Shafa10/ecommerce-faq-llama2-QA
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Shafa10/ecommerce-faq-llama2-QA
下载链接
链接失效反馈官方服务:
资源简介:
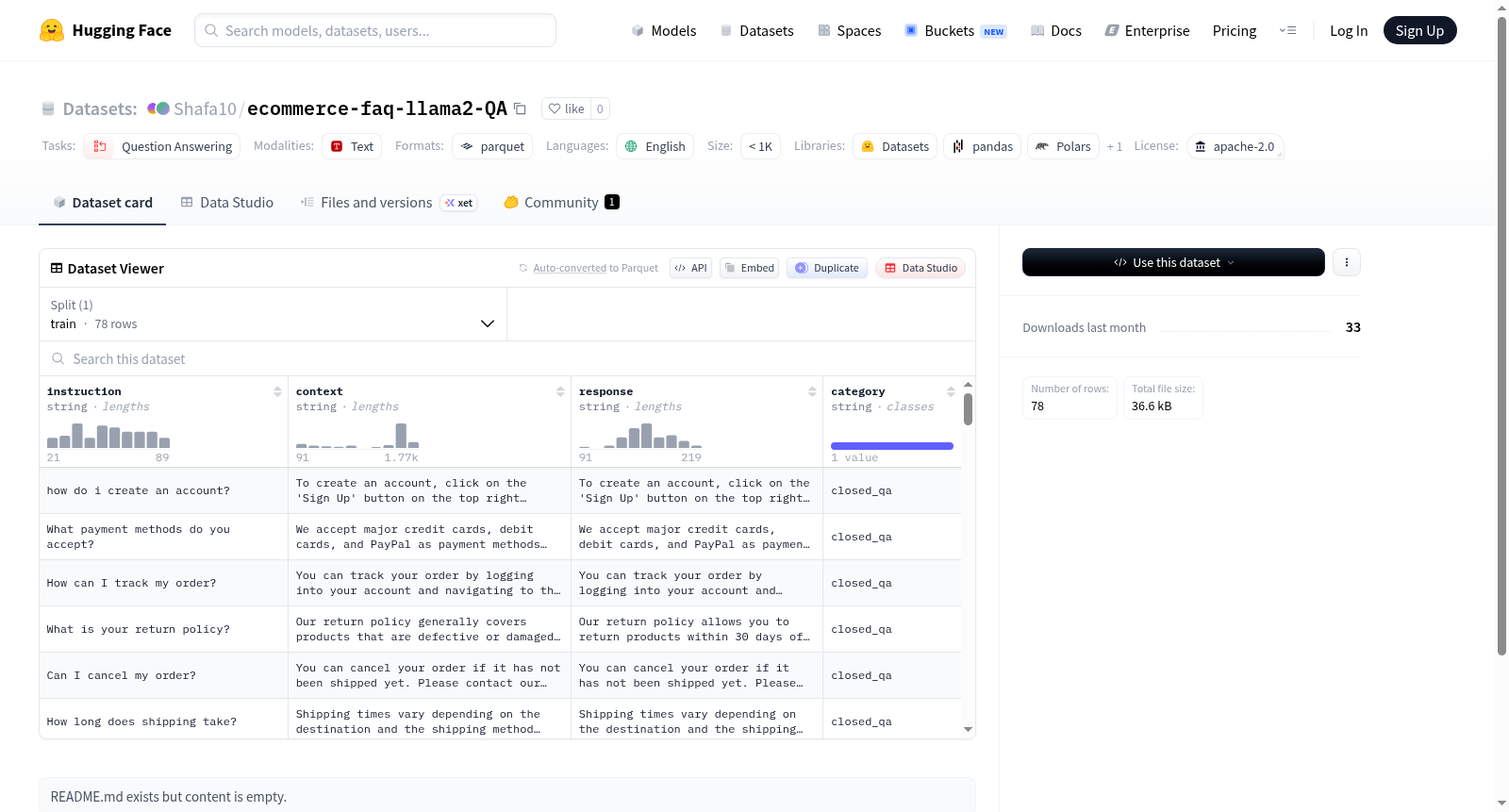
这是一个用于问答任务的英语数据集,包含78个训练样本。数据集特征包括指令(instruction)、上下文(context)、响应(response)和类别(category),所有特征均为文本格式。数据规模较小(小于1K样本),适用于问答模型训练或评估。
This is an English dataset for question-answering tasks, containing 78 training examples. The dataset features include instruction, context, response, and category, all in text format. It is small in scale (less than 1K samples) and suitable for training or evaluating question-answering models.
提供机构:
Shafa10
搜集汇总
数据集介绍
构建方式
在电子商务领域,用户常因商品信息不透明或售后流程复杂而求助智能客服。该数据集以电商场景中的常见问题为核心构建,通过收集78条高频FAQ条目,将每条问题拆解为'指令(instruction)'、'背景上下文(context)'和'标准回复(response)'三部分,并附有'类别(category)'标签以区分主题域。数据采用问答对形式组织,全部以英文撰写,并统一封装为训练集格式,便于直接用于模型微调。
使用方法
使用时可直接将'instruction'字段作为用户查询输入,将'context'字段作为当前会话的补充背景信息,并利用'response'字段作为模型需生成的标准回答进行有监督微调。数据集已预分为单个训练集,用户无需额外拆分,加载后即可基于HuggingFace Transformers库的Trainer或自定义训练流程进行训练。建议在训练时配合同领域的验证数据以更好评估模型在电商FAQ任务上的表现。
背景与挑战
背景概述
随着大型语言模型在自然语言处理领域的迅猛发展,如何高效地将预训练模型适配至垂直行业场景成为研究焦点。ecommerce-faq-llama2-QA数据集于2023年由开源社区构建,基于Meta发布的Llama 2模型,专注于电子商务领域的问答任务。该数据集虽规模极小(仅含78条训练样本),却精准聚焦于电商场景中用户常见问题的指令遵循能力,例如商品咨询、售后政策等。其核心研究问题在于探索低资源条件下,利用少量高质量示例激发大语言模型在特定领域内的应答准确性与实用性。尽管数据集规模有限,但它为电商智能客服的轻量化部署提供了基准参考,推动了大模型在细分商业场景中的落地可能性。
当前挑战
该数据集所解决的领域问题在于如何弥合通用大模型与电商垂直场景间的语义鸿沟,特别是在高频重复性问答中实现精准响应。其首要挑战来自数据稀缺性:仅78个样本难以覆盖电商海量问题变体,易导致模型过拟合或泛化能力不足。构建过程中,需人工设计涵盖不同商品类型与用户意图的指令、上下文与答案三元组,确保样本质量与领域覆盖均衡。此外,标注一致性管理成为难题——多轮对话中隐含的上下文依赖、商品属性动态变化(如库存、价格)均需在静态数据中合理抽象。最终,数据集还需兼顾Apache-2.0许可下的开源合规性,平衡商业敏感信息与学术共享价值。
常用场景
经典使用场景
在电子商务智能客服系统的构建,ecommerce-faq-llama2-QA数据集常被作为微调语言模型的核心语料。该数据集汇集了78条高质量的商品问答对,涵盖商品咨询、购买引导、物流配送等典型电商场景,为模型注入了精准的垂直领域知识。研究者通常基于该数据集对Llama 2等基础模型进行指令微调,使其能够理解电商术语、把握用户意图并输出符合平台规范的应答,从而生成流畅且具有商业价值的对话文本。
解决学术问题
该数据集有效解决了大语言模型在电子商务领域中的领域适配性与知识对齐问题。通用语言模型往往缺乏对商品信息、促销规则及售后流程的细粒度理解,导致其在自然语言响应中频繁产生不准确或无关的答案。通过利用ecommerce-faq-llama2-QA进行微调,研究证实模型能显著提升问答精准度、上下文相关性及商业术语的使用规范性,为低资源垂直场景下的少样本学习提供了可复现的基准与方法论支撑。
实际应用
在真实的商业落地中,基于该数据集微调的模型可被部署于电商平台的在线客服系统、智能导购机器人及售后服务助手等模块。用户输入关于商品规格、退换货政策或物流状态的自然语言查询时,模型能够实时匹配FAQ知识库并给出精准回答,从而显著降低人工客服压力、缩短用户响应时间并提升客户满意度。此外,该数据集也可用于构建面向跨境电商业态的多语种问答系统。
数据集最近研究
最新研究方向
在电子商务领域,大规模语言模型的应用正逐渐成为提升客户服务效率与质量的关键技术。该数据集聚焦于电商常见问题解答场景,通过构建指令-上下文-响应对形式的高质量问答样本,为基于Llama2等开源大模型的客服机器人微调提供了精炼的训练素材。其研究前沿在于如何利用少量但高代表性的专家标注数据,实现大模型在垂直领域的快速适配与精准应答,从而在保证模型推理能力的同时,降低部署成本与延迟。这一方向与当下企业对智能化、自动化客服系统的迫切需求紧密相连,有望推动电商行业从传统人工客服向智能交互的范式转型,具有显著的商业价值与行业示范意义。
以上内容由遇见数据集搜集并总结生成


