MPEP_GREEK
收藏Hugging Face2024-06-21 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/DIBT/MPEP_GREEK
下载链接
链接失效反馈官方服务:
资源简介:
MPEP_GREEK数据集是通过Argilla工具创建的,包含符合Argilla数据集格式的配置文件`argilla.yaml`和与HuggingFace `datasets`兼容的记录。该数据集适用于多种NLP任务,支持文本字段和供标注者使用的各种类型问题,如翻译任务。数据集可通过Argilla或直接使用`datasets`库加载,不包含排行榜,且缺乏关于语言、数据精选理由、源数据、标注者、个人敏感信息、社会影响、偏见、限制、数据集管理者、许可、引用和贡献的详细信息。
提供机构:
Data Is Better Together
创建时间:
2024-06-21
原始信息汇总
数据集卡片 MPEP_GREEK
数据集描述
- 数据集概述:
- 该数据集包含一个符合 Argilla 数据集格式的配置文件
argilla.yaml。 - 数据集记录采用与 HuggingFace
datasets兼容的格式。 - 包含用于构建和整理数据集的标注指南。
- 该数据集包含一个符合 Argilla 数据集格式的配置文件
加载数据集
使用 Argilla 加载
python import argilla as rg
ds = rg.FeedbackDataset.from_huggingface("DIBT/MPEP_GREEK")
使用 datasets 库加载
python from datasets import load_dataset
ds = load_dataset("DIBT/MPEP_GREEK")
支持的任务和排行榜
- 支持的任务:
- 该数据集可用于不同的 NLP 任务,具体取决于配置。
- 排行榜:
- 该数据集没有关联的排行榜。
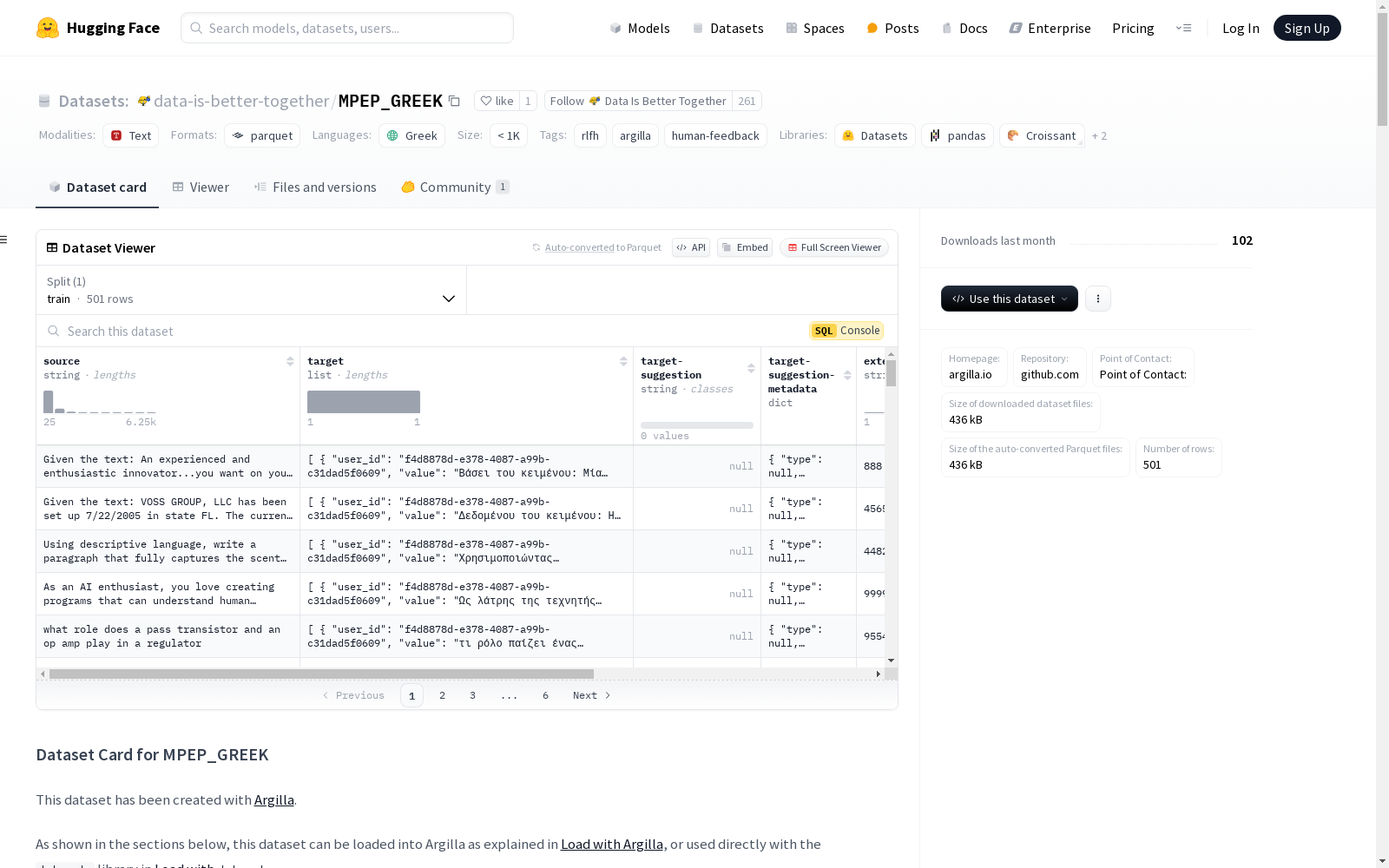
数据集结构
数据字段
- 字段:
source:类型为text。
- 问题:
target:类型为text,描述为“翻译文本”。
- 建议:
target-suggestion:类型为text(可选)。
- 元数据:
metadata:提供关于数据记录的额外信息(可选)。external_id:提供数据记录的外部 ID(可选)。
数据实例
- Argilla 格式: json { "external_id": "888", "fields": { "source": "Given the text: An experienced and enthusiastic innovator...you want on your team. Margaret Hines is the founder and Principal Consultant of Inspire Marketing, LLC, investing in local businesses, serving the community with business brokerage and marketing consulting. She has an undergraduate degree from Washington University in St. Louis, MO, and an MBA from the University of Wisconsin-Milwaukee. Margaret offers consulting in marketing, business sales and turnarounds and franchising. She is also an investor in local businesses. Prior to founding Inspire Marketing in 2003, Margaret gained her business acumen, sales and marketing expertise while working at respected Fortune 1000 companies. Summarize the background and expertise of Margaret Hines, the founder of Inspire Marketing." }, "metadata": { "evolved_from": null, "kind": "synthetic", "source": "ultrachat" }, "responses": [ { "status": "submitted", "user_id": "f4d8878d-e378-4087-a99b-c31dad5f0609", "values": { "target": { "value": "u0392u03acu03c3u03b5u03b9 u03c4u03bfu03c5 u03bau03b5u03b9u03bcu03adu03bdu03bfu03c5: u039cu03afu03b1 u03adu03bcu03c0u03b5u03b9u03c1u03b7 u03bau03b1u03b9 u03b5u03bdu03b8u03bfu03c5u03c3u03b9u03ceu03b4u03b7u03c2 u03bau03b1u03b9u03bdu03bfu03c4u03ccu03bcu03bfu03c2... u03c0u03bfu03c5 u03b8u03adu03bbu03b5u03c4u03b5 u03c3u03c4u03b7u03bd u03bfu03bcu03acu03b4u03b1 u03c3u03b1u03c2. u0397 Margaret Hines u03b5u03afu03bdu03b1u03b9 u03b7 u03b9u03b4u03c1u03cdu03c4u03c1u03b9u03b1 u03bau03b1u03b9 u03b7 u03bau03cdu03c1u03b9u03b1 u03c3u03cdu03bcu03b2u03bfu03c5u03bbu03bfu03c2 u03c4u03b7u03c2 Inspire Marketing, LLC, u03adu03c7u03bfu03bdu03c4u03b1u03c2 u03b5u03c0u03b5u03bdu03b4u03cdu03c3u03b5u03b9 u03c3u03b5 u03c4u03bfu03c0u03b9u03bau03adu03c2 u03b5u03c0u03b9u03c7u03b5u03b9u03c1u03aeu03c3u03b5u03b9u03c2, u03b5u03beu03c5u03c0u03b7u03c1u03b5u03c4u03ceu03bdu03c4u03b1u03c2 u03c4u03b7u03bd u03bau03bfu03b9u03bdu03ccu03c4u03b7u03c4u03b1 u03bcu03adu03c3u03c9 u03b5u03c0u03b9u03c7u03b5u03b9u03c1u03b7u03bcu03b1u03c4u03b9u03bau03aeu03c2 u03bcu03b5u03c3u03b9u03c4u03b5u03afu03b1u03c2 u03bau03b1u03b9 u03c3u03c5u03bcu03b2u03bfu03c5u03bbu03ceu03bd u03bcu03acu03c1u03bau03b5u03c4u03b9u03bdu03b3u03ba. u0388u03c7u03b5u03b9 u03c0u03c4u03c5u03c7u03afu03bf u03b1u03c0u03cc u03c4u03bf u03a0u03b1u03bdu03b5u03c0u03b9u03c3u03c4u03aeu03bcu03b9u03bf u03c4u03b7u03c2 u039fu03c5u03acu03c3u03b9u03b3u03bau03c4u03bfu03bd u03c3u03c4u03bf St. Louis, MO, u03bau03b1u03b9 MBA u03b1u03c0u03cc u03c4u03bf u03a0u03b1u03bdu03b5u03c0u03b9u03c3u03c4u03aeu03bcu03b9u03bf u03c4u03bfu03c5 Wisconsin-Milwaukee. u0397 Margaret u03c0u03c1u03bfu03c3u03c6u03adu03c1u03b5u03b9 u03c3u03c5u03bcu03b2u03bfu03c5u03bbu03adu03c2 u03c3u03b5 u03b8u03adu03bcu03b1u03c4u03b1 u03bcu03acu03c1u03bau03b5u03c4u03b9u03bdu03b3u03ba, u03b5u03c0u03b9u03c7u03b5u03b9u03c1u03b7u03bcu03b1u03c4u03b9u03bau03ceu03bd u03c0u03c9u03bbu03aeu03c3u03b5u03c9u03bd u03bau03b1u03b9 u03b1u03bdu03b1u03bau03b1u03c4u03b1u03c3u03bau03b5u03c5u03ceu03bd u03bau03b1u03b9 franchising. u0395u03afu03bdu03b1u03b9 u03b5u03c0u03afu03c3u03b7u03c2 u03b5u03c0u03b5u03bdu03b4u03cdu03c4u03c1u03b9u03b1 u03c3u03b5 u03c4u03bfu03c0u03b9u03bau03adu03c2 u03b5u03c0u03b9u03c7u03b5u03b9u03c1u03aeu03c3u03b5u03b9u03c2. u03a0u03c1u03b9u03bd u03b1u03c0u03cc u03c4u03b7u03bd u03afu03b4u03c1u03c5u03c3u03b7 u03c4u03b7u03c2 Inspire Marketing u03c4u03bf 2003, u03b7 Margaret u03b1u03c0u03adu03bau03c4u03b7u03c3u03b5 u03c4u03b7u03bd u03b5u03c0u03b9u03c7u03b5u03b9u03c1u03b7u03bcu03b1u03c4u03b9u03bau03ae u03c4u03b7u03c2 u03bfu03beu03c5u03b4u03adu03c1u03bau03b5u03b9u03b1, u03bau03b1u03b9 u03c4u03b7u03bd u03c4u03b5u03c7u03bdu03bfu03b3u03bdu03c9u03c3u03afu03b1 u03c4u03b7u03c2 u03c3u03c4u03b9u03c2 u03c0u03c9u03bbu03aeu03c3u03b5u03b9u03c2 u03bau03b1u03b9 u03c4u03bf u03bcu03acu03c1u03bau03b5u03c4u03b9u03bdu03b3u03ba u03ccu03c3u03bf u03b5u03c1u03b3u03b1u03b6u03ccu03c4u03b1u03bd u03c3u03b5 u03b1u03bdu03b1u03b3u03bdu03c9u03c1u03b9u03c3u03bcu03adu03bdu03b5u03c2 u03b5u03c4u03b1u03b9u03c1u03b5u03afu03b5u03c2 u03c4u03bfu03c5 Fortune 1000. u03a3u03c5u03bdu03ccu03c8u03b9u03c3u03b5 u03c4u03bf u03b9u03c3u03c4u03bfu03c1u03b9u03bau03cc u03bau03b1u03b9 u03c4u03b7u03bd u03c4u03b5u03c7u03bdu03bfu03b3u03bdu03c9u03c3u03afu0
搜集汇总
数据集介绍
构建方式
MPEP_GREEK数据集通过Argilla平台构建,结合了自动化工具与人工标注的双重优势。数据集的构建过程首先利用Google Translate进行初步翻译,随后由希腊语母语者进行精细校对与修正。为确保翻译质量,标注者在处理文本时保留了与希腊文化无关的内容,并对无法直接翻译的词汇进行了特殊处理。整个数据集以Argilla的格式存储,包含字段、问题、建议、元数据等结构化信息,便于后续的标注与分析。
使用方法
MPEP_GREEK数据集可通过Argilla平台或HuggingFace的`datasets`库加载。使用Argilla时,需安装Argilla并调用`FeedbackDataset.from_huggingface`方法加载数据集;使用`datasets`库时,则通过`load_dataset`函数直接加载。数据集支持多种任务配置,用户可根据需求调整字段与问题设置。此外,数据集的结构化设计便于与其他NLP工具集成,为文本翻译、语言模型训练等任务提供了便捷的数据支持。
背景与挑战
背景概述
MPEP_GREEK数据集是一个基于希腊语的翻译数据集,旨在通过人工反馈机制提升机器翻译的质量。该数据集由Argilla平台创建,主要用于支持自然语言处理(NLP)任务中的翻译任务。尽管数据集的具体创建时间和主要研究人员信息尚未公开,但其通过结合自动翻译工具(如Google Translate)与人工校对的方式,确保了翻译的准确性和自然性。该数据集的构建反映了当前NLP领域对高质量、多语言数据的需求,尤其是在低资源语言(如希腊语)的翻译任务中,具有重要的研究价值和应用潜力。
当前挑战
MPEP_GREEK数据集在构建和应用过程中面临多重挑战。首先,希腊语作为一种低资源语言,其翻译任务本身具有较高的复杂性,尤其是在处理文化特定表达和专业术语时,缺乏直接对应的翻译词汇。其次,数据集的构建依赖于自动翻译工具与人工校对的结合,这一过程可能导致翻译结果的不一致性,尤其是在处理长文本或复杂句式时。此外,数据集的规模较小(少于1000条记录),可能限制了其在训练大规模翻译模型时的有效性。最后,数据集的注释过程依赖于单一译者的校对,可能引入个人偏好或偏差,影响数据的多样性和泛化能力。
常用场景
经典使用场景
MPEP_GREEK数据集在自然语言处理领域中的经典使用场景主要集中于机器翻译任务。该数据集通过提供希腊语与英语之间的文本对,为研究人员和开发者提供了一个基准,用于训练和评估翻译模型。特别是在跨语言信息检索、多语言文本生成等任务中,MPEP_GREEK数据集能够帮助模型更好地理解和生成希腊语文本,从而提升翻译的准确性和流畅性。
解决学术问题
MPEP_GREEK数据集解决了机器翻译领域中的关键学术问题,特别是在低资源语言翻译方面。由于希腊语属于相对低资源的语言,现有的翻译模型往往难以处理其复杂的语法结构和丰富的词汇。该数据集通过提供高质量的希腊语-英语翻译对,填补了这一空白,使得研究人员能够开发出更精确的翻译模型,进而推动低资源语言翻译技术的发展。
实际应用
在实际应用中,MPEP_GREEK数据集可以广泛应用于跨语言信息检索、多语言内容生成以及全球化企业的本地化服务中。例如,跨国公司可以利用该数据集训练翻译模型,以自动生成希腊语的市场推广材料或客户支持文档。此外,该数据集还可用于开发多语言聊天机器人,帮助企业在希腊语市场提供更高效的客户服务。
数据集最近研究
最新研究方向
在自然语言处理领域,MPEP_GREEK数据集的引入为希腊语文本的机器翻译和语言模型训练提供了新的研究资源。随着多语言模型的需求日益增长,该数据集通过结合人类反馈与自动化工具(如Argilla),推动了希腊语翻译任务的高质量数据标注与模型优化。当前研究热点集中在如何利用该数据集提升低资源语言的翻译性能,特别是在跨文化语境下的语义准确性与流畅性。此外,该数据集还为研究人类与机器协作的标注流程提供了实验平台,进一步探索了人机交互在数据标注中的潜力与挑战。
以上内容由遇见数据集搜集并总结生成


