MultiSPA
收藏arXiv2025-05-23 更新2025-05-25 收录
下载链接:
https://runsenxu.com/projects/Multi-SpatialMLLM
下载链接
链接失效反馈官方服务:
资源简介:
MultiSPA是一个大规模的多帧空间理解数据集,包含超过2700万个样本,涵盖了多样化的3D和4D场景。该数据集支持多种模态的引用和输出格式,包括视觉点注释、像素坐标和语义标签,从而拓宽了潜在的应用场景。数据集包含了从文本到标量、二维像素位置和三维位移向量等多种类型的空间信息。研究人员利用现有的注释3D和4D数据集进行数据收集,并通过采样具有均匀重叠分布的图像对以及回投影空间和时间对齐的点云来建立像素对应关系。MultiSPA数据集旨在帮助多模态大型语言模型更好地理解多帧空间信息,并用于机器人等实际应用中的空间推理任务。
MultiSPA is a large-scale multi-frame spatial understanding dataset containing over 27 million samples and covering diverse 3D and 4D scenarios. This dataset supports multiple modal input and output formats, including visual point annotations, pixel coordinates, and semantic labels, thus expanding its potential application scenarios. The dataset encompasses various types of spatial information ranging from text to scalars, 2D pixel positions, and 3D displacement vectors. Researchers collected data using existing annotated 3D and 4D datasets, and established pixel correspondences by sampling image pairs with uniformly overlapping distributions and back-projecting spatially and temporally aligned point clouds. The MultiSPA dataset aims to assist multimodal large language models in better understanding multi-frame spatial information, and supports spatial reasoning tasks in real-world applications such as robotics.
提供机构:
香港中文大学
创建时间:
2025-05-23
原始信息汇总
Multi-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models
概述
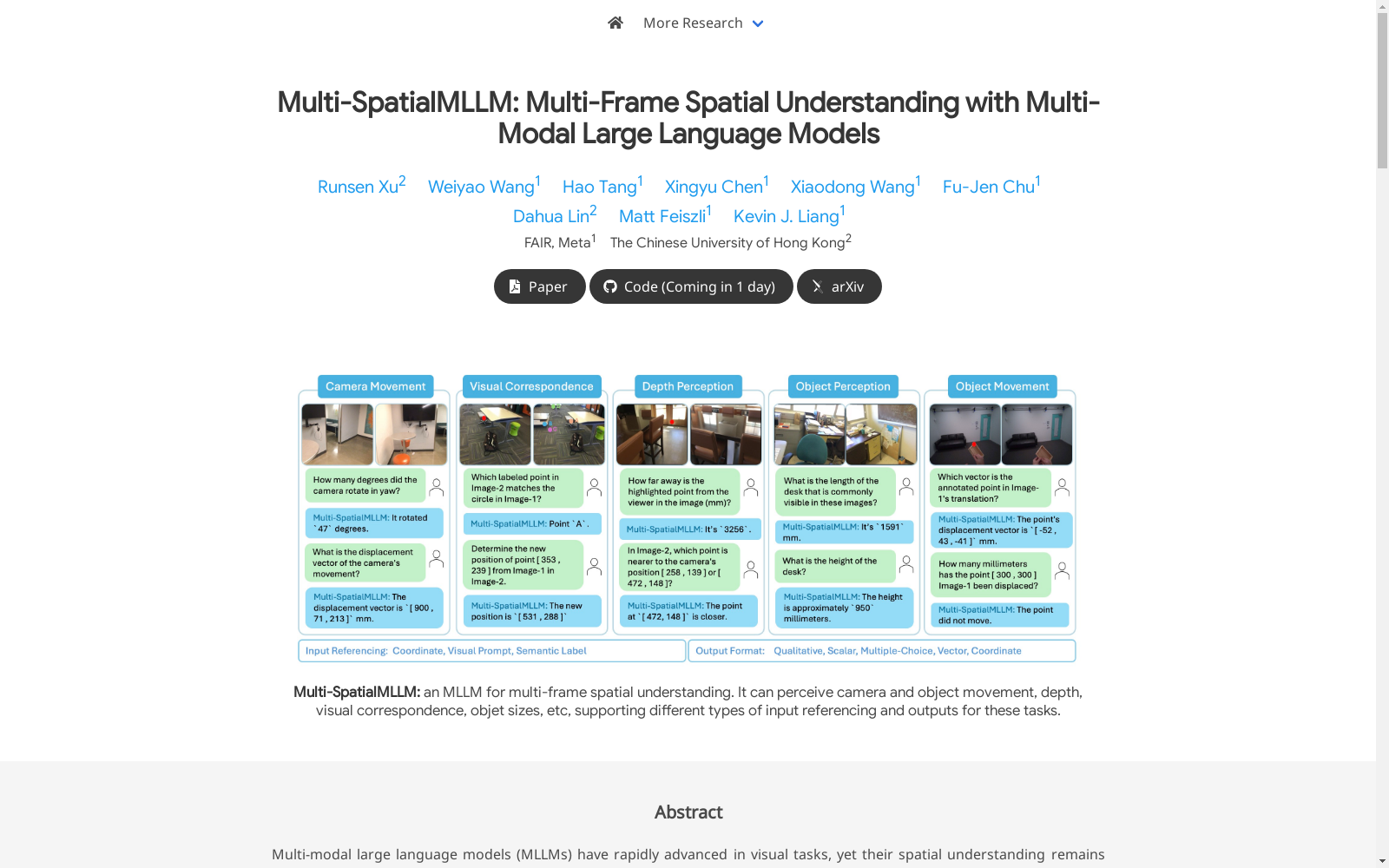
Multi-SpatialMLLM 是一个多模态大语言模型(MLLM),专注于多帧空间理解。它能够感知相机和物体运动、深度、视觉对应关系、物体大小等,支持不同类型的输入引用和输出。
数据集与基准
- MultiSPA数据集:包含超过2700万个样本,涵盖多样化的3D和4D场景。
- MultiSPA基准:专注于多帧空间理解,采用统一的准确性指标,每个任务有各自的真阳性结果判定标准。
数据引擎与生成
- 静态数据引擎:为每个静态场景根据重叠率采样图像对,并计算元空间信息以构建问答对。
- 刚体分割:使用4D数据集(4D物体跟踪数据集)构建物体运动感知数据,通过刚体分割方法确保多样性。
- 数据生成模块:更多细节见论文。
实验成果
- MultiSPA基准表现:Multi-SpatialMLLM在定性和定量子任务上显著优于基线,平均提升36%,超越更大的专有模型。
- 泛化性能:在BLINK数据集和通用VQA基准上表现出强大的泛化能力。
- 可扩展性能:通过增加可训练参数和训练数据,性能进一步提升。
- 涌现能力:在困难的空间理解任务(如视觉对应任务)中,仅大型模型通过微调能取得更好表现。
机器人应用
- 可作为多帧奖励标注器,用于机器人学习。
- 能够预测给定两帧中目标物体的移动距离。
参考文献
bibtex @article{xu2025multi, title={Multi-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models}, author={Xu, Runsen and Wang, Weiyao and Tang, Hao and Chen, Xingyu and Wang, Xiaodong and Chu, Fu-Jen and Lin, Dahua and Feiszli, Matt and Liang, Kevin J.}, journal={arXiv preprint arXiv:2505.17015}, year={2025} }
搜集汇总
数据集介绍
构建方式
MultiSPA数据集的构建依托于现有标注丰富的3D和4D场景数据集,如ScanNet和TAPVid3D,通过精心设计的数据引擎实现多帧空间对齐。研究团队开发了一套自动化流程,首先计算图像对之间的重叠区域,确保采样覆盖6%-35%的合理重叠范围以避免内容冗余或不足。通过反向投影时空对齐的点云建立像素级对应关系,结合相机运动与投影信息,利用大语言模型生成多样化问答模板,最终构建包含2700万样本的大规模数据集。数据生成过程特别注重平衡不同重叠比例的图像对采样,并采用归一化坐标处理以适应不同分辨率。
特点
作为首个专注于多帧空间理解的大规模数据集,MultiSPA具有三大核心特征:多模态输入支持(视觉点标注、像素坐标和语义标签)、多样化输出形式(定性描述、标量值、2D/3D坐标及位移向量)以及系统化的任务设计(深度感知、视觉对应、动态感知等五大类26个子任务)。数据集覆盖静态场景与动态物体追踪,通过严格的可见点计算和重叠率控制确保数据质量,其问答对设计采用标准化模板与毫米级精度单位,特别创新地引入归一化坐标表示以增强模型泛化能力。
使用方法
使用MultiSPA需遵循多模态大语言模型的典型微调范式,采用'<image>...<image>{描述}{问题}'作为输入格式,'Assistant:{答案}'作为输出格式。答案提取采用反引号标记技术,数值答案统一采用毫米单位并取整。评估时需根据任务类型采用差异化标准:定性任务采用精确字符串匹配,定量任务允许20%误差容限,坐标预测则接受5%图像宽度的偏差。研究人员建议将数据集与通用视觉指令数据混合训练以保持基础能力,并可通过LoRA等参数高效微调方法实现模型适配。数据集配套的标准化评测基准包含7800个保留样本,确保与训练场景的分布差异性。
背景与挑战
背景概述
MultiSPA数据集由Meta与香港中文大学的研究团队于2025年推出,旨在解决多模态大语言模型(MLLMs)在多帧空间理解方面的局限性。该数据集包含超过2700万样本,涵盖多样化的3D和4D场景,专注于深度感知、视觉对应和动态感知等核心空间推理能力。作为首个大规模多帧空间理解数据集,MultiSPA通过统一度量标准下的综合基准测试,显著提升了模型在机器人、自动驾驶等现实应用中的空间推理性能,推动了多模态模型从静态图像理解向动态环境交互的范式转变。
当前挑战
MultiSPA面临双重挑战:在领域层面,需突破现有MLLMs单帧空间理解的局限,解决跨帧深度估计、动态目标追踪等复杂任务;在构建层面,需克服多视角数据时空对齐的难题,通过开发基于点云反投影的数据引擎实现像素级对应,并利用LLM生成多样化问答模板以保证数据质量与规模。此外,从单帧到多帧的范式转换还面临计算复杂度激增、长尾分布样本平衡等工程挑战。
常用场景
经典使用场景
MultiSPA数据集在计算机视觉与多模态大语言模型(MLLMs)的交叉领域具有重要应用价值,尤其在多帧空间理解任务中表现突出。该数据集通过整合深度感知、视觉对应和动态感知三大核心能力,为模型提供了从静态单帧推理扩展到动态多帧分析的训练基础。其经典应用场景包括机器人导航中的环境空间建模、增强现实系统的实时场景解析,以及自动驾驶车辆的多视角路径规划,这些场景均需模型对连续帧间的空间关系进行精确推理。
衍生相关工作
围绕MultiSPA衍生的研究呈现多元化发展态势。SpatialVLM和SpatialRGPT等单帧空间理解模型通过引入该数据集的迁移学习方法显著提升了深度估计精度;BLINK基准则扩展了其评估框架至开放域场景理解。近期提出的SAT模拟器尝试将MultiSPA的标注范式应用于合成数据生成,而RoboSpace项目则专注于机器人操作场景下的多模态空间指令微调。这些工作共同构成了从静态到动态、从感知到决策的空间智能研究谱系。
数据集最近研究
最新研究方向
MultiSPA数据集作为首个专注于多帧空间理解的大规模数据集,在机器人学和增强现实等需要动态场景感知的领域引发了广泛关注。其创新性地整合了深度感知、视觉对应和动态感知三大核心能力,通过27M样本覆盖多样化的3D/4D场景,为多模态大语言模型(MLLMs)提供了前所未有的空间推理训练基准。近期研究热点集中在三个方向:一是探索模型在跨帧场景下的深度一致性推理能力,二是利用该数据集开发新型空间奖励标注系统以优化机器人决策,三是验证多任务协同训练对复杂空间任务(如相机位移向量预测)的促进作用。该数据集通过统一度量标准下的综合评测体系,显著推动了MLLMs在动态环境中的实用化进程,相关成果已被应用于自动驾驶的实时空间建模和AR设备的场景理解增强。
相关研究论文
- 1Multi-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models香港中文大学 · 2025年
以上内容由遇见数据集搜集并总结生成


