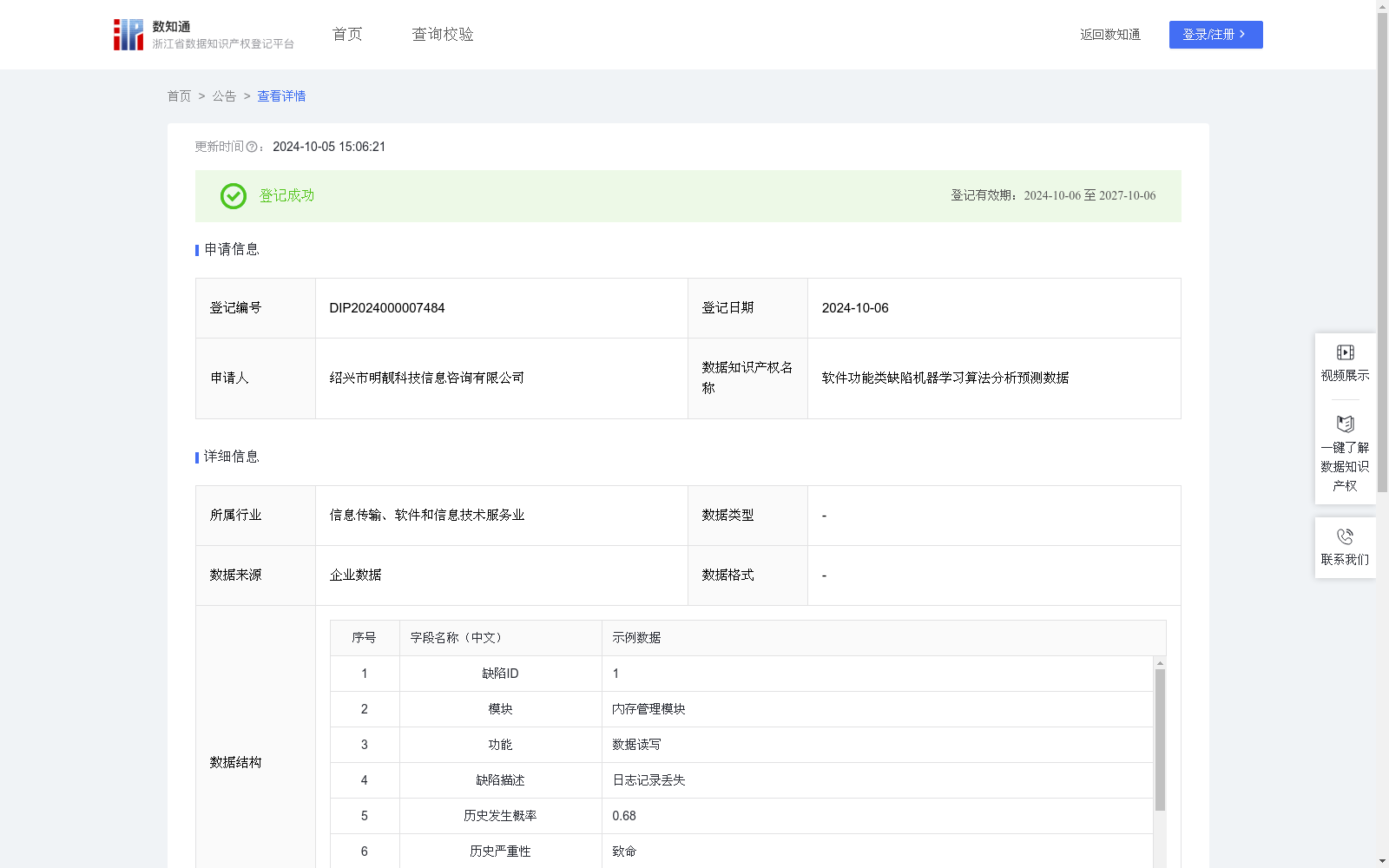
软件功能类缺陷机器学习算法分析预测数据
收藏浙江省数据知识产权登记平台2024-10-05 更新2024-10-06 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/67817
下载链接
链接失效反馈官方服务:
资源简介:
机器学习算法在软件功能类缺陷分析和预测中越来越受到关注。本类方法通过学习历史缺陷数据,建立预测模型,能够自动识别和预测新缺陷的发生概率、严重性及其对系统的潜在影响,从而提高缺陷管理的效率和准确性。这种预测方法尤其适用于大型复杂系统中,帮助开发和运维团队提前采取预防措施,降低系统风险。在CI/CD环境中,缺陷预测可以提前预警潜在问题,避免问题在交付到生产环境后才被发现。通过学习历史缺陷和系统运行数据,预测哪些模块或功能容易发生缺陷,提前安排测试和修复。在实时性要求极高的系统中,机器学习模型可能无法及时响应突发情况,需要结合其他实时性分析工具使用。通过使用机器学习算法分析和预测软件功能类缺陷,团队可以有效提高缺陷管理的效率和准确性,尤其是在复杂系统和多源数据场景中。通过预测未来的缺陷发生概率和严重性,团队可以提前做好应对措施,降低系统风险,提升软件的整体质量。综合效能 = (预测发生概率权重 × 预测发生概率) + (预测严重性权重 × 预测严重性得分)
权重分配规则:预测发生概率权重 = 0.5预测严重性权重 = 0.5
预测严重性得分:致命 = 10高 = 7中 = 5低 = 2
通过分析“综合效能”列,使用者可以快速通过综合效能值判断哪些缺陷需要优先处理。通常,综合效能值越高,表示该缺陷对系统的潜在影响越大,优先处理的必要性也越高。这样可以更好地指导资源分配和缺陷修复的优先级决策。
Machine learning algorithms have gained increasing attention in software functional defect analysis and prediction. This type of method learns from historical defect data to build predictive models, which can automatically identify and predict the occurrence probability, severity and potential system-wide impact of new defects, thereby improving the efficiency and accuracy of defect management. This predictive approach is particularly suitable for large-scale complex systems, helping development and operation and maintenance (O&M) teams take preventive measures in advance to reduce system risks. In CI/CD environments, defect prediction can provide early warnings of potential problems, avoiding the situation where issues are only discovered after being deployed to the production environment. By learning historical defect and system operation data, it can predict which modules or functions are prone to defects, and arrange testing and repairs in advance. In systems with extremely high real-time requirements, machine learning models may fail to respond to emergencies in a timely manner, requiring integration with other real-time analysis tools. By using machine learning algorithms to analyze and predict software functional defects, teams can effectively improve the efficiency and accuracy of defect management, especially in complex systems and multi-source data scenarios. By predicting the future occurrence probability and severity of defects, teams can prepare response measures in advance, reduce system risks, and improve the overall quality of software. Comprehensive Effectiveness = (Weight of Occurrence Probability Prediction × Predicted Occurrence Probability) + (Weight of Severity Prediction × Predicted Severity Score). Weight Allocation Rules: Weight of Occurrence Probability Prediction = 0.5; Weight of Severity Prediction = 0.5. Predicted Severity Score: Critical = 10; High = 7; Medium = 5; Low = 2. By analyzing the "Comprehensive Effectiveness" column, users can quickly determine which defects require priority handling based on their comprehensive effectiveness values. Generally, a higher comprehensive effectiveness value indicates a greater potential impact of the defect on the system and a higher necessity for priority handling. This can better guide resource allocation and priority decision-making for defect repair.
提供机构:
绍兴市明靓科技信息咨询有限公司
创建时间:
2024-09-01
搜集汇总
数据集介绍
特点
该数据集名为“软件功能类缺陷机器学习算法分析预测数据”,属于信息传输、软件和信息技术服务业,数据来源于企业,包含530条记录,每年更新一次。数据集通过机器学习算法分析历史缺陷数据,预测新缺陷的发生概率、严重性及其对系统的潜在影响,适用于大型复杂系统中的缺陷管理,帮助团队提前采取预防措施,降低系统风险。
以上内容由遇见数据集搜集并总结生成


