olmOCR-bench
收藏魔搭社区2026-04-28 更新2025-05-31 收录
下载链接:
https://modelscope.cn/datasets/allenai/olmOCR-bench
下载链接
链接失效反馈官方服务:
资源简介:
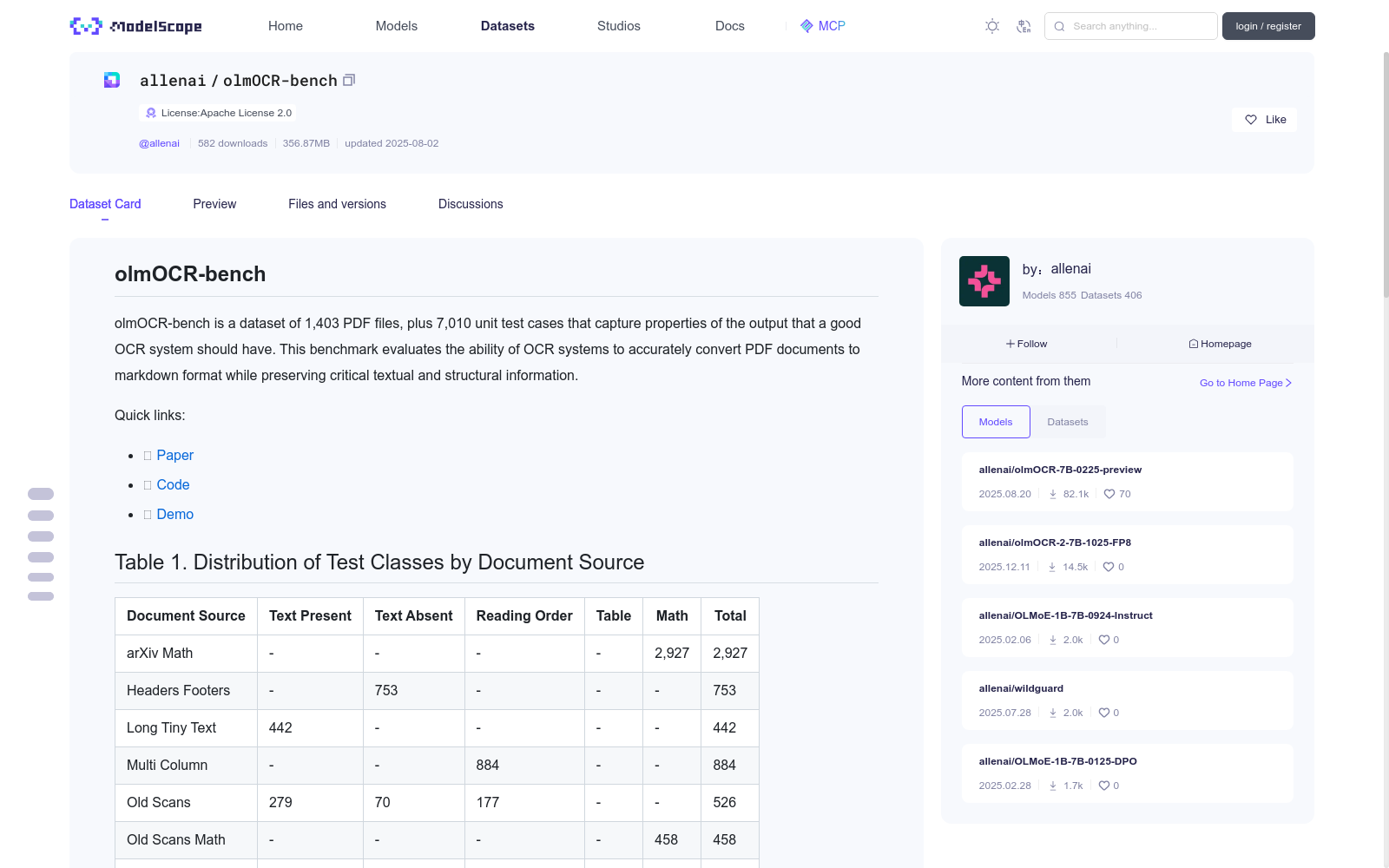
# olmOCR-bench
olmOCR-bench is a dataset of 1,403 PDF files, plus 7,010 unit test cases that capture properties of the output that a good OCR system should have.
This benchmark evaluates the ability of OCR systems to accurately convert PDF documents to markdown format while preserving critical textual and structural information.
Quick links:
- 📃 [Paper](https://huggingface.co/papers/2502.18443)
- 🛠️ [Code](https://github.com/allenai/olmocr)
- 🎮 [Demo](https://olmocr.allenai.org/)
## Table 1. Distribution of Test Classes by Document Source
| Document Source | Text Present | Text Absent | Reading Order | Table | Math | Total |
|----------------|--------------|-------------|---------------|-------|------|-------|
| arXiv Math | - | - | - | - | 2,927| 2,927 |
| Headers Footers| - | 753 | - | - | - | 753 |
| Long Tiny Text | 442 | - | - | - | - | 442 |
| Multi Column | - | - | 884 | - | - | 884 |
| Old Scans | 279 | 70 | 177 | - | - | 526 |
| Old Scans Math | - | - | - | - | 458 | 458 |
| Table Tests | - | - | - | 1,020 | - | 1,020 |
| **Total** | 721 | 823 | 1,061 | 1,020 | 3,385| 7,010 |
## Table 2. Document source category breakdown
| **Category** | **PDFs** | **Tests** | **Source** | **Extraction Method** |
|--------------|----------|-----------|------------|------------------------|
| arXiv_math | 522 | 2,927 | arXiv | Dynamic programming alignment |
| old_scans_math | 36 | 458 | Internet Archive | Script-generated + manual rules |
| tables_tests | 188 | 1,020 | Internal repository | `gemini-flash-2.0` |
| old_scans | 98 | 526 | Library of Congress | Manual rules |
| headers_footers | 266 | 753 | Internal repository | DocLayout-YOLO + `gemini-flash-2.0` |
| multi_column | 231 | 884 | Internal repository | `claude-sonnet-3.7` + HTML rendering |
| long_tiny_text | 62 | 442 | Internet Archive | `gemini-flash-2.0` |
| **Total** | 1,403 | 7,010 | Multiple sources | |
## Evaluation Criteria
- Text Presence: Checks if a short text segment (1–3 sentences) is correctly identified in the OCR output. Supports fuzzy matching and positional constraints (e.g., must appear in the first/last N characters). Case-sensitive by default.
- Text Absence: Ensures specified text (e.g., headers, footers, page numbers) is excluded. Supports fuzzy matching and positional constraints. Not case-sensitive.
- Natural Reading Order: Verifies the relative order of two text spans (e.g., headline before paragraph). Soft matching enabled; case-sensitive by default.
- Table Accuracy: Confirms that specific cell values exist in tables with correct neighboring relationships (e.g., value above/below another). Supports Markdown and HTML, though complex structures require HTML.
- Math Formula Accuracy: Detects the presence of a target equation by matching symbol layout (e.g., $\int$ to the left of $x$). Based on rendered bounding boxes and relative positioning.
### 📊 Benchmark Results by Document Source
| **Model** | ArXiv | Base | Hdr/Ftr | TinyTxt | MultCol | OldScan | OldMath | Tables | Overall |
|---------------------------|:-----:|:----:|:-------:|:-------:|:-------:|:-------:|:-------:|:------:|:-----------:|
| GOT OCR | 52.7 | 94.0 | 93.6 | 29.9 | 42.0 | 22.1 | 52.0 | 0.2 | 48.3 ± 1.1 |
| Marker v1.6.2 | 24.3 | **99.5** | 87.1 | 76.9 | 71.0 | 24.3 | 22.1 | 69.8 | 59.4 ± 1.1 |
| MinerU v1.3.10 | 75.4 | 96.6 | **96.6**| 39.1 | 59.0 | 17.3 | 47.4 | 60.9 | 61.5 ± 1.1 |
| Mistral OCR API | **77.2** | 99.4 | 93.6 | 77.1 | 71.3 | 29.3 | 67.5 | 60.6 | 72.0 ± 1.1 |
| GPT-4o (Anchored) | 53.5 | 96.8 | 93.8 | 60.6 | 69.3 | 40.7 | 74.5 | 70.0 | 69.9 ± 1.1 |
| GPT-4o (No Anchor) | 51.5 | 96.7 | 94.2 | 54.1 | 68.9 | 40.9 | **75.5**| 69.1 | 68.9 ± 1.1 |
| Gemini Flash 2 (Anchored) | 54.5 | 95.6 | 64.7 | 71.5 | 61.5 | 34.2 | 56.1 | **72.1**| 63.8 ± 1.2 |
| Gemini Flash 2 (No Anchor)| 32.1 | 94.0 | 48.0 | **84.4**| 58.7 | 27.8 | 56.3 | 61.4 | 57.8 ± 1.1 |
| Qwen 2 VL (No Anchor) | 19.7 | 55.5 | 88.9 | 6.8 | 8.3 | 17.1 | 31.7 | 24.2 | 31.5 ± 0.9 |
| Qwen 2.5 VL (No Anchor) | 63.1 | 98.3 | 73.6 | 49.1 | 68.3 | 38.6 | 65.7 | 67.3 | 65.5 ± 1.2 |
| **Ours (No Anchor)** | 72.1 | 98.1 | 91.6 | 80.5 | 78.5 | 43.7 | 74.7 | 71.5 | 76.3 ± 1.1 |
| **Ours (Anchored)** | 75.6 | 99.0 | 93.4 | 81.7 | **79.4**| **44.5**| 75.1 | 70.2 | **77.4 ± 1.0** |
### License
This dataset is licensed under ODC-BY-1.0. It is intended for research and educational use in accordance with AI2's [Responsible Use Guidelines](https://allenai.org/responsible-use).
# olmOCR-bench
olmOCR-bench 是一个包含1403个PDF文件,以及7010个单元测试用例的基准数据集,这些用例涵盖了优秀光学字符识别(Optical Character Recognition,OCR)系统输出应具备的各项属性。
本基准用于评估OCR系统将PDF文档精准转换为Markdown格式的能力,同时需保留关键文本与结构信息。
快速访问链接:
- 📃 [论文](https://olmocr.allenai.org/papers/olmocr.pdf)
- 🛠️ [代码](https://github.com/allenai/olmocr)
- 🎮 [演示](https://olmocr.allenai.org/)
## 表1 按文档来源划分的测试用例类别分布
| 文档来源 | 文本存在 | 文本缺失 | 阅读顺序 | 表格 | 数学公式 | 总计 |
|------------------|----------|----------|----------|-------|----------|--------|
| arXiv 数学文档 | - | - | - | - | 2,927 | 2,927 |
| 页眉页脚 | - | 753 | - | - | - | 753 |
| 长文本与微小文本 | 442 | - | - | - | - | 442 |
| 多栏布局文档 | - | - | 884 | - | - | 884 |
| 老旧扫描文档 | 279 | 70 | 177 | - | - | 526 |
| 老旧扫描数学文档 | - | - | - | - | 458 | 458 |
| 表格测试集 | - | - | - | 1,020 | - | 1,020 |
| **总计** | 721 | 823 | 1,061 | 1,020 | 3,385 | 7,010 |
## 表2 文档来源类别细分
| **类别** | **PDF文件数** | **测试用例数** | **来源** | **提取方法** |
|----------------------|---------------|----------------|------------------------|----------------------------------|
| arXiv_数学 | 522 | 2,927 | arXiv | 动态规划对齐 |
| 老旧扫描数学文档 | 36 | 458 | Internet Archive | 脚本生成+人工规则 |
| 表格测试集 | 188 | 1,020 | 内部仓库 | `gemini-flash-2.0` |
| 老旧扫描文档 | 98 | 526 | 美国国会图书馆 | 人工规则 |
| 页眉页脚 | 266 | 753 | 内部仓库 | DocLayout-YOLO + `gemini-flash-2.0` |
| 多栏布局文档 | 231 | 884 | 内部仓库 | `claude-sonnet-3.7` + HTML渲染 |
| 长文本与微小文本 | 62 | 442 | Internet Archive | `gemini-flash-2.0` |
| **总计** | 1,403 | 7,010 | 多来源 | |
## 评估标准
- 文本存在:检查短文本片段(1-3个句子)是否在OCR输出中被正确识别。支持模糊匹配与位置约束(例如,必须出现在前/后N个字符范围内),默认区分大小写。
- 文本缺失:确保指定文本(例如页眉、页脚、页码)未被包含。支持模糊匹配与位置约束,默认不区分大小写。
- 自然阅读顺序:验证两个文本片段的相对顺序(例如标题位于段落之前),启用软匹配,默认区分大小写。
- 表格准确性:确认表格中特定单元格值存在且邻接关系正确(例如某值位于另一值的上方/下方)。支持Markdown与HTML格式,复杂结构需使用HTML。
- 数学公式准确性:通过匹配符号布局检测目标公式是否存在(例如$int$位于$x$左侧),基于渲染后的边界框与相对位置进行判断。
### 📊 按文档来源划分的基准测试结果
| **模型** | ArXiv | Base | 页眉/页脚 | 微小文本 | 多栏布局 | 老旧扫描文档 | 老旧扫描数学文档 | 表格 | 总体得分 |
|------------------------------|:-----:|:----:|:---------:|:--------:|:--------:|:------------:|:----------------:|:-----:|:---------------:|
| GOT OCR | 52.7 | 94.0 | 93.6 | 29.9 | 42.0 | 22.1 | 52.0 | 0.2 | 48.3 ± 1.1 |
| Marker v1.6.2 | 24.3 | **99.5** | 87.1 | 76.9 | 71.0 | 24.3 | 22.1 | 69.8 | 59.4 ± 1.1 |
| MinerU v1.3.10 | 75.4 | 96.6 | **96.6** | 39.1 | 59.0 | 17.3 | 47.4 | 60.9 | 61.5 ± 1.1 |
| Mistral OCR API | **77.2** | 99.4 | 93.6 | 77.1 | 71.3 | 29.3 | 67.5 | 60.6 | 72.0 ± 1.1 |
| GPT-4o(锚定版) | 53.5 | 96.8 | 93.8 | 60.6 | 69.3 | 40.7 | 74.5 | 70.0 | 69.9 ± 1.1 |
| GPT-4o(无锚定版) | 51.5 | 96.7 | 94.2 | 54.1 | 68.9 | 40.9 | **75.5** | 69.1 | 68.9 ± 1.1 |
| Gemini Flash 2(锚定版) | 54.5 | 95.6 | 64.7 | 71.5 | 61.5 | 34.2 | 56.1 | **72.1** | 63.8 ± 1.2 |
| Gemini Flash 2(无锚定版) | 32.1 | 94.0 | 48.0 | **84.4** | 58.7 | 27.8 | 56.3 | 61.4 | 57.8 ± 1.1 |
| Qwen 2 VL(无锚定版) | 19.7 | 55.5 | 88.9 | 6.8 | 8.3 | 17.1 | 31.7 | 24.2 | 31.5 ± 0.9 |
| Qwen 2.5 VL(无锚定版) | 63.1 | 98.3 | 73.6 | 49.1 | 68.3 | 38.6 | 65.7 | 67.3 | 65.5 ± 1.2 |
| **本模型(无锚定版)** | 72.1 | 98.1 | 91.6 | 80.5 | 78.5 | 43.7 | 74.7 | 71.5 | 76.3 ± 1.1 |
| **本模型(锚定版)** | **75.6** | 99.0 | 93.4 | 81.7 | **79.4** | **44.5** | 75.1 | 70.2 | **77.4 ± 1.0** |
### 许可证
本数据集采用ODC-BY-1.0许可证发布,仅可用于研究与教育用途,需遵循艾伦人工智能研究所(Allen Institute for Artificial Intelligence,AI2)的[负责任使用指南](https://allenai.org/responsible-use)。
提供机构:
maas
创建时间:
2025-05-29
搜集汇总
数据集介绍
背景与挑战
背景概述
olmOCR-bench是一个用于评估OCR系统将PDF文档准确转换为Markdown格式的基准数据集,包含1,403个PDF文件和7,010个单元测试用例,覆盖文本存在、缺失、阅读顺序、表格和数学公式等多种测试类别。数据集来源广泛,包括arXiv和Internet Archive等,并提供了多个主流OCR模型的性能对比结果,旨在全面测试OCR系统在保留文本和结构信息方面的能力。
以上内容由遇见数据集搜集并总结生成


