LSD_AmpC_Liu_2025
收藏Hugging Face2025-05-01 更新2025-05-02 收录
下载链接:
https://huggingface.co/datasets/IrwinLab/LSD_AmpC_Liu_2025
下载链接
链接失效反馈官方服务:
资源简介:
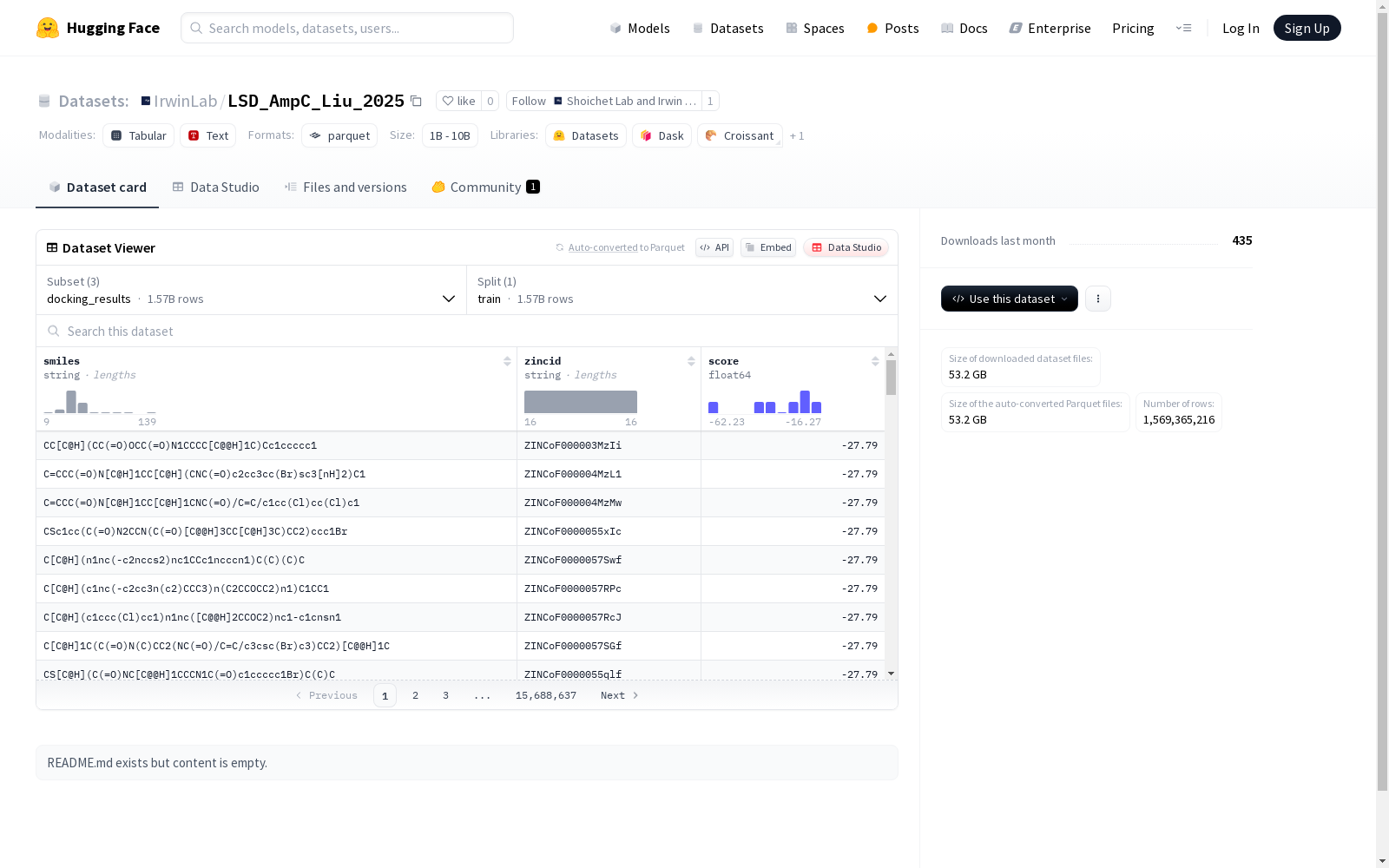
docking_results数据集包含化合物的SMILES和zincid,以及训练集的大小和示例数量。invitro_results数据集包含ZINC ID、Catalog ID和DOCK score等生物学数据,以及训练集的大小和示例数量。poses_top500k数据集包含分子的名称、SMILES、多种属性和排名信息,以及训练集的大小和示例数量。
创建时间:
2025-04-17
原始信息汇总
数据集概述
基本信息
- 数据集名称: LSD_AmpC_Liu_2025
- 数据集地址: https://huggingface.co/datasets/IrwinLab/LSD_AmpC_Liu_2025
数据集配置
1. docking_results
- 特征:
smiles: 字符串类型zincid: 字符串类型score: 浮点型
- 数据量:
- 训练集: 1,568,863,695 个样本
- 文件大小: 122,548,586,012 字节
- 下载大小: 52,313,006,119 字节
- 数据文件路径:
docking_results/train-*
2. invitro_results
- 特征:
ZINC ID: 字符串类型Catalog ID: 字符串类型DOCK score (kcal/mol): 浮点型Global rank: 整型Tc to knowns: 浮点型Ki (uM): 字符串类型SMILES: 字符串类型Picking method: 字符串类型
- 数据量:
- 训练集: 1,521 个样本
- 文件大小: 195,304 字节
- 下载大小: 94,613 字节
- 数据文件路径:
invitro_results/train-*
3. poses_top500k
- 特征:
Name: 字符串类型Protonation: 字符串类型SMILES: 字符串类型Long_Name: 字符串类型FlexRecCode: 浮点型Number: 浮点型Ligand_Source_File: 字符串类型Rank: 浮点型Setnum: 浮点型Matchnum: 浮点型OXR: 字符串类型OXS: 字符串类型Cloud: 浮点型Electrostatic: 浮点型Gist: 浮点型Van_der_Waals: 浮点型Ligand_Polar_Desolv: 浮点型Ligand_Apolar_Desolv: 浮点型Total_Strain: 浮点型Max_Strain: 浮点型Receptor_Desolvation: 浮点型Receptor_Hydrophobic: 浮点型Total_Energy: 浮点型Ligand_Charge: 浮点型Arbitrary: 浮点型Ligand_Energy: 浮点型mol_block: 字符串类型
- 数据量:
- 训练集: 500,000 个样本
- 文件大小: 2,017,556,247 字节
- 下载大小: 861,006,439 字节
- 数据文件路径:
poses_top500k/train-*
搜集汇总
数据集介绍
构建方式
LSD_AmpC_Liu_2025数据集通过分子对接技术和体外实验相结合的方式构建,涵盖了超过15亿个分子对接结果和1521个体外实验验证数据。数据集采用多配置结构组织,包含docking_results、invitro_results和poses_top500k三个子集,分别记录分子对接评分、体外活性数据和前50万对接构象的详细能量参数。数据采集过程严格遵循计算化学实验规范,确保每个分子特征的准确性和可追溯性。
使用方法
研究人员可通过HuggingFace平台直接加载数据集,三个子集分别对应不同的研究需求。docking_results适用于开发新型分子对接算法,invitro_results可用于构建QSAR预测模型,poses_top500k则适合分子动力学模拟和结合位点分析。每个子集均采用标准数据框格式存储,支持pandas等工具直接处理。对于特定研究目标,建议先筛选Global rank靠前的分子进行重点分析。
背景与挑战
背景概述
LSD_AmpC_Liu_2025数据集由研究团队于2025年构建,专注于药物发现领域的分子对接与体外活性测试。该数据集整合了大规模虚拟筛选结果与实验验证数据,旨在解决AmpC β-内酰胺酶抑制剂开发中的分子识别难题。其核心价值在于建立了计算化学评分与生物活性之间的映射关系,为计算机辅助药物设计领域提供了关键基准。数据集包含15亿余条分子对接记录及1500余条体外测试数据,通过多维度特征描述配体-受体相互作用机制,显著提升了耐药菌靶点药物开发的效率。
当前挑战
该数据集面临双重挑战:在科学层面,需解决分子对接评分函数与实验活性数据间的非线性关联问题,现有能量计算模型难以准确预测复杂溶剂化效应下的结合自由能。在技术层面,数据异构性处理构成主要障碍,包括对接软件输出格式标准化、体外测试中Ki值单位统一化,以及海量构象数据的存储优化。特别值得注意的是,柔性对接产生的500,000个分子构象涉及多维能量项整合,对特征工程的完备性提出了极高要求。
常用场景
经典使用场景
在药物发现领域,LSD_AmpC_Liu_2025数据集为分子对接研究提供了丰富的实验数据。该数据集通过记录大量小分子与AmpC β-内酰胺酶的相互作用信息,成为评估虚拟筛选算法性能的黄金标准。研究人员可以基于对接分数和体外活性数据,快速验证分子对接程序的准确性。
解决学术问题
该数据集有效解决了药物发现中分子对接评分函数优化的关键问题。通过提供包含1.5亿余次对接实验的详实数据,研究人员能够深入分析分子间相互作用能各分量的贡献度。特别是对于β-内酰胺酶抑制剂的开发,数据集中的Ki值和Tc相似性指标为构效关系研究提供了重要参考。
实际应用
在实际药物研发中,该数据集被广泛用于先导化合物优化阶段。制药企业通过分析Top50万构象的多种能量参数,可快速识别具有优化潜力的分子骨架。数据集包含的质子化状态和分子应变数据,尤其有助于解决类药性分子在结合口袋中的构象稳定性问题。
数据集最近研究
最新研究方向
在计算药物发现领域,LSD_AmpC_Liu_2025数据集凭借其海量分子对接数据和体外实验结果,正成为抗生素耐药性研究的重要资源。该数据集最新研究聚焦于机器学习驱动的β-内酰胺酶抑制剂设计,特别是针对AmpC酶的空间构象特征与能量参数进行深度挖掘。研究者们正尝试将分子动力学模拟与图神经网络相结合,通过分析500,000个高评分分子构象的静电分布和去溶剂化能等特征,建立多参数优化模型。近期《Nature Chemical Biology》刊文指出,此类数据集的应用显著加速了对抗碳青霉烯类耐药菌株的化合物筛选进程,其提供的立体构象能量分解指标为理解配体-受体相互作用提供了新的维度。
以上内容由遇见数据集搜集并总结生成


