ArVoice
收藏arXiv2025-05-27 更新2025-05-29 收录
下载链接:
https://huggingface.co/datasets/MBZUAI/ArVoice
下载链接
链接失效反馈官方服务:
资源简介:
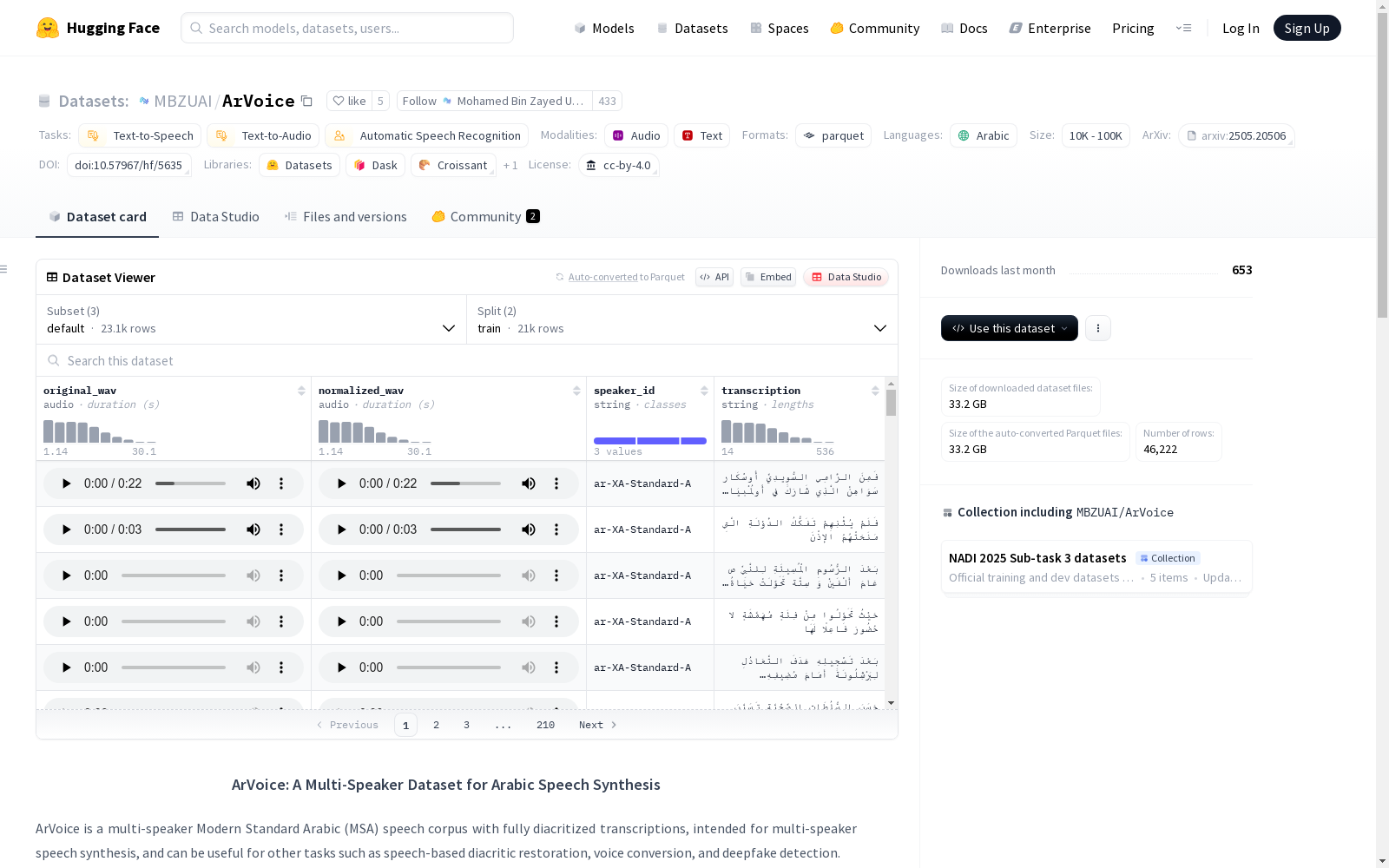
ArVoice是一个包含多种发音的现代标准阿拉伯语(MSA)语音语料库,包含带变音符号的转录文本,主要用于多发音人语音合成,也可用于语音基转换、声音转换和深度伪造检测等任务。该数据集包括:1)六位声音人才的新专业录音集,具有多样化的人口统计数据;2)阿拉伯语音语料库的修改子集;3)来自两个商业系统的优质合成语音。整个语料库共有83.52小时的语音,涵盖11个声音,其中约10小时由7位说话者的真人声音组成。我们训练了三个开源的文本到语音(TTS)和两个声音转换系统,以展示数据集的使用案例。语料库可供研究使用。
ArVoice is a speech corpus for Modern Standard Arabic (MSA) featuring diverse pronunciations, equipped with diacritized transcriptions. Primarily designed for multi-speaker text-to-speech synthesis, it can also be utilized for tasks such as speech-based conversion, voice conversion, and deepfake detection. The dataset comprises three components: 1) A new professional recording dataset from six voice talents with diverse demographic characteristics; 2) A modified subset of an existing Arabic speech corpus; 3) High-quality synthesized speech from two commercial systems. The entire corpus spans 83.52 hours of speech covering 11 voice profiles, with approximately 10 hours originating from the real human voices of 7 speakers. We have trained three open-source text-to-speech (TTS) systems and two voice conversion systems to demonstrate the practical use cases of this corpus. The corpus is available for research purposes.
提供机构:
Mohamed Bin Zayed University of Artificial Intelligence, UAE
创建时间:
2025-05-27
搜集汇总
数据集介绍
构建方式
ArVoice数据集的构建融合了多种来源的高质量阿拉伯语语音数据,包括专业录制的语音、现有语料库的改进子集以及商业系统生成的高质量合成语音。具体而言,数据集由四部分组成:六位不同人口统计特征的语音艺术家录制的现代标准阿拉伯语(MSA)语音,阿拉伯语语音语料库(ASC)的修改子集,以及两种商业TTS系统生成的合成语音。所有文本均经过严格的预处理和后处理,确保语音与文本的高度一致性,并覆盖了阿拉伯语中的全部音素和字符。
使用方法
ArVoice数据集适用于多种语音相关任务,包括多说话者语音合成(TTS)、语音转换(VC)、语音识别(ASR)以及基于语音的变音符号恢复。研究人员可以通过公开链接获取ASC和合成语音部分,而专业录制的子集需在签署数据使用协议后获取。数据集的使用案例包括训练开源TTS和语音转换系统,展示了其在提升语音合成自然度和语音转换效果方面的潜力。此外,合成语音部分可用于数据增强,进一步提升模型的泛化能力。
背景与挑战
背景概述
ArVoice是由Mohamed Bin Zayed人工智能大学的研究团队于2025年推出的多说话者阿拉伯语语音合成数据集,旨在解决现代标准阿拉伯语(MSA)语音资源匮乏的问题。该数据集包含83.52小时的语音数据,涵盖11种声音,其中7种为真人录音,4种为商业系统合成的语音。ArVoice不仅支持语音合成任务,还可用于语音转换、深度伪造检测等研究。其创新性在于提供了完整的音标标注文本,解决了阿拉伯语中因缺少音标导致的发音歧义问题,显著提升了语音合成的自然度和准确性。
当前挑战
ArVoice面临的挑战主要包括两方面:在领域问题方面,阿拉伯语作为中低资源语言,现有语音数据集多来自新闻、播客等噪声环境,且缺乏音标标注,导致语音合成质量受限;在构建过程中,数据收集面临真人录音成本高、音标标注复杂等难题,同时需平衡数据规模与质量。此外,如何有效利用合成语音进行数据增强,以及确保多说话者语音的多样性和一致性,也是构建过程中的关键挑战。
常用场景
经典使用场景
ArVoice数据集作为现代标准阿拉伯语(MSA)的多说话人语音合成语料库,其经典使用场景主要集中在多说话人文本到语音(TTS)合成和语音转换(VC)任务。通过提供带有完整标注的转录文本和多样化的说话人语音样本,该数据集为研究人员开发高质量的阿拉伯语语音合成模型提供了重要支持。此外,其包含的合成语音部分也为数据增强和语音转换研究提供了丰富的资源。
解决学术问题
ArVoice数据集解决了阿拉伯语语音合成领域中的多个关键学术问题。首先,它填补了现代标准阿拉伯语高质量语音数据集的空白,特别是针对多说话人场景。其次,通过提供带有完整标注的转录文本,该数据集显著改善了语音合成中因缺乏标注导致的发音不准确问题。此外,其多样化的说话人样本和合成语音资源为语音转换和数据增强研究提供了新的可能性。
实际应用
在实际应用中,ArVoice数据集为阿拉伯语语音合成技术的商业化落地提供了重要支持。例如,基于该数据集训练的TTS模型可以用于开发阿拉伯语语音助手、有声读物和自动语音应答系统。其语音转换功能则可用于个性化语音合成和语音克隆等场景。此外,该数据集还可用于阿拉伯语语音识别系统的开发和优化。
数据集最近研究
最新研究方向
随着语音合成技术的快速发展,阿拉伯语作为中低资源语言在语音合成领域面临数据稀缺的挑战。ArVoice数据集的推出为阿拉伯语语音合成研究提供了重要支持,其最新研究方向主要集中在多说话人语音合成、语音转换以及基于深度学习的音素恢复技术。该数据集不仅包含专业录制的多说话人语音,还整合了高质量的合成语音,为语音合成的数据增强和跨说话人语音转换提供了丰富资源。前沿研究利用该数据集探索了端到端语音合成模型的性能优化,特别是在处理阿拉伯语特有的音标符号(diacritics)方面取得了显著进展。此外,ArVoice还被用于语音伪造检测等新兴领域的研究,进一步拓展了其应用范围。该数据集的发布为阿拉伯语语音技术的研究和开发奠定了坚实基础,推动了该领域的技术创新和应用落地。
相关研究论文
- 1ArVoice: A Multi-Speaker Dataset for Arabic Speech Synthesis Mohamed Bin Zayed University of Artificial Intelligence, UAE · 2025年
以上内容由遇见数据集搜集并总结生成


