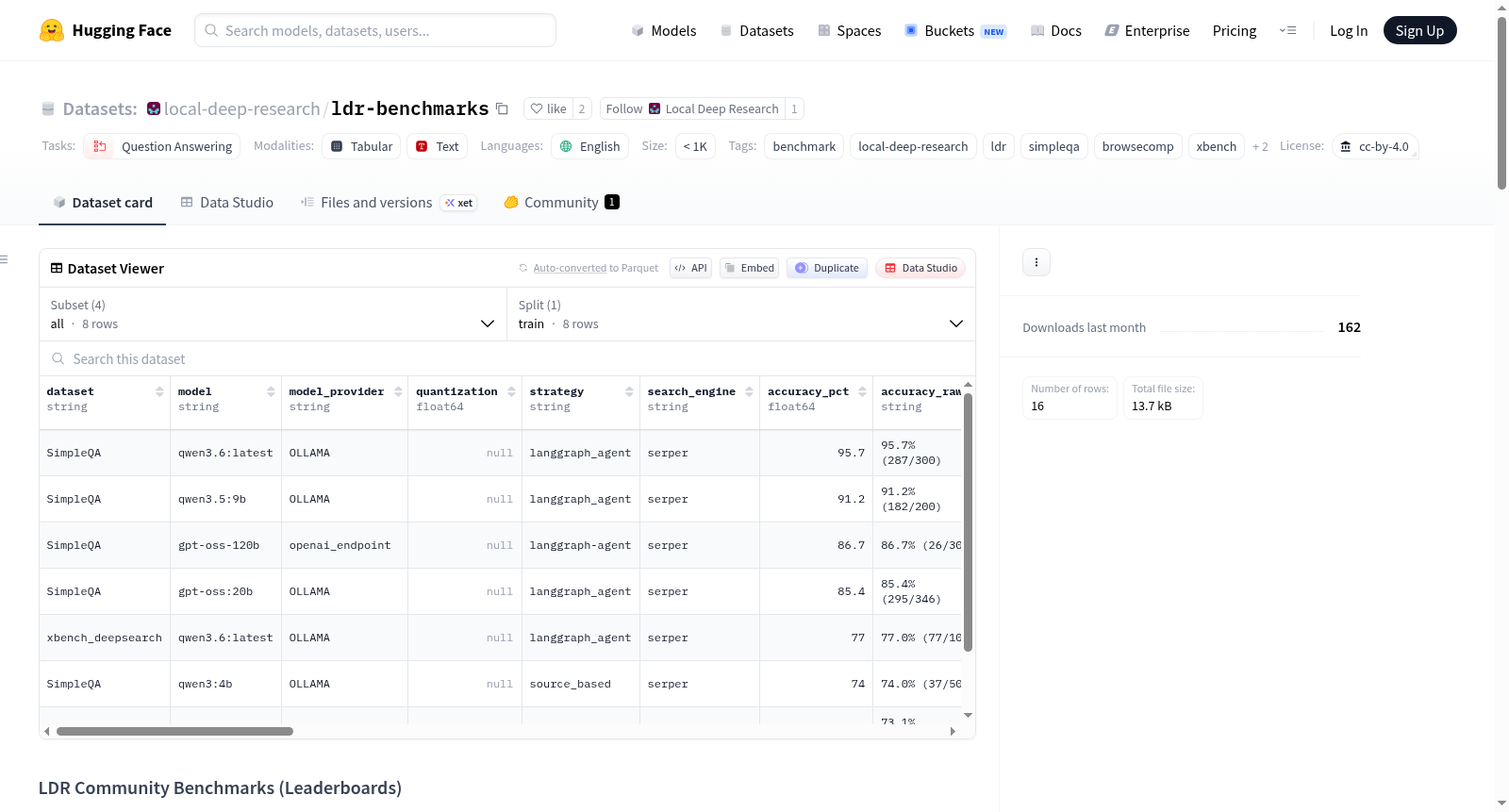
ldr-benchmarks
收藏LDR Community Benchmarks 数据集概述
数据集基本信息
- 数据集名称:LDR Community Benchmarks (Leaderboards)
- 发布者:Local Deep Research (LDR) community
- 托管平台:Hugging Face
- 许可证:Creative Commons Attribution 4.0 International (CC BY 4.0)
- 任务类别:问答
- 语言:英语
- 标签:benchmark, local-deep-research, ldr, simpleqa, browsecomp, xbench, rag, search
- 数据规模:n<1K
- 数据源仓库:https://github.com/LearningCircuit/ldr-benchmarks
数据集内容与目的
本数据集是Local Deep Research (LDR)社区基准测试运行的聚合排行榜,包含针对SimpleQA、BrowseComp和xbench-DeepSearch三个基准的测试结果。数据集仅包含聚合后的CSV排行榜文件,原始提交的YAML文件(包含配置详情、注释等)存储在GitHub仓库中。
包含的基准测试
- SimpleQA
- 来源:OpenAI
- 许可证:MIT License (https://github.com/openai/simple-evals/blob/main/LICENSE)
- 特点:允许在GitHub的原始YAML中包含完整的逐题示例。
- BrowseComp
- 来源:OpenAI
- 特点:使用加密数据集和验证字符串。仅接受聚合指标(原始YAML中不允许包含逐题示例)。
- 参考:BrowseComp论文 (https://cdn.openai.com/pdf/5e10f4ab-d6f7-442e-9508-59515c65e35d/browsecomp.pdf) 和 openai/simple-evals (https://github.com/openai/simple-evals)。
- xbench-DeepSearch
- 来源:xbench团队
- 特点:使用加密数据集。仅接受聚合指标(原始YAML中不允许包含逐题示例)。
- 参考:xbench-ai/xbench-evals (https://github.com/xbench-ai/xbench-evals)。
注意:禁止以纯文本形式分发BrowseComp和xbench的问题或答案。
数据配置
数据集提供以下配置,可通过Dataset Viewer顶部的下拉菜单切换:
all:所有基准测试的运行结果汇总(默认配置)。simpleqa:仅SimpleQA的运行结果。browsecomp:仅BrowseComp的运行结果。xbench-deepsearch:仅xbench-DeepSearch的运行结果。
数据字段说明
每个CSV行(代表一次基准测试运行)包含以下列:
dataset, model, model_provider, quantization, strategy, search_engine, accuracy_pct, accuracy_raw, correct, total, iterations, questions_per_iteration, avg_time_per_question, total_tokens_used, temperature, context_window, max_tokens, hardware_gpu, hardware_ram, hardware_cpu, evaluator_model, evaluator_provider, ldr_version, date_tested, contributor, notes, source_file。
其中source_file列指向GitHub仓库中的原始YAML文件。
数据使用注意事项
- 数据性质:这是一个社区提交的排行榜,并非受控实验。
- 自报告性质:运行结果由贡献者提交,CI会验证模式并标记明显问题,但运行本身未经独立重新执行。
- 评估偏差:许多提交使用LLM评分器(默认是通过OpenRouter的Claude 3.7 Sonnet),存在不可忽视的错误率。
- 样本量小:许多运行使用50-200个问题,置信区间较宽,行间的小差异通常不显著。
- 时间依赖性:
avg_time_per_question取决于硬件、网络延迟、搜索引擎响应能力和模型服务器负载。 - 数据污染风险:SimpleQA已公开分发,可能出现在某些模型的训练数据中。
- 策略语义漂移:LDR策略在不同版本间会演变,建议比较使用相同
ldr_version的运行。
贡献者
感谢以下贡献者提交基准测试运行:
- LearningCircuit — 6 submissions
- Daniel Petti — 1 submission
- kwhyte7 — 1 submission
引用方式
bibtex @misc{ldr_community_benchmarks, title = {LDR Community Benchmarks}, author = {The Local Deep Research community}, year = {2026}, publisher = {Hugging Face / GitHub}, howpublished = {url{https://huggingface.co/datasets/local-deep-research/ldr-benchmarks}} }