Joint-Variant ZhuYin dataset
收藏github2024-04-16 更新2024-05-31 收录
下载链接:
https://github.com/vscv/JVZY-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
建立注音符號專用的深度模型訓練集,可供Image-to-Image模型的訓練,可將輸入影像中的注音符號過濾去除。全球至少有22億人面臨視覺障礙的問題(WHO 2019),因人口老齡化與生活方式的改變,也致使視障人數逐年增加。而台灣則有約4萬6千名視障人口(伊甸社會福利基金會)。本計畫將學童之課內、外讀物轉換成文字讀本時,能減少OCR對注音文本的辨識錯誤率,因此減少後續人工逐字檢查、重新繕打的工作量,提高自動導讀、有聲書與電子書的製作效率。使視障孩子能夠閱讀與同齡孩子相同的書籍資源,進而阻絕視障生的學習弱勢,協助導向正常社交和人際關係。
Establish a specialized deep model training dataset for Zhuyin Fuhao (Bopomofo), which can be used for training Image-to-Image models to filter and remove Zhuyin Fuhao from input images. Globally, at least 2.2 billion people face visual impairment issues (WHO 2019), and due to population aging and lifestyle changes, the number of visually impaired individuals is increasing annually. In Taiwan, there are approximately 46,000 visually impaired individuals (Eden Social Welfare Foundation). This project aims to reduce the error rate of OCR in recognizing Zhuyin text when converting children's in-class and extracurricular reading materials into text-based formats, thereby reducing the subsequent workload of manual character-by-character checking and retyping, and improving the efficiency of producing automated reading guides, audiobooks, and e-books. This will enable visually impaired children to access the same book resources as their peers, thereby mitigating the learning disadvantages faced by visually impaired students and assisting them in achieving normal social interactions and relationships.
创建时间:
2022-09-17
原始信息汇总
数据集概述
Joint-Variant ZhuYin dataset for training Image-to-Image networks (JVZYv2)
- 目的: 建立用于Image-to-Image网络训练的注音符号专用深度模型训练集,用于过滤和去除输入影像中的注音符号。
- 应用场景: 通过减少OCR对注音文本的辨識錯誤率,提高自動導讀、有聲書與電子書的製作效率,帮助视障儿童阅读。
- 技术细节: 使用3+3层autoencoder架構进行可行性示範,支持其他如GAN或U-net的Image-to-Image网络架构。
- 模型示例: Simple_encoder模型,具有多个卷积层和池化层,总参数约58,067个。
Joint-Vertic ZhuYin dataset for object detection and image inpainting (JVZYv1)
- 目的: 建立用于物体检测和图像修复的注音符号专用深度模型训练集,用于检测注音符号位置并抹除。
- 应用场景: 通过物体检测模型定位注音符号,使用图像修复技术抹除注音区域,提高OCR的准确性。
- 技术细节: 提供注音符号的检测模型和训练集,用于量化旁註注音对OCR的影响。
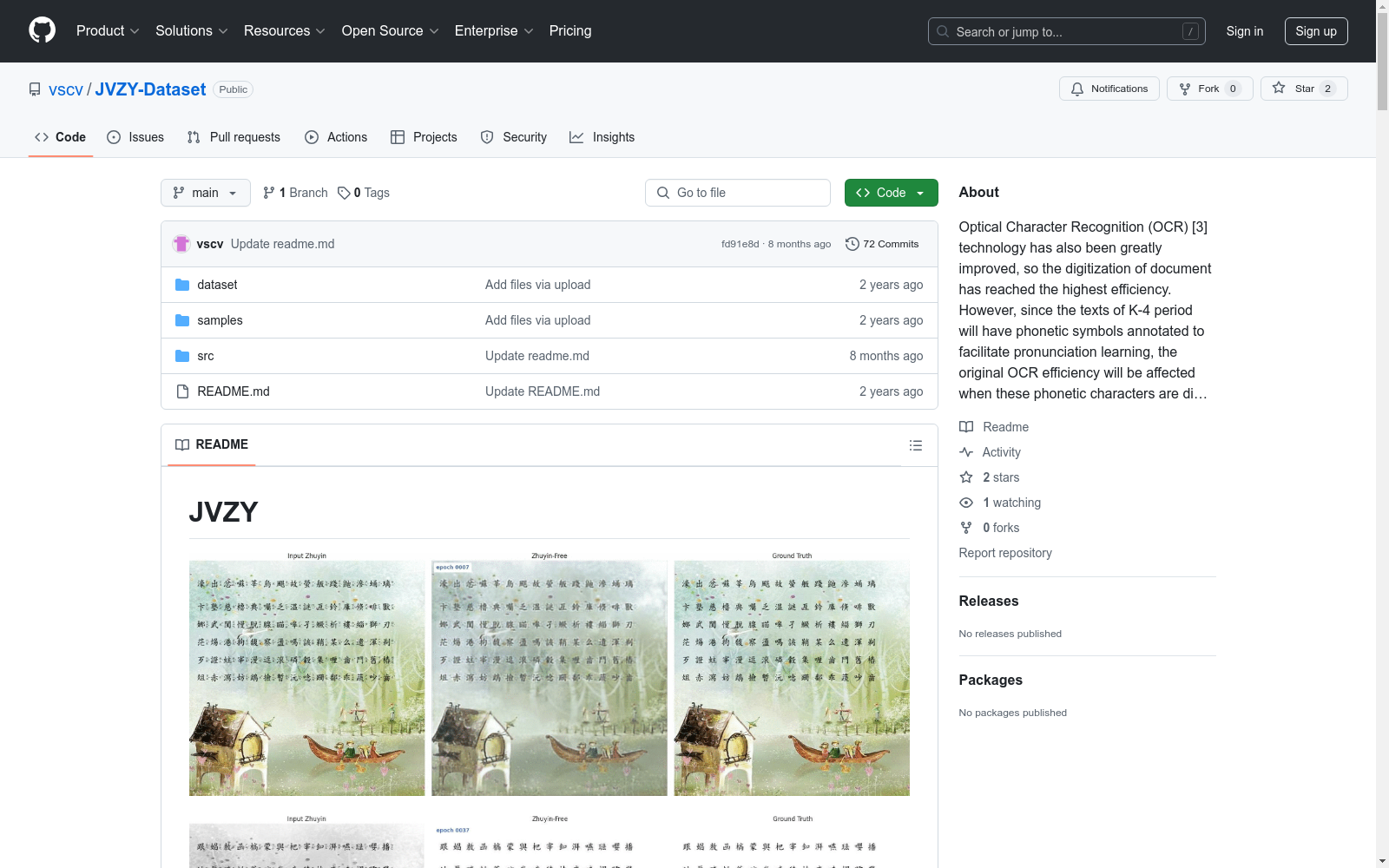
数据集样本
- JVZYv2: 提供多张示例图像,展示输入影像、模型输出无注音影像及无旁註之ground truth影像的对比。
- JVZYv1: 提供图像展示旁註注音对OCR的影响及注音符号检测的工作流程。
引用信息
- 暂无具体引用信息,待定。
搜集汇总
数据集介绍
构建方式
Joint-Variant ZhuYin dataset(JVZY)的构建旨在解决注音符号对光学字符识别(OCR)技术的干扰问题。该数据集通过收集和处理包含注音符号的图像,构建了一个专门用于训练Image-to-Image网络的训练集。数据集的构建过程中,首先采集了大量带有注音符号的文本图像,随后通过图像处理技术生成对应的注音符号位置标注,以便于后续模型的训练和验证。
使用方法
JVZY数据集可用于训练和验证Image-to-Image网络模型,特别是那些旨在去除图像中注音符号的模型。使用该数据集时,用户可以采用如GAN、U-net等深度学习架构,通过输入带有注音符号的图像,训练模型输出去除注音符号后的清晰文本图像。数据集的标注信息可用于监督学习,确保模型能够准确识别并去除注音符号,从而提高OCR系统的识别准确率。
背景与挑战
背景概述
Joint-Variant ZhuYin dataset(JVZY)是由一支专注于视觉障碍辅助技术的团队创建的,旨在解决注音符号对光学字符识别(OCR)技术的干扰问题。该数据集的创建背景源于全球视觉障碍人口的增加,尤其是台湾地区约有4.6万名视障者。JVZY数据集的核心研究问题是如何通过图像到图像的深度学习模型,有效去除扫描图像中的注音符号,从而提高OCR的准确性,减少后续人工校对的工作量。该数据集的开发不仅有助于视障儿童的阅读辅助,还对提升有声书和电子书的制作效率具有重要意义。
当前挑战
JVZY数据集面临的挑战主要集中在两个方面:一是如何有效去除注音符号的同时保留图像中的其他信息,这需要高精度的图像处理技术;二是构建过程中,如何生成足够多样化的注音符号样本,以确保模型在不同场景下的泛化能力。此外,由于注音符号的多样性和复杂性,模型在处理不同字体、大小和位置的注音符号时,可能会遇到识别和去除的困难。这些挑战不仅影响了模型的性能,也对数据集的构建和模型的训练提出了更高的要求。
常用场景
经典使用场景
Joint-Variant ZhuYin dataset(JVZY)主要用于训练Image-to-Image网络,特别是针对注音符号的去除任务。该数据集通过提供包含注音符号的图像,使得模型能够学习如何有效地从图像中过滤掉这些符号,从而提高后续OCR(光学字符识别)的准确性。这一经典场景在教育领域尤为重要,尤其是在为视障学生制作有声书和电子书时,能够显著减少OCR对注音文本的误识别,提升文本转换的效率和准确性。
解决学术问题
JVZY数据集解决了在处理包含注音符号的文本图像时,OCR技术常面临的识别错误问题。由于注音符号的存在,OCR系统往往难以准确识别基础文字,导致输出文本中出现乱码或错误。通过使用JVZY训练的模型,可以有效去除注音符号,从而提高OCR的识别准确率,这对于学术研究中需要高精度文本识别的场景具有重要意义,尤其是在教育资源数字化和无障碍阅读领域。
实际应用
在实际应用中,JVZY数据集主要用于改善视障学生的阅读体验。通过去除教材和读物中的注音符号,可以减少OCR的误识别,使得转换后的文本更加清晰和准确,便于制作有声书和电子书。此外,该数据集的应用还可以扩展到其他需要高精度文本识别的场景,如图书馆的数字化项目、历史文献的数字化保存等,从而在多个领域提升文本处理的效率和质量。
数据集最近研究
最新研究方向
近年来,Joint-Variant ZhuYin dataset在图像处理领域引起了广泛关注,特别是在图像到图像转换和光学字符识别(OCR)优化方面。该数据集通过提供注音符号的专用训练集,推动了深度学习模型在去除图像中注音符号的应用,从而显著提升了OCR系统的准确性。这一研究方向不仅解决了视障儿童阅读材料转换中的技术瓶颈,还为全球视障群体提供了更高效的阅读解决方案。此外,该数据集的应用还扩展到了图像修复和对象检测领域,展示了其在多模态数据处理中的潜力。
以上内容由遇见数据集搜集并总结生成


