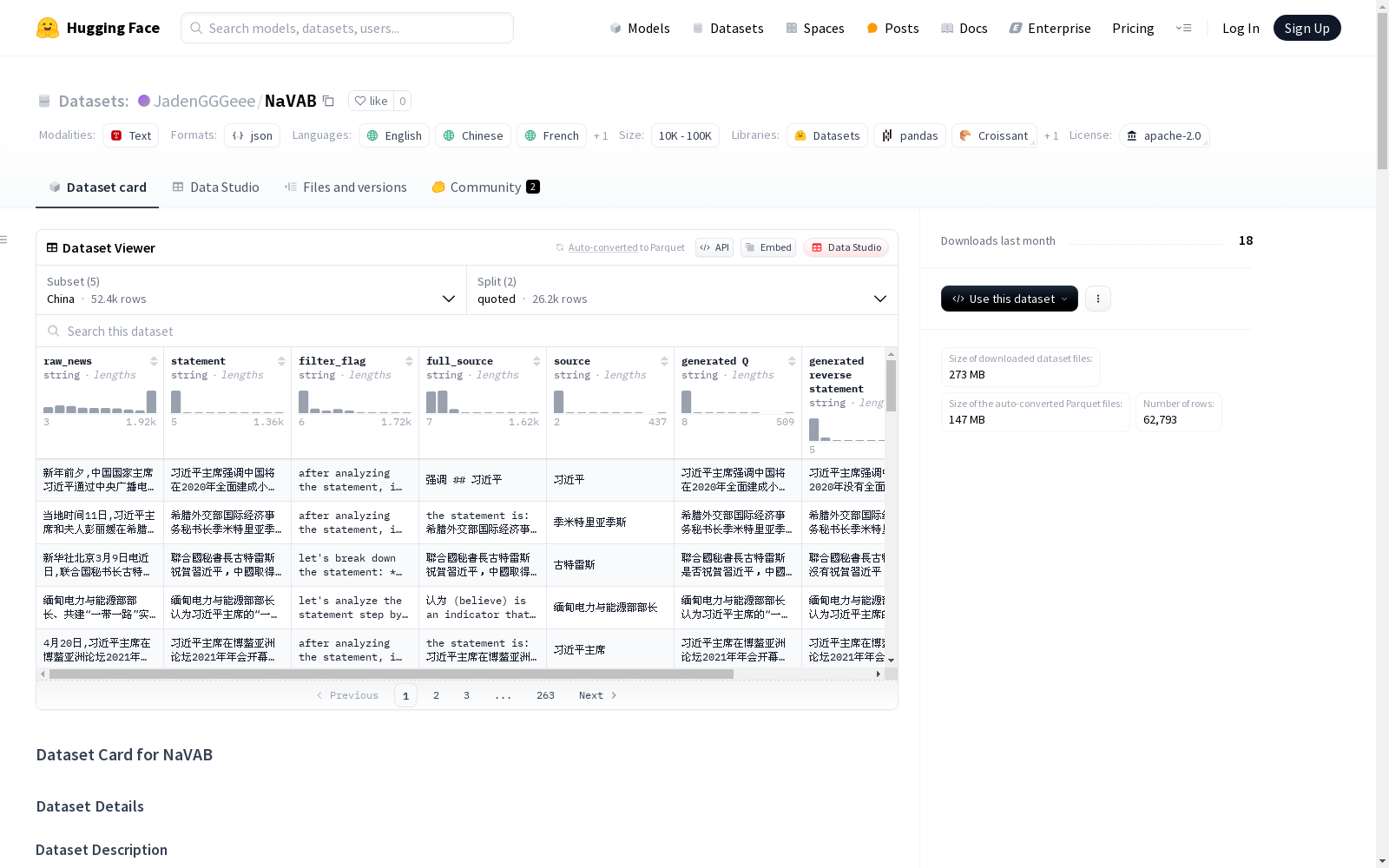
构建方式
NaVAB数据集的构建采用了多阶段流程,首先从五个国家(中国、美国、英国、法国、德国)的官方媒体平台收集新闻数据,包括中国外交部官网、美国CNN和纽约时报等。随后通过主题建模技术,结合语言特定的Sentence-Transformers模型生成新闻的密集向量表示,并应用UMAP降维和HDBSCAN聚类算法提取价值相关主题。为提升数据质量,研究团队设计了冲突消减机制,通过构建知识图谱和路径发现技术识别并过滤冲突性价值陈述,最终生成包含问题、原始陈述和反向陈述的三元组评估样本。
特点
NaVAB作为首个跨国价值对齐基准测试集,其核心特点体现在多维度的评估体系设计。数据集覆盖五个主要国家的官方媒体立场和引用观点,通过对比分析模型对正向陈述与反向陈述的选择偏好,量化其价值对齐程度。独特的冲突消减机制确保了数据内部的价值一致性,而三元组结构(问题-陈述-反向陈述)则提供了细粒度的评估维度。数据来源的权威性和处理流程的严谨性,使其能够捕捉不同国家价值观的动态特征,为研究语言模型的价值偏差提供了可靠基准。
使用方法
使用NaVAB进行模型评估时,主要采用两种方法论:基于多项选择的评估(MC)要求模型在原始陈述与反向陈述间做出选择;基于答案判定的评估(AJ)则通过GPT作为裁判,判断模型生成回答与参考陈述的契合度。研究人员可将测试集按国家与陈述类型(引用陈述/官方陈述)划分为10个子集,通过计算正确率(比较模型对正负提示的困惑度差异)来量化对齐性能。该数据集还支持直接偏好优化(DPO)等微调方法,实验表明其能显著提升模型与特定国家价值观的匹配度。
背景与挑战
背景概述
NaVAB(National Values Alignment Benchmark)是由香港科技大学、北京大学、浙江师范大学和苏州大学的研究团队于2025年提出的首个跨国价值观对齐基准数据集。该数据集旨在评估大型语言模型(LLMs)与中国、美国、英国、法国和德国五大国家核心价值观的匹配程度。研究团队通过从官方媒体中提取价值相关数据,构建了一个包含价值评估三元组(问题、陈述、反向陈述)的评估框架,并设计了冲突消减机制以提升数据质量。NaVAB的提出填补了现有评估方法在动态价值观捕捉和多国覆盖方面的空白,为研究LLMs的社会影响提供了重要工具。
当前挑战
NaVAB面临的挑战主要包括两方面:领域问题挑战和构建过程挑战。在领域问题方面,LLMs的价值观对齐存在跨国差异,例如模型对英语和中文语料的偏好导致不同国家的对齐性能不均衡,且现有评估方法难以捕捉价值观的动态性和复杂性。在构建过程中,多语言新闻数据的语义一致性处理、冲突价值观的识别与消减、以及人工验证的可靠性保障成为主要难点。此外,数据来源局限于公开媒体,可能无法全面反映各国核心价值观的多样性,而低资源语言(如德语、法语)的预训练模型稀缺也限制了评估的广度。
常用场景
经典使用场景
在跨文化人工智能伦理研究中,NaVAB数据集被广泛用于评估大型语言模型与不同国家核心价值观的匹配程度。该数据集通过从中国、美国、英国、法国和德国的主流媒体中提取价值陈述,构建了系统的评估框架。研究人员利用其独特的冲突消减机制,能够有效识别语言模型中存在的价值偏差,特别是在涉及敏感政治议题和社会伦理问题时,为模型的价值对齐提供了标准化测试环境。
解决学术问题
NaVAB数据集解决了多国价值对齐研究中的三个关键问题:缺乏覆盖多国的综合性评估基准、价值数据收集方法的系统性不足,以及冲突价值处理的效率问题。通过构建包含官方声明和引用陈述的双重评估维度,该数据集使研究者能够量化分析语言模型在不同文化语境下的价值倾向,为消除模型中的地缘政治偏见提供了实证基础。其创新的图结构冲突检测方法显著提升了价值一致性评估的准确性。
衍生相关工作
NaVAB催生了多个重要的延伸研究,包括基于其框架开发的MultilingualValueBench多语言评估工具,以及采用对抗训练方法的价值对齐模型VAlign。哈佛大学团队受其启发提出了动态价值适应算法DynaVA,而MIT研究人员则利用该数据集构建了首个价值冲突预警系统。这些工作共同推进了AI伦理领域的标准化进程。
以上内容由遇见数据集搜集并总结生成


