Cnam-LMSSC/vibravox
收藏Hugging Face2025-11-07 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Cnam-LMSSC/vibravox
下载链接
链接失效反馈官方服务:
资源简介:
VibraVox数据集是一个通用的法语语音数据集,通过身体传导传感器捕获。该数据集可用于多种音频机器学习任务,包括自动语音识别(ASR)、音频带宽扩展(BWE)、说话人验证(SPKV)和语音克隆等。数据集包含四个子集,分别针对不同的任务场景,涵盖了从干净语音到噪声环境下的语音数据。数据集还提供了详细的传感器技术信息和数据字段描述,适用于研究和开发基于身体传导语音分析的通信系统。
The VibraVox dataset is a general purpose audio dataset of French speech captured with body-conduction transducers. This dataset contains four subsets tailored for different tasks and environments, such as clean speech, noisy audio, speechless clean, and speechless noisy. Each subset includes six columns of audio data corresponding to five different body-conduction sensors and a standard headset microphone. The dataset supports various audio machine learning tasks, including automatic speech recognition, audio bandwidth extension, speaker verification, and voice cloning, among others.
提供机构:
Cnam-LMSSC
原始信息汇总
数据集概述
基本信息
- 数据集名称: VibraVox
- 语言: 法语
- 许可证: CC BY 4.0
- 多语言性: 单语种
- 数据集大小: 100K < n < 1M
任务类别
- 音频到音频
- 自动语音识别
- 音频分类
- 文本到语音
任务ID
- 说话人识别
数据集配置
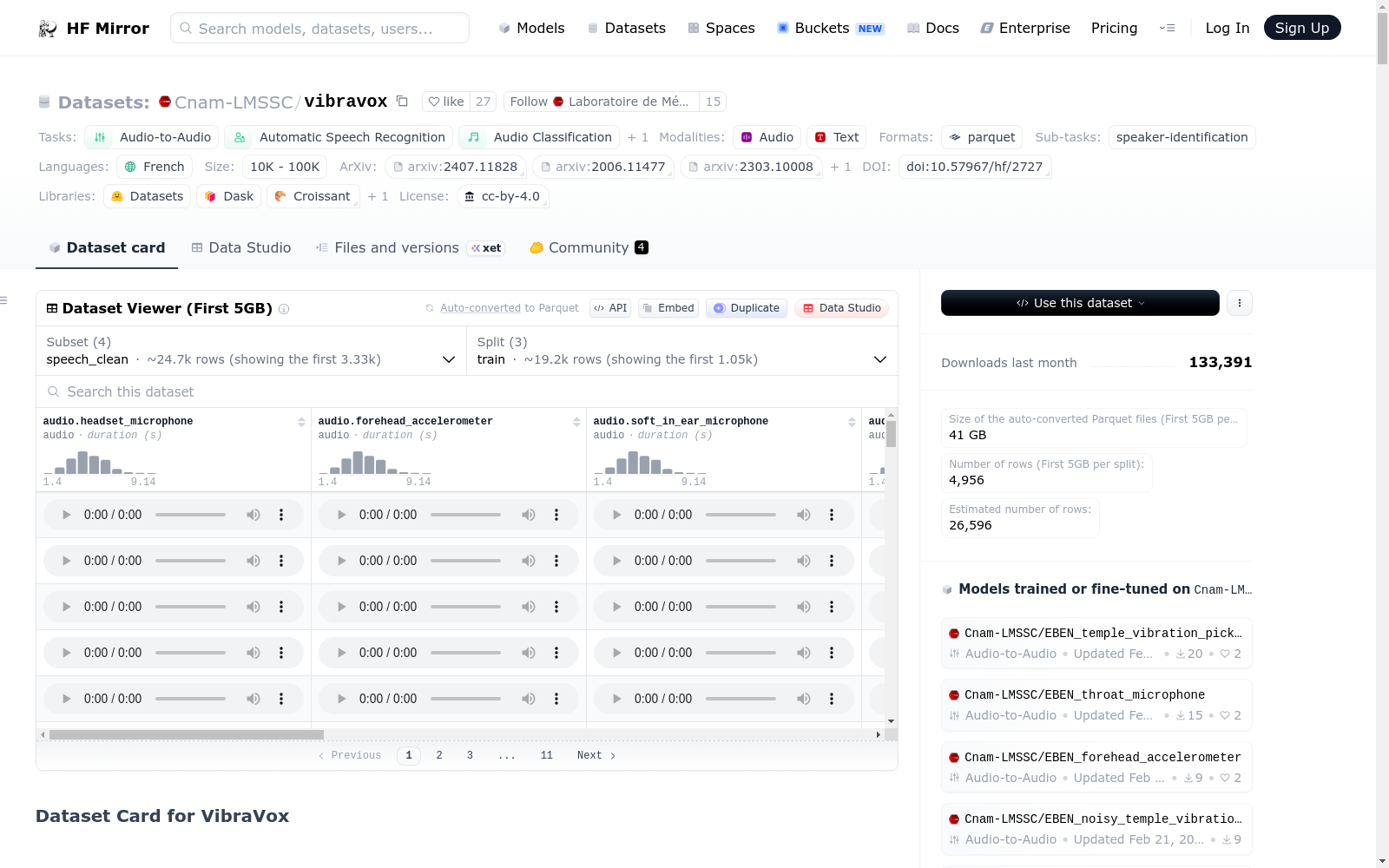
配置: speech_clean
- 特征:
audio.headset_microphone: 音频audio.forehead_accelerometer: 音频audio.soft_in_ear_microphone: 音频audio.rigid_in_ear_microphone: 音频audio.temple_vibration_pickup: 音频audio.throat_microphone: 音频gender: 字符串speaker_id: 字符串sentence_id: 整数duration: 浮点数raw_text: 字符串normalized_text: 字符串phonemized_text: 字符串
- 分割:
train: 20981个样本, 109247789463字节validation: 2523个样本, 12896618986字节test: 3064个样本, 15978915932字节
- 下载大小: 136955541722字节
- 数据集大小: 138123324381字节
配置: speech_noisy
- 特征:
audio.headset_microphone: 音频audio.forehead_accelerometer: 音频audio.soft_in_ear_microphone: 音频audio.rigid_in_ear_microphone: 音频audio.temple_vibration_pickup: 音频audio.throat_microphone: 音频gender: 字符串speaker_id: 字符串sentence_id: 整数duration: 浮点数raw_text: 字符串normalized_text: 字符串phonemized_text: 字符串
- 分割:
train: 1220个样本, 6522270562字节validation: 132个样本, 706141725字节test: 175个样本, 937186370字节
- 下载大小: 8156941693字节
- 数据集大小: 8165598657字节
配置: speechless_clean
- 特征:
audio.headset_microphone: 音频audio.forehead_accelerometer: 音频audio.soft_in_ear_microphone: 音频audio.rigid_in_ear_microphone: 音频audio.temple_vibration_pickup: 音频audio.throat_microphone: 音频gender: 字符串speaker_id: 字符串duration: 浮点数
- 分割:
train: 149个样本, 9285823162字节validation: 18个样本, 1121767128字节test: 21个样本, 1308782974字节
- 下载大小: 10651939843字节
- 数据集大小: 11716373264字节
配置: speechless_noisy
- 特征:
audio.headset_microphone: 音频audio.forehead_accelerometer: 音频audio.soft_in_ear_microphone: 音频audio.rigid_in_ear_microphone: 音频audio.temple_vibration_pickup: 音频audio.throat_microphone: 音频gender: 字符串speaker_id: 字符串duration: 浮点数
- 分割:
train: 149个样本, 24723250192字节validation: 18个样本, 2986606278字节test: 21个样本, 3484522468字节
- 下载大小: 30881658818字节
- 数据集大小: 31194378938字节
数据集结构
子集
- speech_clean: 说话人朗读法语维基百科的句子,适用于多种任务的训练。
- speech_noisy: 说话人在嘈杂环境中朗读法语维基百科的句子,主要用于测试基于
speech_clean训练的系统。 - speechless_clean: 佩戴设备的人在完全安静的环境中保持沉默,但可以自由移动身体和面部,适用于生成包含生理噪声的合成数据集。
- speechless_noisy: 佩戴设备的人在嘈杂环境中保持沉默,适用于使用身体传导传感器捕获的噪声进行数据增强。
分割
所有子集都包含训练、验证和测试三个分割,比例为80% / 10% / 10%,且每个分割中的说话人没有重叠。
数据字段
- 通用字段:
audio.headset_microphone: 头戴式麦克风录制的音频audio.forehead_accelerometer: 额头加速度传感器录制的音频audio.soft_in_ear_microphone: 软耳塞嵌入式麦克风录制的音频audio.rigid_in_ear_microphone: 硬耳塞嵌入式麦克风录制的音频audio.temple_vibration_pickup: 颞骨振动传感器录制的音频audio.throat_microphone: 喉部麦克风录制的音频gender: 说话人性别speaker_id: 说话人加密IDduration: 音频时长(秒)
- 额外字段 (仅适用于
speech_clean和speech_noisy子集):sentence_id: 朗读句子的IDraw_text: 音频段文本(带标点符号)
搜集汇总
数据集介绍
背景与挑战
背景概述
VibraVox is a French speech dataset with 45.62 hours of audio captured via 6 body-conduction sensors, supporting tasks like ASR and SPKV. It includes 4 subsets for different acoustic conditions and is gender-balanced with 97 female and 91 male speakers.
以上内容由遇见数据集搜集并总结生成


