有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
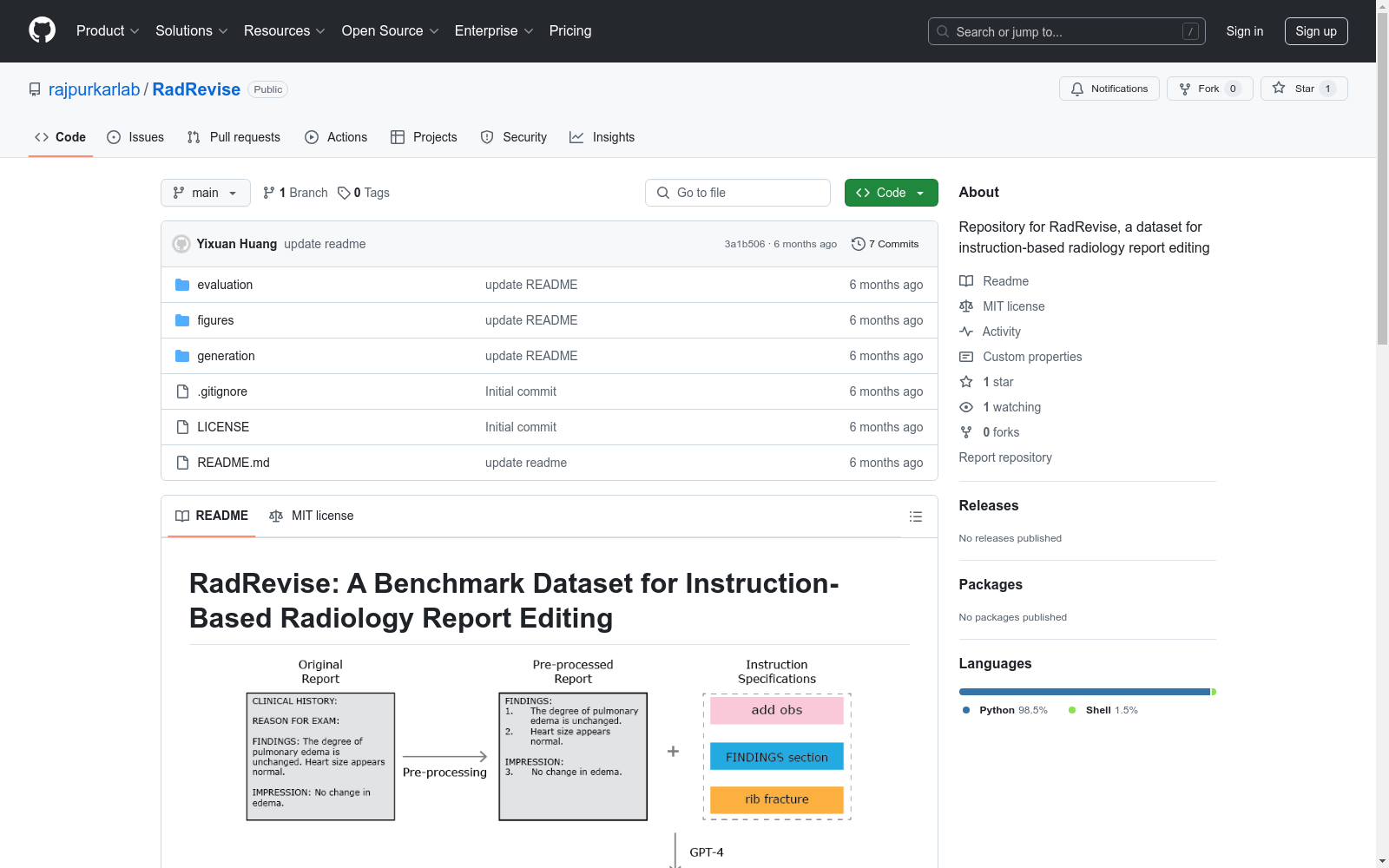
RadRevise 是一个用于指令型放射报告编辑的基准数据集。该数据集通过开放认证流程在 PhysioNet 上提供。
数据集使用 GPT-4 生成基于特定类型指令和临床主题的指令和修改后的报告。需要注意的是,生成结果会与 RadRevise 有所不同,因为 GPT 生成的响应和 RadRevise 经过的人工审查和注释过程。
generation 目录。数据集可用于评估任何托管在 Hugging Face 上的文本生成模型。
下载 RadRevise 数据集。
导航到 evaluation 目录。
运行以下命令评估单个模型: bash python eval_model $MODEL_ID [$DATA_PATH] [$BATCH_SIZE] [$OUTPUT_FILE]
$MODEL_ID: Hugging Face 模型 ID$DATA_PATH: RadRevise 数据集路径(默认:../data/RadRevise_v0.csv)$BATCH_SIZE: 推理批次大小(默认:32)$OUTPUT_FILE: 评估输出文件名(默认:output/result.csv)或者,修改并执行 run.sh 脚本来评估一个或多个模型。
该数据集仓库在 MIT 许可证下公开可用。
UniProt
UniProt(Universal Protein Resource)是全球公认的蛋白质序列与功能信息权威数据库,由欧洲生物信息学研究所(EBI)、瑞士生物信息学研究所(SIB)和美国蛋白质信息资源中心(PIR)联合运营。该数据库以其广度和深度兼备的蛋白质信息资源闻名,整合了实验验证的高质量数据与大规模预测的自动注释内容,涵盖从分子序列、结构到功能的全面信息。UniProt核心包括注释详尽的UniProtKB知识库(分为人工校验的Swiss-Prot和自动生成的TrEMBL),以及支持高效序列聚类分析的UniRef和全局蛋白质序列归档的UniParc。其卓越的数据质量和多样化的检索工具,为基础研究和药物研发提供了无可替代的支持,成为生物学研究中不可或缺的资源。
www.uniprot.org 收录
中国区域交通网络数据集
该数据集包含中国各区域的交通网络信息,包括道路、铁路、航空和水路等多种交通方式的网络结构和连接关系。数据集详细记录了各交通节点的位置、交通线路的类型、长度、容量以及相关的交通流量信息。
data.stats.gov.cn 收录
VQA
我们提出了自由形式和开放式视觉问答 (VQA) 的任务。给定图像和关于图像的自然语言问题,任务是提供准确的自然语言答案。反映许多现实世界的场景,例如帮助视障人士,问题和答案都是开放式的。视觉问题有选择地针对图像的不同区域,包括背景细节和底层上下文。因此,与生成通用图像说明的系统相比,在 VQA 上取得成功的系统通常需要对图像和复杂推理有更详细的理解。此外,VQA 适合自动评估,因为许多开放式答案仅包含几个单词或一组封闭的答案,可以以多项选择的形式提供。我们提供了一个数据集包含 100,000 的图像和问题并讨论它提供的信息。提供了许多 VQA 基线,并与人类表现进行了比较。
OpenDataLab 收录
中国食物成分数据库
食物成分数据比较准确而详细地描述农作物、水产类、畜禽肉类等人类赖以生存的基本食物的品质和营养成分含量。它是一个重要的我国公共卫生数据和营养信息资源,是提供人类基本需求和基本社会保障的先决条件;也是一个国家制定相关法规标准、实施有关营养政策、开展食品贸易和进行营养健康教育的基础,兼具学术、经济、社会等多种价值。 本数据集收录了基于2002年食物成分表的1506条食物的31项营养成分(含胆固醇)数据,657条食物的18种氨基酸数据、441条食物的32种脂肪酸数据、130条食物的碘数据、114条食物的大豆异黄酮数据。
国家人口健康科学数据中心 收录
FER2013
FER2013数据集是一个广泛用于面部表情识别领域的数据集,包含28,709个训练样本和7,178个测试样本。图像属性为48x48像素,标签包括愤怒、厌恶、恐惧、快乐、悲伤、惊讶和中性。
github 收录