Anonymous1-afk-ops/rubric-grounded-faithfulness-eval
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Anonymous1-afk-ops/rubric-grounded-faithfulness-eval
下载链接
链接失效反馈官方服务:
资源简介:
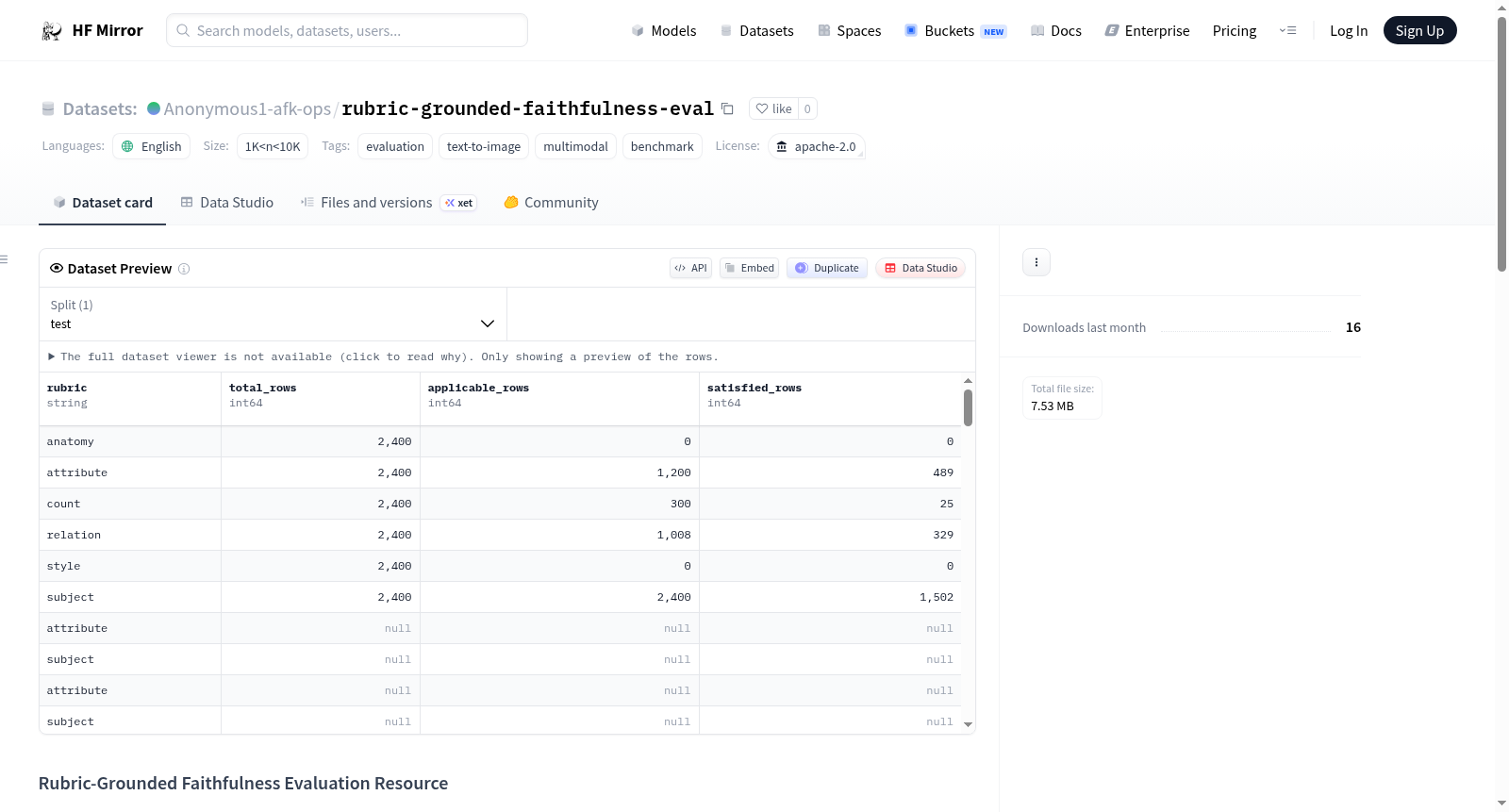
该数据集是一个用于评估AI生成图像忠实度的资源,名为Rubric-Grounded Faithfulness Evaluation Resource。它是为NeurIPS 2026的评估和数据集提交而准备的。数据集包含多个资产,如完整的AIGCIQA2023评分标签、证据点和反事实诊断子集、重新标记的2400张T2I-CompBench人类评估压力测试图像等。但数据集不包含源基准图像或模型权重。数据集的主要用途包括支持AIGCIQA2023的全面分析、证据基础和反事实诊断、跨数据集转移评估等。
This dataset is a resource for evaluating the faithfulness of AI-generated images, named Rubric-Grounded Faithfulness Evaluation Resource. It is prepared for the NeurIPS 2026 Evaluations and Datasets submission. The dataset includes multiple assets such as full-gold AIGCIQA2023 rubric labels, evidence-point and reviewed-counterfactual diagnostic subsets, a relabeled 2400-image T2I-CompBench human-eval stress test, etc. However, the dataset does not include source benchmark images or model weights. The main uses of the dataset include supporting full-gold in-domain analysis on AIGCIQA2023, evidence-grounding and counterfactual diagnostics, cross-dataset transfer evaluation, etc.
提供机构:
Anonymous1-afk-ops
搜集汇总
数据集介绍
构建方式
该数据集源于一篇针对文本生成图像领域忠实性评估的研究,旨在将传统的评分范式转化为基于细粒度标准(rubric)的结构化检验。构建过程首先从AIGCIQA2023基准中提取全量标注,形成完整的rubric标签集作为黄金标准。在此基础上,研究者设计了证据点(evidence-point)与经过审核的反事实(reviewed-counterfactual)诊断子集,以模拟不同层次的评估挑战。此外,对T2I-CompBench中2400张图像的人工评估集进行了重新标注,构建了一个跨数据集的压力测试集。所有标注结果以CSV格式存储,并附带分割文件、参考预测结果以及度量与自助法(bootstrap)统计结果,形成一个层级分明的评估资源包。
特点
该数据集的核心特色在于其以rubric为导向的忠实性评估框架,首次将AI生成图像的评价从单一分数拓展为可解释、可验证的多维度标准检验。它集成了领域内全量黄金标注、诊断性子集与跨数据集迁移测试三种形态,能够支持从内部分析、证据推理到泛化性评估的完整研究链条。每个子集均保留了与原始基准图像相链接的sample_id与image_name字段,确保可追溯性。同时,数据集不包含原始图像或模型权重,仅提供衍生标注与元数据,具备轻量级、高兼容性和便于复用的特点。
使用方法
使用该数据集时,用户需首先从AIGCIQA2023和T2I-CompBench等上游基准获取原始图像资产。随后,通过提供的CSV文件中的sample_id与image_name将标注数据与图像进行关联。数据集附带EVALUATION_CARD.md、data/README.md等文档作为入门指南,建议依序阅读以理解各子集含义、分割规则和评估协议。对于想要复现论文结果或进行新评估的研究者,可利用released metric artifacts与bootstrap摘要进行对照。执行代码另存于独立仓库,需配合OpenReview中的Code URL使用,以实现完整的评估流程。
背景与挑战
背景概述
在生成式人工智能迅猛发展的背景下,文本到图像(Text-to-Image)模型生成的图像内容是否准确反映用户意图,即忠实性(Faithfulness)评估,已成为多模态研究领域的核心课题。2025年,该数据集由一项提交至NeurIPS 2026评估与数据集分会的匿名研究团队创建,旨在解决现有评估方法依赖全局分数而缺乏细粒度可解释性的问题。该资源基于AIGCIQA2023和T2I-CompBench两大基准,通过引入基于评分规则(Rubric-Grounded)的评估框架,系统性地提供了全标注的语义标签、证据点诊断集以及经重标注的2400幅图像压力测试集,为忠实性评估提供了标准化、可复现的评测平台。其影响力在于推动了评估范式从单维分数向结构化检查的转变,并为多模态生成模型的可靠性验证奠定了坚实基础。
当前挑战
该数据集应对的领域挑战在于,传统AIGC忠实性评估依赖整体质量评分或单指标对比,难以捕捉模型输出中细微的语义错误或上下文违背,且人工评估成本高、一致性差;为此,数据集通过构建证据点诊断子集与反事实样本,实现对评估粒度的精细化解构。在构建过程中,面临的挑战包括:从AIGCIQA2023等源基准中提取并标准化标注数据以消除标注偏差,确保跨数据集的标签一致性;对T2I-CompBench的2400幅图像进行人工重标注,需在保持原基准评估结构的同时融入评分规则指导;此外,还需处理上游图像的版权与获取限制,要求使用者单独获取原始图像,增加了数据复现的复杂性。
常用场景
经典使用场景
在文本到图像生成质量评估领域,rubric-grounded-faithfulness-eval数据集为研究者提供了一套基于细粒度评分准则的忠实性评估基准。该数据集的核心使用场景在于评估AI生成图像与文本描述之间的一致性,通过引入结构化评分规则,替代传统单一数值评分,实现更精准、可解释的图像-文本对齐度量。经典应用包括:在AIGCIQA2023基准上开展全金标准域内分析,验证不同评估方法在忠实性维度的表现;利用证据点与反事实诊断子集,探究评估模型对关键细节的捕捉能力;以及通过重标注的T2I-CompBench人类评估集,检验跨数据集迁移时的评估鲁棒性。这些场景共同推动了评估范式从“分数驱动”向“规则驱动”的转变。
解决学术问题
该数据集致力于解决AI生成图像评估中长期存在的忠实性度量缺失问题。传统方法依赖单一质量分数,难以捕获图像与文本间的细微语义偏差。rubric-grounded-faithfulness-eval通过构建结构化评分规则,将评估过程分解为多个可解释的检查项,使研究者能够系统性地诊断忠实性失败模式。其解决的学术问题包括:如何量化生成图像对文本描述中特定实体、属性及空间关系的遵循程度,如何区分整体不忠实与局部细节偏差,以及如何建立可重复、可比较的评估协议。这一工作弥补了现有文本到图像评估基准在忠实性维度上的空白,为后续研究提供了方法论框架和标准化参照,显著提升了评估的科学性和公信力。
衍生相关工作
该数据集催生了一系列围绕规则驱动评估与诊断机制的研究工作。其中,基于证据点的评估方法利用其结构化标注训练模型,学会定位图像中支持忠实性判断的区域,推动了可解释评估的发展。反事实诊断子集激发了针对特定错误模式(如属性绑定失败、空间关系错乱)的对抗性测试框架,提升了评估的鲁棒性。此外,该数据集的跨基准重标注策略被后续工作采纳,用于构建多标准的人类评估集合,促进了评估指标的横向比较。其公开的度量与自助法结果也作为参考基线,出现在多项关于文本到图像忠实性回归与验证工具的研究中,成为该领域方法论创新的重要支撑资源。
以上内容由遇见数据集搜集并总结生成


