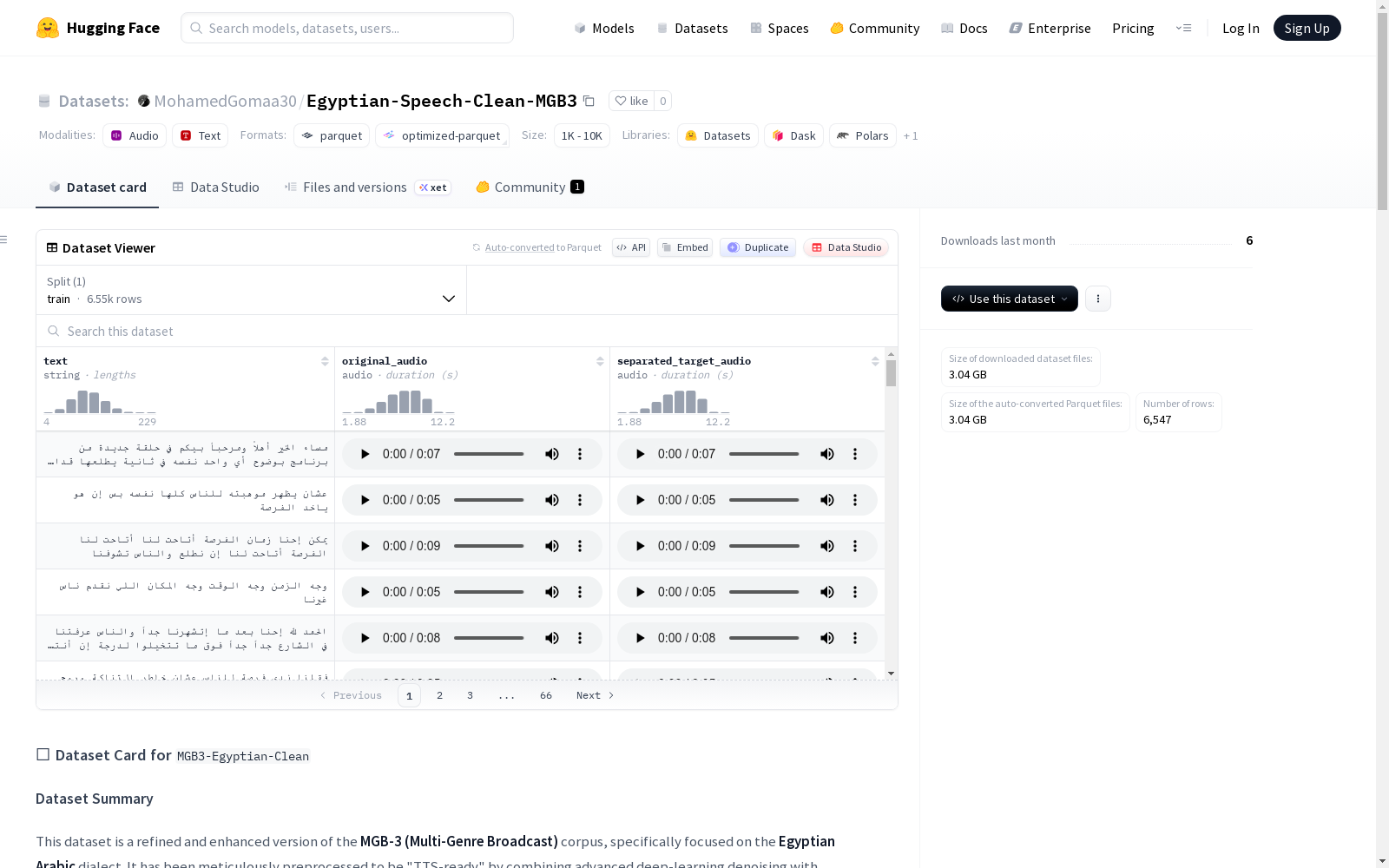
Egyptian-Speech-Clean-MGB3
收藏数据集概述:MGB3-Egyptian-Clean
数据集摘要
本数据集是 MGB-3(多类型广播) 语料库的一个精炼和增强版本,专门针对 埃及阿拉伯语 方言。它经过细致的预处理,通过结合先进的深度学习去噪和自定义的语言文本规范化,使其成为“即用于TTS”的数据集。
数据处理流程
为确保生成性语音任务(如VITS或MMS微调)的最高质量,所有6500个样本均应用了以下步骤:
1. 音频增强(DeepFilterNet 3)
使用 DeepFilterNet 3 进行高速、高保真度的噪声抑制。此阶段去除了背景嘶嘶声、嗡嗡声和非平稳噪声,同时保留了埃及说话者声音的自然特征。
- 目标采样率: 16,000 Hz
- 去噪引擎: 采用等效矩形带宽掩蔽的深度信号滤波。
2. 埃及语文本规范化(语言学)
标准阿拉伯语NLP工具在处理方言特定的数字和表达时常有不足。我们实现了一个自定义的 埃及阿拉伯语规范化器,将非语言标记转换为口语化的“Masri”词汇。这对于文本到语音的一致性至关重要。 规范化器的主要特性:
- 数字转文字: 将数字转换为埃及形式(例如,3 → "تلاتة" 而非 "ثلاثة")。
- 货币: 支持埃及镑、美元和欧元,并遵循埃及复数规则(例如,"$5" → "خمسة دولار")。
- 时间与日期: 将“10:30”规范化为“عشرة ونص”,并将日期规范化为埃及序数月份。
- 数学符号: 处理百分比("في المية")和范围("من... لحد")。
数据集模式
数据集中的每一行包含:
text: 规范化的埃及阿拉伯语转录文本(语音转文字)。original_audio: 原始的MGB-3音频片段。separated_target_audio: 经过清理、去噪的16kHz音频,针对训练进行了优化。
数据集特征与规模
- 特征:
text(dtype: string)original_audio(dtype: audio, sampling_rate: 16000)separated_target_audio(dtype: audio, sampling_rate: 16000)
- 数据拆分:
train拆分:包含 6547 个样本,数据大小 3134731085 字节。
- 下载大小: 3035093603 字节
- 数据集总大小: 3134731085 字节
标签与元数据
- 语言:
ar-EG(arz) - 任务:
text-to-speech,automatic-speech-recognition - 方言:
Egyptian - 处理:
Denoised,Normalized
引用与归属
1. 源仓库(Mohamed Rashad)
本数据集是Mohamed Rashad所托管数据的清理版本,需致谢其收集和托管阿拉伯语MGB-3片段的前期工作:
Mohamed Rashad. (2023). MGB-3 Arabic Dataset for Speech Recognition and Dialect Identification. 地址:https://huggingface.co/datasets/MohamedRashad/MGB-3-Arabic
2. 原始MGB-3挑战(学术引用)
MGB-3数据集最初作为多类型广播挑战的一部分发布。埃及方言部分的标准引用如下: bibtex @inproceedings{mgb3-challenge, title={The third Multi-Genre Broadcast (MGB-3) Arabic Challenge: Recognition and Dialect Identification of Arabic Multi-Genre Broadcast Data}, author={Ali, Ahmed and Bell, Peter and Glass, James and Mabrok, Mohamed and Magdy, Walid and Mubarak, Hamdy and Renals, Steve and Vogel, Stephan}, booktitle={2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU)}, pages={611--618}, year={2017}, organization={IEEE} }
3. 软件归属(DeepFilterNet)
bibtex @inproceedings{Schrter2022DeepFilterNet2, title={DeepFilterNet2: Real-Time Speech Enhancement on Mobile Devices for Full-Band Audio}, author={Hendrik Schr{"o}ter and Alberto N. Escalante-B. and Tobias Rosenkranz and Andreas Maier}, booktitle={ICASSP 2022}, year={2022} }