dac-research/longbench_synthetic_v4
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/dac-research/longbench_synthetic_v4
下载链接
链接失效反馈官方服务:
资源简介:
LongBench Synthetic V4是一个包含多个子集的数据集,主要用于长文本处理任务。数据集包括longbench_v2_multidoc_qa、longbench_v2_singledoc_qa、loogle_longdep_qa、loogle_shortdep_qa和loogle_summarization五个子集,每个子集都有训练集和验证集。数据集统计信息显示,各子集在唯一上下文数量、样本行数和上下文长度分布上有所不同,适用于不同长度的文本处理任务。
LongBench Synthetic V4 is a dataset comprising multiple subsets, primarily designed for long-text processing tasks. The dataset includes five subsets: longbench_v2_multidoc_qa, longbench_v2_singledoc_qa, loogle_longdep_qa, loogle_shortdep_qa, and loogle_summarization, each with training and validation splits. Statistical information indicates variations in the number of unique contexts, sample rows, and context length distributions across subsets, making it suitable for different lengths of text processing tasks.
提供机构:
dac-research
搜集汇总
数据集介绍
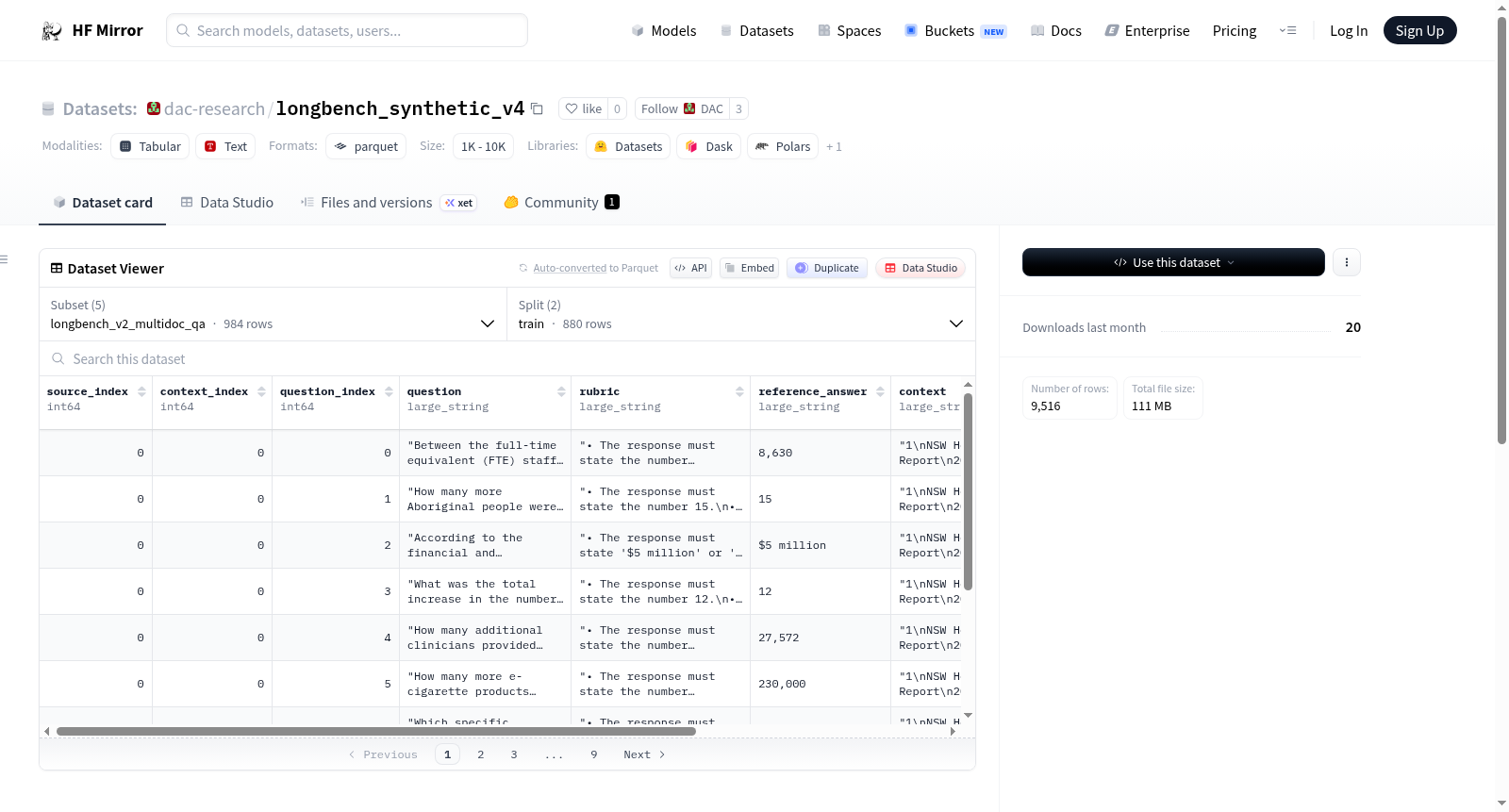
构建方式
LongBench Synthetic V4数据集由Reiss Koh于2026年4月构建,基于Gemini-3-Flash-Preview模型生成。该数据集整合了五个子集,涵盖多文档问答、单文档问答、长依赖问答、短依赖问答及摘要生成任务。每个子集均划分为训练集和验证集,以Parquet格式存储。构建过程中,通过精心设计的提示模板引导模型生成高质量的合成样本,确保上下文多样性。统计显示,数据集包含984个独特的上下文,衍生出9516个样本行,上下文长度从8K tokens到超过128K tokens不等,中位数长度在17K至75K tokens之间,覆盖广泛的文本长度范围。
特点
该数据集的核心特点在于其卓越的长上下文覆盖能力,大量样本的上下文长度超过32K tokens,尤其在多文档和单文档问答子集中,部分样本可达数百万tokens,为评估模型在超长序列上的表现提供了严苛的测试基准。数据呈现高度多样性,每个子集拥有数十至数百个独特上下文,避免了重复模式。此外,所有样本均经过严格的统计分布验证,确保在8K、16K、32K、64K和128K等关键长度阈值的样本分布均衡,从而支持对大语言模型长距离依赖捕捉与信息整合能力的系统化评测。
使用方法
使用时,可通过HuggingFace Datasets库加载指定子集。例如,加载多文档问答子集:`load_dataset('longbench_synthetic_v4', 'longbench_v2_multidoc_qa', split='train')`。数据集提供训练和验证两种划分,方便模型调优与效果评估。由于样本上下文极长,建议采用支持长序列的模型架构(如FlashAttention)进行训练或推理。同时,根据数据统计,可依据任务需求选择特定长度范围的子集进行针对性测试,例如利用loogle_summarization子集评估摘要能力,或使用longbench_v2_multidoc_qa挑战模型的多文档联合推理能力。
背景与挑战
背景概述
随着大规模语言模型在长文本理解任务上的广泛应用,构建能够评测模型在超长上下文场景下综合能力的基准数据集成为自然语言处理领域的前沿课题。LongBench Synthetic V4由Reiss Koh于2026年4月创建,借助Gemini-3-Flash-Preview模型生成,旨在系统性地评估模型在多文档问答、单文档问答、长程依赖问答及摘要生成等维度的长文本处理能力。该数据集涵盖超过9500个样本,上下文长度从8千词元跨越至近百万词元,填补了现有基准在高难度长上下文推理任务上的评测空白,为长文本理解研究提供了具有挑战性的标准化评估平台。
当前挑战
该数据集所应对的领域核心挑战在于,现有语言模型在长文本场景中常面临信息丢失、长距离依赖捕获困难及多文档融合推理能力不足等问题,尤其在上下文超过64K词元时性能显著下降。数据集构建过程中同样面临多重挑战:需确保生成样本的多样性与真实性,避免合成数据引入噪音;需精细控制不同子集间的难度分布与上下文长度梯度,以构造具有区分度的评测内容;还需平衡各子集样本规模,避免数据偏斜导致评测失真,这些因素共同使得该数据集的构建成为一项复杂的系统工程。
常用场景
经典使用场景
在长文本理解与推理研究领域,LongBench Synthetic V4 数据集以其精心设计的多文档问答、单文档问答及摘要生成等子集,成为评估大语言模型长程依赖建模能力的标杆。该数据集涵盖从数千至近百万词元的语境长度,能精准考察模型在长距离信息检索、跨文档语义整合及长文本内容概括等经典任务上的表现。研究者通常借此集合并行探测模型在不同文档数量和依赖距离下的鲁棒性,从而系统化地衡量其上下文处理的极限与短板。
实际应用
在实际应用中,该数据集模拟了诸如法律合同审查、医学文献综合分析、多轮对话历史回溯及金融报告跨章节问答等高难度长文本处理场景。得益于其多源异构的子集设计,企业级AI系统可据此检验其对长文档知识库检索增强生成(RAG)管线的响应质量,以及处理包含大量上下文信息的用户查询时的准确性与连贯性,从而为构建可靠的智能助手、知识管理系统和自动化文档分析工具提供关键性能验证。
衍生相关工作
LongBench Synthetic V4 的问世催生了一系列衍生工作,包括针对其子集设计的长上下文增强训练策略、基于检索与压缩的混合推理方法,以及专门优化长距离注意力机制的模型架构改进。许多研究者进一步将其与LoRA微调、长程记忆网络或稀疏注意力机制结合,开发出适应超长文本的新型基准评估协议。此外,该数据集也常被用作在长文本摘要与多文档问答任务中对比不同长度缩放方法优劣的标准测试平台,持续推动相关领域向前演进。
以上内容由遇见数据集搜集并总结生成


